Vom Design bis zum Training
How to: KI für Medizinprodukte
KI prägt die Entwicklung neuer Medizinprodukte. Doch wie kann das Design und das Training der Medtech-KI aussehen? Im Projekt »IndiPlant« wurde ein KI-Modell für Patienten mit einem Aneurysma im Gehirn entwickelt. Die Medizinsoftwareentwickler von Bayoomed geben fachliche Einblicke.
Zum Vorteil von künstlicher Intelligenz in einem Medizinprodukt gehört, dass die KI Daten analysiert und verarbeitet, ohne dass die Art der Datenverarbeitung vorher durch einen Algorithmus festgelegt sein muss. Medizinische KI-Systeme können selbstständig Muster und Zusammenhänge in großen Datenmengen erkennen und darauf basierend Entscheidungen oder Vorhersagen treffen.
Der aktuelle KI-Erfolg – nicht nur in der Medizin – ist maßgeblich auf den sogenannten Transformator zurückzuführen. Diese KI-Architektur überführt die Eingabesequenzen durch einen »Aufmerksamkeits«-Mechanismus (Attention) in die Ausgabesequenzen eines gewünschten Zielformats. Die Ausgabesequenz wird dabei schrittweise generiert, während der Mechanismus den Bezug zum bisher erstellten Element sowie der gesamten Eingabesequenz gestattet. Der damit einhergehende erhöhte Rechenaufwand ist der Grund, warum der Bedarf an Grafikkarten des Herstellers Nvidia zuletzt stark anstieg.
Der große Vorteil der Transformatoren liegt darin, den Trainingsprozess und die Vorhersage zu parallelisieren. Diese Qualität und die wesentlich verbesserte Leistungsfähigkeit stellen bisherige Architekturen in den Schatten. So konnten sich Transformatoren auch in der visuellen Domäne ausbreiten (Visual Transformer), sodass beispielsweise aus Bildbeschreibungen neue Bilder generiert werden können, wie es Stable Diffusion im August 2022 demonstrierte. Kein Wunder, dass auch Forschungen in der Medizin von den neuen KI-Entwicklungen profitieren.
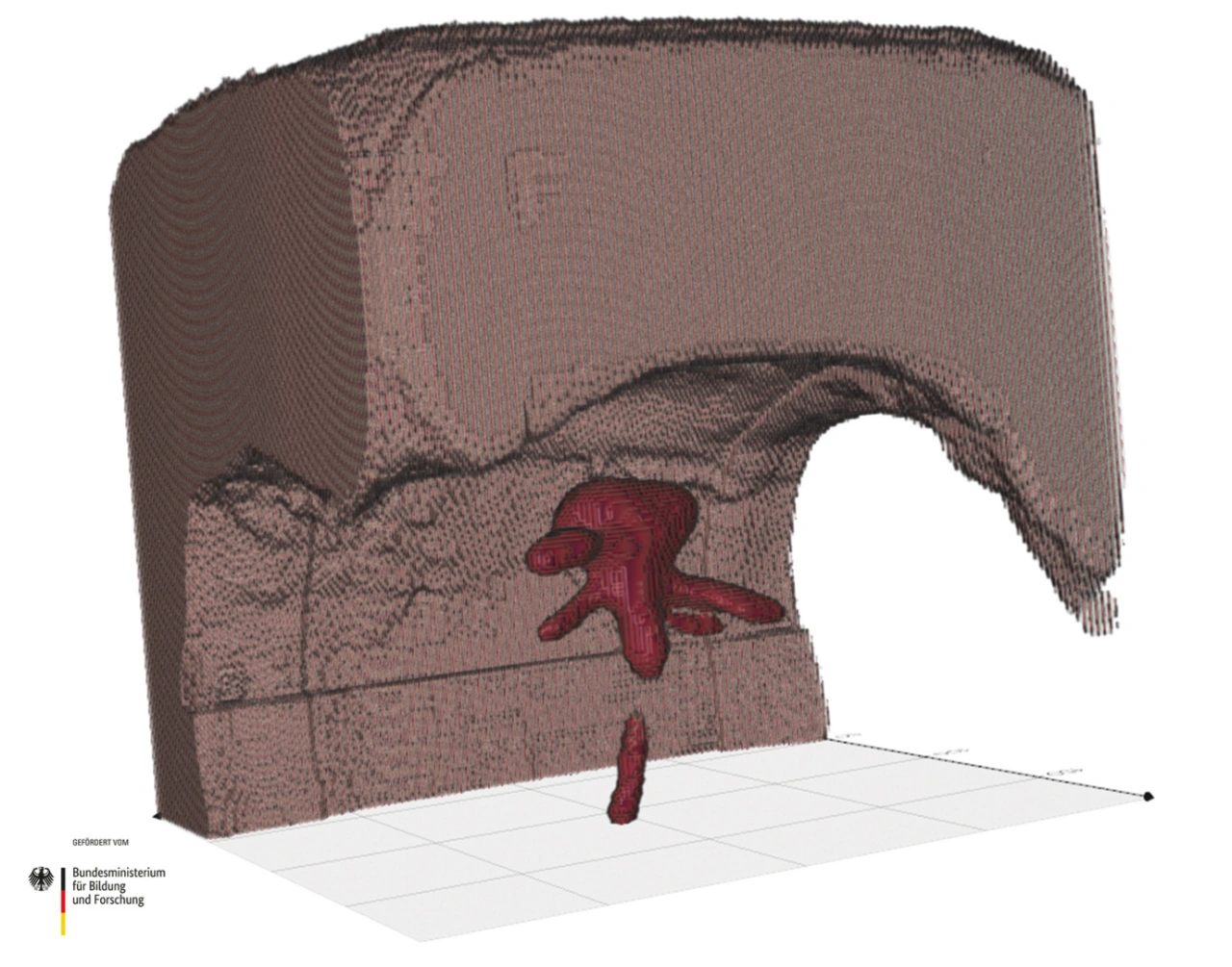
KI erstellt 3D-Stent aus CT-Bildern
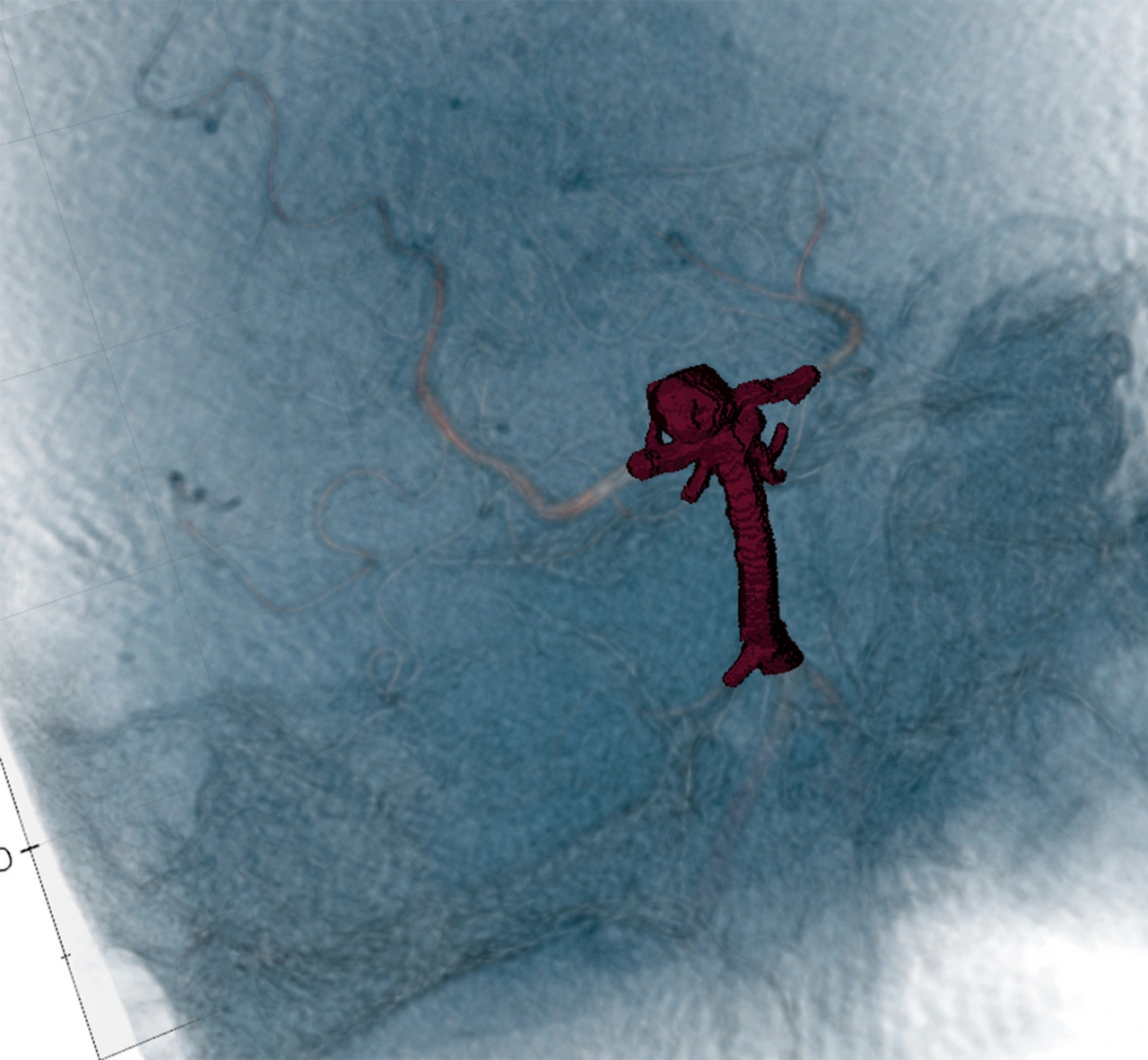
Für das vom Bundesministerium für Bildung und Forschung (BMBF) geförderte Projekt »IndiPlant« forschen die Medizinsoftwareentwickler von Bayoomed an der Möglichkeit, Patienten mit einem Aneurysma im Gehirn individuell zu behandeln. Dabei erstellt ein KI-Modell auf Basis von CT-Scans einen Stent, der anschließend durch Simulationen validiert und 3D-gedruckt wird. Für die Patienten wird die Qualität und der Erfolg seiner Therapie gesteigert – dies ist insbesondere für Indikationen wie Bifurkationsaneurysmen relevant, die durch ihr erhöhtes Rupturrisiko schnell zu lebensbedrohlichen Situationen führen können.
Das Bayoomed-Team verantwortet bei »IndiPlant« das Design und das Training, während Konsortialpartner die Simulation, den 3D-Druck sowie die technische und medizinische Expertise tragen.
Medtech-Entwicklung umdenken
Im Gegensatz zum Projektmanagement in der agilen Softwareentwicklung von Medizinprodukten ist die Entwicklung eines KI-Systems durch viele offene Fragen und Unklarheiten sowie starke Abhängigkeiten der einzelnen Arbeitspakete untereinander gekennzeichnet. Obwohl es einen roten Faden gibt, der die Richtung weist, besteht die Herausforderung darin, den Weg dorthin zu finden.
Das bedeutet: Die Planung eines KI-Projekts muss neu gedacht werden. Auf die initiale Erstellung eines Gesamt-Backlogs und einer Liste aller zu erledigenden Aufgaben hat Bayoomed verzichtet. Der Hauptgrund dafür war die vorherige Unplanbarkeit, welche Arbeitspakete wie umgesetzt werden müssen. Ein Arbeitspaket, das nur den Titel »Datenanalyse« oder »Training« trägt, jedoch keine genaueren Inhalte zur Vorgehensweise bei der Bearbeitung enthält, hatte für die Medtech-Entwickler keinen Mehrwert.
Wie aber solch ein Projekt planen? Für das Forschungsprojekt lag es für das Team von Bayoomed nahe, wie bei einer Forschungsarbeit vorzugehen: Recherche, Wissensaufbau, Analyse, Umsetzung und Evaluation. Im ersten Schritt führten die Softwarespezialisten eine umfangreiche Recherche zu aktuellen Arbeiten, Studien und Forschungspublikationen rund um die Themen Visual Transformer, Multi-Class Segmentation of DICOM Data sowie neuronale Netze für die medizinische Bildverarbeitung durch und trugen die Ergebnisse zusammen. Mit dieser Wissensbasis konnten Entscheidungen zur Technologie und dem weiteren Vorgehen getroffen werden – auch konnte die erste Version der KI-Pipeline als Basis für alle weiteren Aktivitäten aufgebaut werden.
Preprocessing
Ein wichtiger Faktor für die Qualität der Pipeline ist die Qualität der Daten, mit denen die KI trainiert wird. Sorgfältig aufbereitete Daten in ausreichendem Maße führen mit unterschiedlichen KI-Architekturen zu akzeptablen Ergebnissen, während eine geringe oder schlecht aufbereitete Trainingsdatenmenge niemals ein gutes Ergebnis liefern kann.
Der erste Schritt im Preprocessing ist die Homogenisierung der Dateneigenschaften, denn im Falle des »IndiPlant«-Projekts stammten die CT-Scans von unterschiedlichen Geräten mit verschiedenen Konfigurationen. Bildgröße, Auflösung und Ausrichtung galt es zu harmonisieren, damit sich die KI während des Trainings auf die wichtigen Faktoren zur Identifikation der Aneurysmen und Erstellung der Stents konzentrieren konnte.
DICOM zu NIFTI
Eine weitere, wichtige Erkenntnis in dieser Projektphase war die Umwandlung der DICOM-Daten in das NIFTI-Format und der damit einhergehenden Anonymisierung der Patientendaten. Dies erlaubte eine qualitativ hochwertigere Extraktion von Attributen aus den medizinischen Bilddaten und erleichterte den Trainingsvorgang. Denn NIFTI-Dateien bieten nicht nur eine bessere Handhabung der räumlichen Informationen, sondern auch eine effizientere Speichernutzung und schnelleren Zugriff auf die Bilddaten. Darüber hinaus setzen viele Programmierbibliotheken das NIFTI-Format schlicht voraus.
Neben der Homogenisierung und Konvertierung der Formate spielte die Datenannotation eine zentrale Rolle. Für eine präzise Erkennung und Behandlung von Aneurysmen mussten die Bilddaten sorgfältig annotiert werden. Experten markierten die genauen Positionen der Aneurysmen und die relevanten anatomischen Strukturen. Die präzisen Labels waren unerlässlich, um das KI-Modell korrekt zu trainieren und seine Leistungsfähigkeit zu maximieren. Gleichzeitig brauchte es für die erfolgreiche Augmentation eine angemessene Menge verwendbarer Daten.
Tipps für mehr Trainingsdaten
Durch Techniken wie Rotation, Skalierung und Spiegelung der Bilder konnte die Menge der verfügbaren Trainingsdaten künstlich erhöht werden. Die Erweiterung der Datenbasis half der KI, robuster und flexibler zu werden, da sie lernt, mit verschiedenen Variationen der Daten umzugehen. Diese Maßnahmen trugen entscheidend dazu bei, die Genauigkeit und Zuverlässigkeit des KI-Modells zu steigern.
Erstes Training der KI
Nachdem die Datenbasis zusammengetragen und die KI-Pipeline konstruiert war, stand dem Testbeginn zum Training der künstlichen Intelligenz nichts entgegen. Für einen ersten Test verwendete Bayoomed eine kleine Datenmenge, um vorab die Funktionsfähigkeit der Pipeline zu testen sowie bislang unbekannte Fehler zu identifizieren. Ein erstes Training mit einer großen Datenmenge durchzuführen, kann zum Stolperstein in dieser Projektphase werden: Immerhin beträgt die Trainingszeit mehrere Tage oder Wochen; mit dem Risiko aufgrund ungesehener Fehler schließlich kein Ergebnis zu erhalten.
Start mit kleiner Datenmenge
Die Erfahrung der Darmstädter Softwareentwickler zeigt, dass ein erstes Trainingsset aus etwa zehn Datenpunkten bestehen kann, wovon sieben für das Training und drei für die Validierung verwendet werden sollten. Dieser Aufbau wird keine akzeptablen Ergebnisse für die KI liefern, erlaubt es jedoch, Fehler im Ablauf der gesamten Pipeline zu identifizieren. Fehler können schneller behoben und die Pipeline bereits zu einem frühen Zeitpunkt in der Entwicklung optimiert werden. Parallel kann am Aufbau und der Vorbereitung einer größeren Trainingsdatenmenge für einen weiteren Durchgang gearbeitet werden.
Variation gegen Overfitting
Das Ziel eines zweiten Trainings mit einer größeren Datenmenge ist die Identifikation von Problemen innerhalb des Trainingsprozesses. Eine zu kleine Datenbasis sorgt für ein Overfitting des trainierten KI-Modells. Dabei fokussiert sich das Modell zu sehr auf die Trainingsdaten. Es kommt zum Auswendiglernen der Daten, weshalb sehr gute Ergebnisse für die Trainingsdaten beobachtet werden können. Die Qualität der Transformationen für unbekannte Daten ist jedoch deutlich schlechter. Um diese Problematik zu beheben, kann entweder eine größere Datenmenge mit mehr Variation in den Trainingsdaten oder/und eine stärkere Rotation in der Trainings- und Testmenge dienlich sein.
Anschließend erfolgt ein dritter Trainingsvorgang mit der gesamten Datenbasis. Ziel ist es nun, die erste richtige Version des KI-Modells zu trainieren.

Lessons Learned
Zu den wichtigsten Projekterfahrungen der KI-Entwicklung für den personalisierten 3D-Druck eines Stents gegen Bifurkationsaneurysmen zählen für das Bayoomed-Team:
Korrekte DICOM-Extraktion
Das DICOM-Format enthält eine große Informationsmenge. Ziel des Preprocessings und des Trainings muss es sein, diese Informationen zu extrahieren und durch das Preprocessing nicht zu verfälschen oder gar zu verlieren. Modifikationen der Trainingsdaten sollten entsprechend wohlüberlegt und ihr Einfluss auf den Trainingsvorgang der KI genau betrachtet werden. Die Herausforderung besteht somit darin, diese wichtigen Daten aus der Vielzahl der in DICOM enthaltenen Informationen effizient und präzise zu extrahieren.
Genaue NIFTI-Homogenisierung
Um die extrahierten Informationen für maschinelles Lernen nutzbar zu machen, müssen sie in Formate überführt sein, die von KI-Modellen verarbeitet werden können. Ein gängiges Format hierfür ist NIFTI. Die Transformation der DICOM-Daten in das NIFTI-Format und die Homogenisierung der Daten ist jedoch nicht trivial. Es bedarf einer genauen Anpassung und Kalibrierung, um die räumlichen und anatomischen Informationen korrekt zu übertragen und für das KI-Modell nutzbar zu machen. Die Transformation erfordert eine sorgfältige Handhabung der Datenintegrität. Dabei müssen die Bildqualität, die Auflösung und die räumlichen Beziehungen zwischen den Bildern erhalten bleiben. So wird sichergestellt, dass die KI-Modelle auf konsistente und qualitativ hochwertige Daten zugreifen können.
Sowohl DICOM- als auch NIFTI-Dateien enthalten räumliche und anatomische Informationen, die für eine korrekte Interpretation der Bilddaten entscheidend sind. Ein tiefes Verständnis für diese Merkmale ist notwendig, um die Daten korrekt zu homogenisieren. Unterschiede in der Bildausrichtung und -skalierung zwischen verschiedenen DICOM-Datensätzen müssen angepasst werden, um eine konsistente Datenbasis für das Training und die Anwendung der KI zu gewährleisten.
Anatomisch präzise Trainingsdaten
Die eigentliche Segmentierung des Aneurysmas und die Planung des Stents erfordern präzise Algorithmen, die anatomische Strukturen genau erkennen und abbilden können. Das setzt voraus, dass die KI-Modelle mit hochqualitativen, annotierten Datensätzen trainiert werden, um die feinen Details und Variationen in den anatomischen Strukturen korrekt zu erfassen.
Der Weg in die klinische Praxis
Bei Artikelerstellung befand sich das Projekt in der Durchführung und Optimierung des zweiten Trainingsdurchganges. Durch Optimierung des Preprozessings, u. a. durch die Filterung von Störinformationen und der gestiegenen Qualität bei der manuellen Segmentierung, konnte nach den ersten Testdurchläufen eine Steigerung der Modellqualität von 67 Prozent auf 86 Prozent Accuracy festgestellt werden. Gleichzeitig soll das KI-Modell in seiner Version 1.0 für die Segmentierung der Aneurysmen im Winter 2024 fertiggestellt sein. Parallel beginnen die Vorbereitungen für die ersten Versuche zur Erzeugung der Stents innerhalb der segmentierten Aneurysmen durch einen Visual Transformer. Hierzu wurden bereits erste Konstruktionsdesigns für den Stent festgelegt und in den ersten Trainingsdaten der Aneurysmen platziert. (uh)
