Medizintechnik-Entwicklung in der Praxis
KI im Medizinprodukt nutzen – wie geht das regulatorisch konform?
Künstliche Intelligenz und Maschinelles Lernen bietet für Medizinprodukte große Potenziale. Die Health Software muss aber von der FDA oder Benannten Stellen nach MDR zugelassen sein. Was genau ist regulatorisch zu berücksichtigen bei Medizingeräten mit KI-/ML-Technologie?
Bei KI-Anwendungen für Medizinprodukte handelt es oft um Health Software (SWMD, SaMD), aber diese Technologie wird auch zunehmend in Geräten und Systemen (Embedded SW) eingesetzt. Der Fachartikel zeigt die regulatorischen Anforderungen am Beispiel der Erweiterung eines QM-Systems und seiner Prozesse, zusätzlichen Aktivitäten in den Software-Lebenszyklusprozessen sowie bei der klinischen Bewertung und der Usability Evaluation.

Regulatorische Anforderungen an KI-/ML-basierte Medizinprodukte
Der EU AI Act steht kurz vor der Finalisierung, die US-FDA hat bereits Anfang 2021 einen »Artificial Intelligence and Machine Learning (AI/ML) Software as a Medical Device Action Plan« veröffentlich und die Benannten Stellen haben Ende 2023 die Version 5 ihres Questionnaire »Artificial Intelligence (AI) in medical devices« herausgegeben.
Es gibt eine Reihe von Normen zu künstlicher Intelligenz, die aber zum größten Teil medizintechnisch-unspezifisch sind:
- ISO/TR 24291:2021 - Health informatics, Applications of machine learning technologies in imaging and other medical applications
- ISO/IEC 23894:2023 - Information technology - Artificial intelligence, Guidance on risk management
- ISO/IEC TR 24027:2021 - Information technology - Artificial intelligence (AI), Bias in AI systems and AI aided decision making
- ISO/IEC TR 24028:2020 - Information technology - Artificial intelligence, Overview of trustworthiness in artificial intelligence
- ISO/IEC TR 29119-11:2020 - Software and systems engineering - Software testing, Part 11: Guidelines on the testing of AI-based systems
- ISO/IEC TR 24029-1:2021 - Artificial Intelligence (AI) – Assessment of the robustness of neural networks, Part 1: Overview
- ISO/IEC 24029-2:2023 - Artificial intelligence (AI) – Assessment of the robustness of neural networks, Part 2: Methodology for the use of formal methods
- ISO/IEC 8183:2023 - Information technology - Artificial intelligence, Data life cycle framework
- IEEE 2801-2022 - IEEE Recommended Practice for the Quality Management of Datasets for Medical Artificial Intelligence
Damit sind in naher Zukunft im EU- und US-Markt das Zulassungsverfahren sowie die regulatorischen Anforderungen an die Prozesse und die Medizinprodukte halbwegs beschrieben.
Notwendige Anpassungen am QM-System ...
... und seinen Prozessen. Zulassungsfähige Medizinprodukten müssen dem Stand der Technik entsprechen. Dies stellt eine Herausforderung dar, wenn sich dieser permanent im Hintergrund weiterentwickelt aufgrund sich schnell verändernder Technologien und dementsprechend hinterhereilenden regulatorischen Anforderungen.
Dementsprechend muss der Prozess zur Aktualisierung der regulatorischen Anforderungen von einem jährlichen Zyklus auf mindestens einen quartalsbasierten Zyklus umgestellt werden und u.a. die folgenden Datenquellen bzgl. Ermittlung des Standes der Technik berücksichtigen:
- Website der Europäischen Kommission zum Fortgang der europäischen AI-Gesetzgebung
- Website der FDA, Health Canada, der MHRA (UK) u.a. nationaler Behörden zu deren AI-Gesetzgebung (das sind die "Key Opinion Leader")
- Websites der Normenorganisationen ISO, IEC, IEEE zu Normen und Normentwürfen
- Website der Interessengemeinschaft der Notified Bodies (IG-NB) zu deren Positionierung
- Websites/Tools der Hersteller von KI-/ML-Technologie, bspw. Google AI
Im Qualitätsmanagementsystem müssen u.a. die folgenden Prozesse erweitert werden (siehe Bild 1):

- Software-Lebenszyklusprozesse
- Risikomanagement
- Usability Engineering
- Datenmanagement
- Verifizierung & Validierung
- Klinische Bewertung
- Anwenderinformation/-kommunikation über das User Interface und die IFU
- Installations-, Trainings-, Wartungs- und Service-Prozesse
- Post Market Surveillance.
Erweiterung der Software-Lebenszyklusprozesse
An der Qualität und damit dem Erfolg des Medizinproduktes mit KI-/ML-Technologie hat das Datenmanagement entscheidenden Anteil. Hierbei geht es um die Daten, die für das Training des KI-Modells, für dessen Evaluierung/Validierung sowie später für die Optimierung/das Tuning des KI-Models verwendet werden. Zu beachten ist, dass der EU AI Act Medizinprodukte als Hochrisiko-KI-Systeme ansieht.
Der Entwurf des europäischen AI Acts fordert in seinem Artikel 10:
(2) Für Trainings-, Validierungs- und Testdatensätze gelten geeignete Daten-Governance- und Datenverwaltungsverfahren. […]
(3) Die Trainings-, Validierungs- und Testdatensätze müssen relevant, repräsentativ, fehlerfrei und vollständig sein. Sie haben die geeigneten statistischen Merkmale, gegebenenfalls auch bezüglich der Personen oder Personengruppen, auf die das Hochrisiko-KI-System bestimmungsgemäß angewandt werden soll. […]
Zur Umsetzung dieser Anforderungen bedarf es Daten-Management-Experten, die in den meisten Unternehmen noch nicht vorhanden sind.
Der Software-Entwicklungsprozess nach EN 62304 muss um KI-Modell-bezogene Aktivitäten erweitert werden – siehe Bild 2.
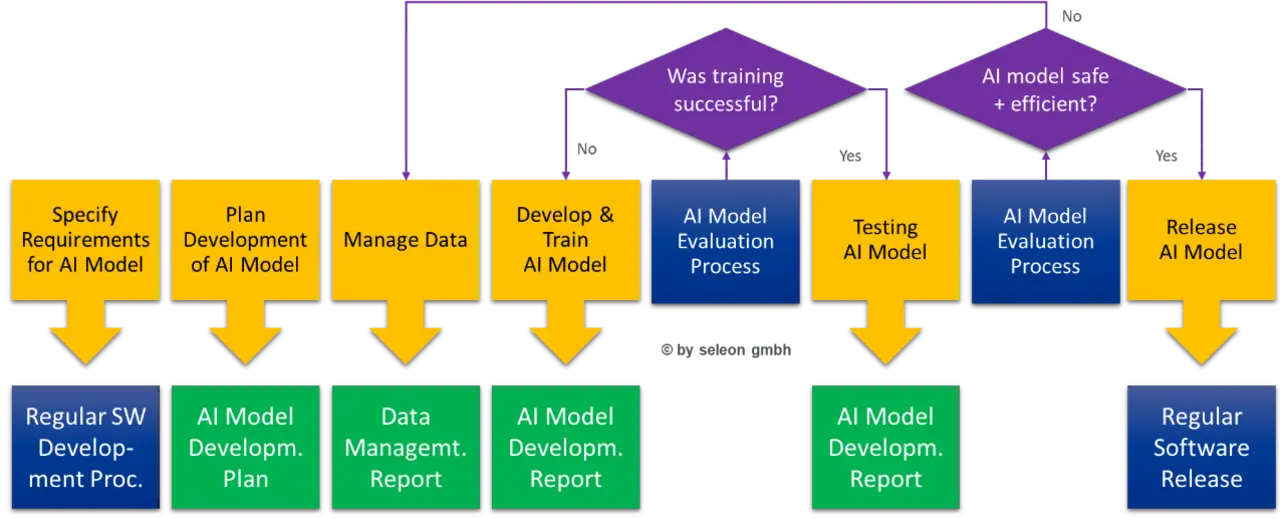
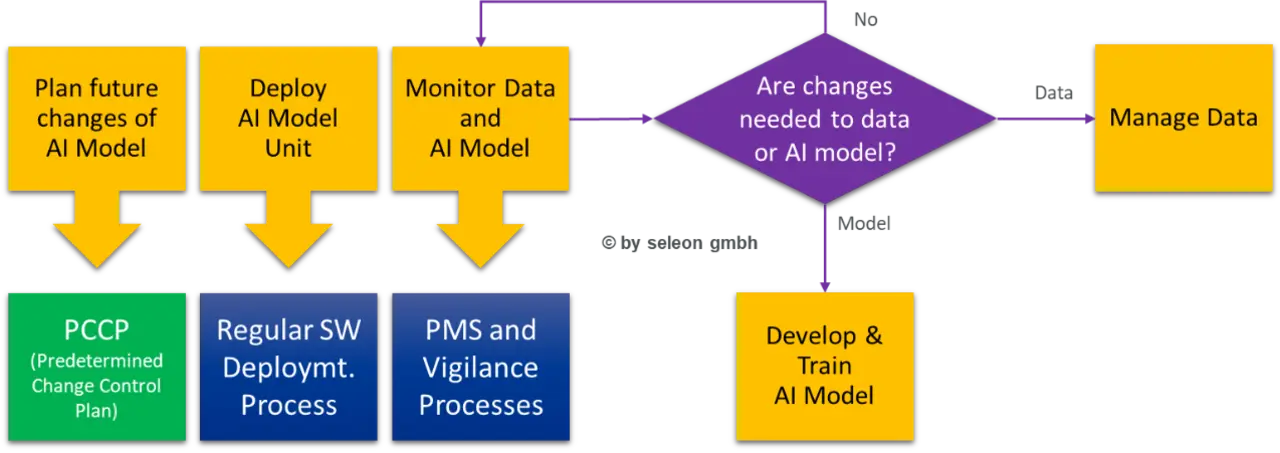
Auch der Software-Wartungsprozess muss entsprechend erweitert werden, um die Weiterentwicklung des KI-Modells regulatorisch sauber unterstützen zu können – siehe Bild 3.
Erweiterung des Usability Engineering
Die etwas versteckten Anforderungen der MDR an die Gebrauchstauglichkeit (Usability) müssen mit Blick auf das für den Anwender in der Regel intransparente Agieren des KI-Modells im Medizinprodukt entsprechend angepasst werden.
Dies umfasst u.a. die folgenden Anforderungen an die Usability von Medizinprodukten mit KI-/ML-Technologie:
| Kategorien | Anforderungen |
|---|---|
| Nutzungsumgebung | Gebrauchstauglichkeitstests in einer Umgebung, die die ursprüngliche klinische Arbeitsumgebung und die kognitive Arbeitsbelastung des Anwenders angemessen widerspiegelt |
| Workflow Management | Identifizierung von Anforderungen an den klinischen Workflow und Umsetzung in KI-basierte Software-Spezifikationen für medizinische Geräte |
| Nutzergruppe und Patientenpopulation | Spezifizierung der Anforderungen an die Eingabedaten für den Anwender sowie der Zielpatientenpopulation unter Berücksichtigung des Ausbildungsniveaus |
| Transparenz | Transparenz der Systemausgaben und Verständnis der Bedeutung durch den Anwender unter Berücksichtigung seines Ausbildungsstandes |
| Erklärbarkeit | Erklärbarkeit der Datenverarbeitung (Möglichkeiten und Grenzen) und Verständnis ihrer Bedeutung durch den Anwender unter Berücksichtigung seines Ausbildungsstandes |
| Automatisierten Verzerrungen (Bias) | Untersuchung des Vorhandenseins von automatisierten Verzerrungen (Automation Bias) |
| Fehlerbehandlung | Transparenz von Fehlermeldungen und Verständnis ihrer Bedeutung durch den Anwender unter Berücksichtigung seines Ausbildungsstandes |
| Fehlerbehandlung | Übergabe bspw. der Systembedienung an den Anwender, wenn das System seinen Zweck nicht erfüllen kann, z. B. aufgrund von Fehlfunktionen |
| Update Management | Informationen zu System-Updates (Modell oder Daten) mit Angaben zu Art, Grund und Auswirkungen auf die Leistung und Sicherheit des Anwenders unter Berücksichtigung seines Ausbildungsstandes |
Praktikable Hinweise geben auch die »Good Machine Learning Practice for Medical Device Development: Guiding Principles« der FDA, Health Canada und der MHRA (UK):
Der 1. Punkt dort fordert multidisziplinäres Fachwissen während des gesamten Produktlebenszyklus: Ein tiefgreifendes Verständnis der beabsichtigten Integration eines Modells in den klinischen Arbeitsablauf sowie des gewünschten Nutzens und der damit verbundenen Risiken für den Patienten kann dazu beitragen, dass ML-fähige medizinische Geräte sicher und wirksam sind und klinisch sinnvolle Anforderungen über den gesamten Lebenszyklus des Geräts erfüllen.
Der 7. Punkt legt den Schwerpunkt auf die Leistung des Mensch-KI-Teams: Überlegungen zu menschlichen Faktoren und zur menschlichen Interpretierbarkeit der Modellergebnisse werden am besten berücksichtigt, wenn das Modell einen »Menschen in der (Rückkopplungs-)Schleife« (»Human in the loop«) hat, wobei der Fokus mehr auf der Leistung des Mensch-KI-Teams liegen sollte, als auf der Leistung des Modells für sich genommen.
Der 9. Punkt adressiert die Anwender-Informationen: Den Anwendern werden klare, kontextbezogene Informationen zur Verfügung gestellt, die für die vorgesehene Zielgruppe (z. B. Leistungserbringer im Gesundheitswesen oder Patienten) geeignet sind. Dazu gehören der vorgesehene Verwendungszweck und die Indikationen für die Verwendung des Produkts, die Leistung des Modells für geeignete Untergruppen, die Merkmale der Daten, die zum Trainieren und Testen des Modells verwendet werden, akzeptable Eingaben, bekannte Einschränkungen, die Interpretation der Benutzeroberfläche und die Integration des Modells in den klinischen Arbeitsablauf. Die Anwender werden auch auf Geräteänderungen und Aktualisierungen aufgrund des Real-word Monitorings aufmerksam gemacht, auf die Grundlage für eine Entscheidungsfindung (Decision making) und die Möglichkeiten, dem Entwickler Bedenken zum Produkt mitteilen zu können.
Die Erweiterung des Usability Engineering Process ist in Bild 4 dargestellt.
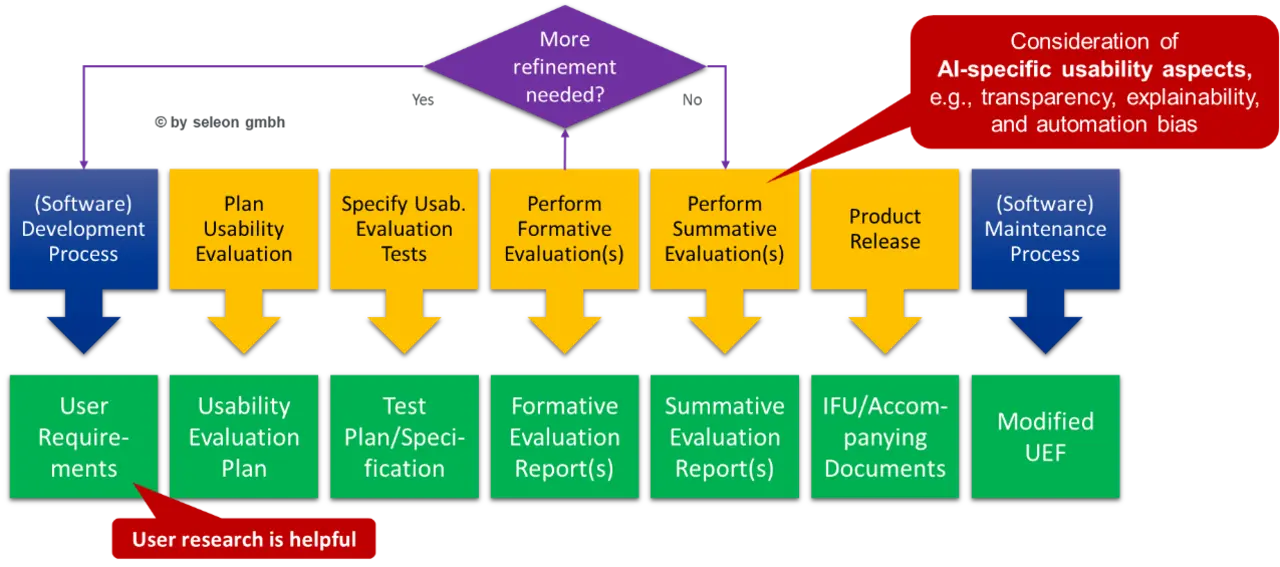
Erweiterung der klinischen Bewertung
In der Klinischen Bewertung muss der Hersteller (jederzeit) nachweisen (können),
- dass das Medizinprodukt die vorgesehene Leistung erbringt,
- für seine Zweckbestimmung geeignet ist,
- sicher und wirksam ist,
- den klinischen Zustand oder die Sicherheit/Gesundheit von Patienten, Anwendern oder anderen Personen nicht gefährdet und
- ein positives Nutzen-Risiko-Verhältnis aufweist.
Die gilt natürlich auch für Medizinprodukten mit KI-/ML-Technologie, bei denen die folgenden spezifischen Anforderungen zu berücksichtigen sind:
| Kategorien | Anforderungen | Dokumente |
|---|---|---|
| Stand der Wissenschaft und Technik auf dem jeweiligen medizinischen Gebiet | - Identifizierung der technischen SOTA in Bezug auf AI - Nachweis des klinischen Bezugs dazu sowie der wissenschaftlichen Validität | Plan zur klinischen Bewertung |
| Datenbank-Recherche | - Literatursuche in PubMed und ClinicalTrials.gov mit spezifischen medizinischen Fachbegriffen (MeSH), wie »Machine Learning«. | Plan für die Datenbankabfrage |
| Bewertungskriterien für den Beitrag der klinischen Daten zur klinischen Bewertung | - Analyse der Qualität von Literaturdaten zu klinischen Studien anhand der Kriterien von CONSORT-AI und SPIRIT-AI1 - Analyse der Qualität von Literaturdaten im Zusammenhang mit Studien zur diagnostischen Genauigkeit auf der Grundlage der Kriterien von STARD 2015 - Unabhängigkeit des Testdatensatzes vom Trainingsdatensatz (oder Information über Datensplitting) in Studien zur diagnostischen Genauigkeit - Verwendung eines externen Testdatensatzes zusätzlich zu einem internen Testdatensatz in Studien zur diagnostischen Genauigkeit, um die Generalisierbarkeit des Modells zu testen - Angemessenheit und nachvollziehbar korrekte Berechnung von Qualitätsmaßnahmen in klinischen Prüfungen und diagnostischen Genauigkeitsstudien | Bewertung der klinischen Daten |
| Anforderung an die Sicherheit und ein akzeptables Nutzen/Risiko-Profil | - Nachweis des angestrebten medizinischen Nutzens bei den festgelegten Werten der definierten Qualitätsmaßnahmen | Bericht zur klinischen Bewertung |
| Anforderung an die Leistung | - Vergleich des zu bewertenden Produkts mit klassischen klinischen Diagnose- oder Behandlungsverfahren (Der Nutzen von Systemen mit diagnostischem oder prädiktivem Zweck kann nur durch die Bewertung des gesamten Behandlungsprozesses beurteilt werden.[Referenzstandard] - Nachweis der technischen/analytischen Leistungsfähigkeit, siehe Abschnitt "4.3. Technical Performance /Analytical Performance" der Guideline MDCG 2020-1, anhand der Literaturanalyse müssen die erforderlichen Grenzwerte für die Qualitätsmaßnahmen in Bezug auf die bestimmungsgemäße Verwendung unter Berücksichtigung der SOTA ermittelt und dann mit den Ergebnissen des zu bewertenden Medizinprodukts verglichen werden. | Bericht zur klinischen Bewertung |
| Anforderung an die Sicherheit und ein akzeptables Nutzen/Risiko-Profil & Anforderung an die Leistung | - Prospektive, randomisierte, multizentrische Studie nach dem Stand der Technik, um die Verallgemeinerbarkeit zu bestätigen und die Verwendung über den vorgesehenen Zweck hinaus zu untersuchen | Bericht zur klinischen Bewertung |
| Anforderung an die Sicherheit und ein akzeptables Nutzen/Risiko-Profil & Anforderung an die Leistung | - Nachweis der klinischen Leistungsfähigkeit (Siehe Abschnitt "4.4. Clinical Performance" der Guideline MDCG 2020-1) - Diskriminierungsleistung (Wie gut kann der Algorithmus zwischen zwei Zuständen (z. B. gesund und krank) und anderen Krankheitsmanifestationen (d. h. Schweregrad der Krankheit, Stadium, Verteilung alternativer Diagnosen) unterscheiden? Wie häufig traten im Vergleich zu SOTA falsche Ergebnisse auf?) - Kalibrierungsleistung (Wie ähnlich sind die vorhergesagten und die tatsächlichen Wahrscheinlichkeiten?) - Klinische Akzeptanz (Wie oft haben die Nutzer die Ergebnisse akzeptiert und wie oft haben sie sie überschrieben?) | Bericht zur klinischen Bewertung |
Zusammenfassung: Was ist regulatorisch bei Medizinprodukten mit KI-/ML-Technologie zu berücksichtigen?
- Konformitätsbewertungsverfahren in der EU gemäß der MDR, IVDR und später dem EU AI Act und in den USA über die etablierten Zulassungsverfahren mit technologie-spezifischen Besonderheiten
- Alles wird komplexer, denn der Stand der Technik ändert sich täglich.
- Das Qualitätsmanagementsystem und seine Prozesse müssen für zusätzliche KI-/ML-Themen und Anforderungen erweitert werden.
- Themen der Datenverarbeitung sind sehr wichtig, insbesondere die Unabhängigkeit der Testdaten von den Trainingsdaten, qualifizierte Daten-Manager werden benötigt.
- Die Software-Lebenszyklusprozesse müssen um zusätzliche Aktivitäten erweitert und zusätzliche Dokumente erstellt werden.
- Usability Engineering muss KI-/ML-spezifische Aspekte berücksichtigen, z.B. Transparenz, Erklärbarkeit und Automatisierte Verzerrungen (Bias).
- Spezielle Anforderungen an Workflow Management, Patientenpopulation und Benutzergruppe müssen erfüllt werden.
- Die klinische Bewertung muss den KI-/ML-spezifischen Stand der Technik berücksichtigen und KI-/ML-spezifische Literatur berücksichtigen.
- Prospektive, randomisierte, multizentrische Studien auf dem neuesten Stand der Technik sind in der Regel eine Voraussetzung für eine erfolgreiche klinische Bewertung von Medizinprodukten mit KI/ML-Technologie, um die Verallgemeinerbarkeit zu bestätigen und die Verwendung über den vorgesehenen Zweck hinaus zu untersuchen.
- Statische KI kann auf dem »klassischen Weg« zugelassen werden, dynamische KI ist derzeit prinzipiell nicht zertifizierbar und statische Blackbox-KI kann durch eine Einzelfallentscheidung der Benannten Stelle zugelassen werden. (uh)