Radar-Video-Sensor-Fusion
So funktioniert fortschrittliche Fußgängererkennung
Für leistungsfähigere Fahrerassistenzdienste untersuchen Industrie und Wissenschaft das Potenzial von Sensortechnologien wie Video, Ultraschall, Radar und Lidar. Da kein System alle Szenarien abdecken kann, wird die nächste ADAS-Generation auf einer Kombination verschiedener Technologien beruhen.
Die Fähigkeit zukünftiger Autos, Verkehrsteilnehmer und Hindernisse schnell und genau zu erkennen, wird entscheidend dazu beitragen, die Zahl der Verkehrstoten zu senken. Es gibt jedoch keinen Sensor der alle Anforderungen, Szenarien und Verkehrs-/Wetterbedingungen abdeckt. Kameras funktionieren nicht gut bei Nacht oder bei grellem Sonnenlicht, und Radar kann durch reflektierende Metallgegenstände verwirrt werden.
Kombiniert man jedoch die jeweiligen Stärken und Schwächen, ergänzen sie sich perfekt. Hier kommt die Sensorfusion ins Spiel. Sie ermöglicht ein verbessertes Wahrnehmungsmodell (3D) der Umgebung eines Fahrzeugs unter Verwendung einer Vielzahl von sensorischen Informationen. Auf der Grundlage dieser Informationen und mit Hilfe von Deep-Learning-Ansätzen werden die erkannten Objekte in Kategorien eingeteilt, zum Beispiel Autos, Fußgänger, Radfahrer, Gebäude oder Gehwege usw. Das bildet dann die Grundlage für die Entscheidungen des intelligenten Fahrens und des Kollisionsschutzes von ADAS.
Verbund von Radar- und Videosensoren: das neue Konzept für die Zukunft
Die heute am weitesten verbreitete Art der Sensorfusion wird als nachträgliche Fusion bezeichnet. Dabei werden Sensordaten erst zusammengeführt, nachdem jeder Sensor eine Objekterkennung durchgeführt und seine eigenen »Entscheidungen« auf der Grundlage seiner eigenen, begrenzten Datensammlung getroffen hat. Das hat den Nachteil, dass jeder Sensor die Daten verwirft, die er für irrelevant hält. Dadurch geht viel Potenzial für die Sensorfusion verloren.
Im Gegensatz dazu kombiniert die vorgezogene Fusion (oder Low-Level-Datenfusion) alle Low-Level-Daten sämtlicher Sensoren in einem System. Dies erfordert jedoch eine hohe Rechenleistung und Verbindungen mit hoher Bandbreite von jedem Sensor zur zentralen Verarbeitungseinheit des Systems.
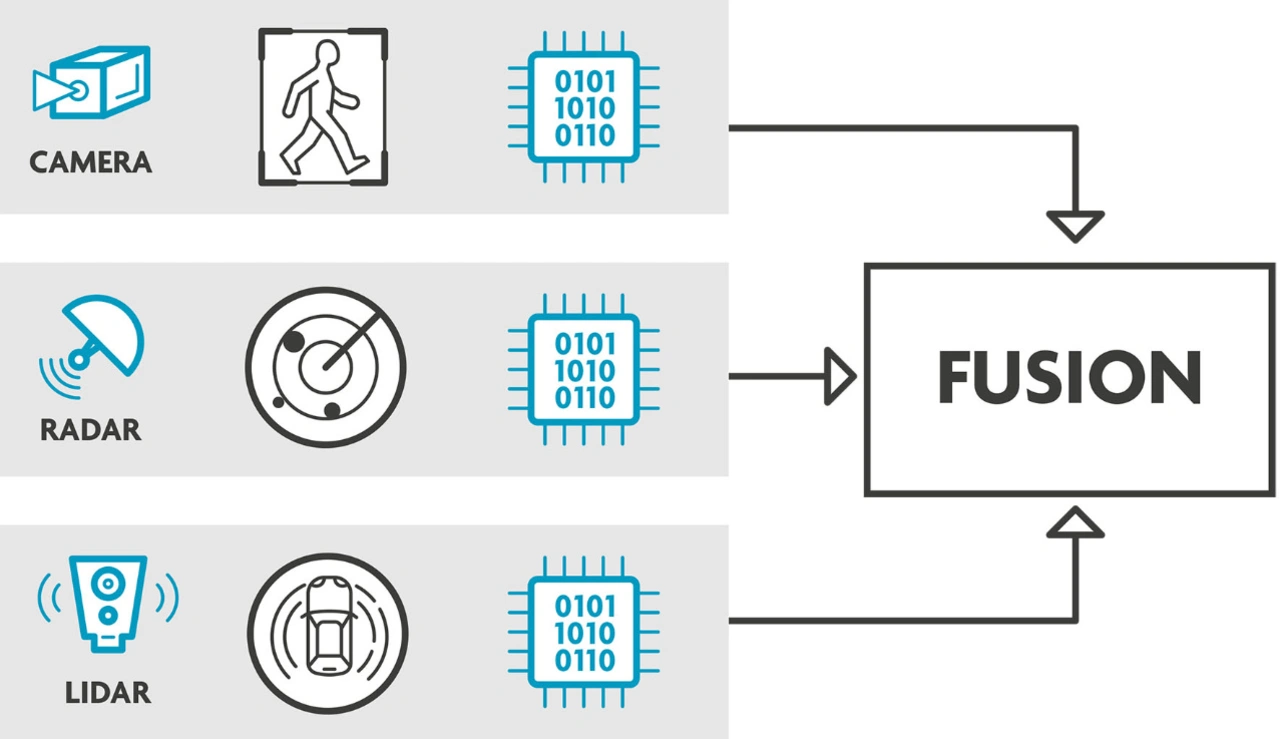
Als Antwort auf diese Schwachstellen haben Forscher des IPI, einer Imec-Forschungsgruppe an der Universität Gent, Belgien, das Konzept der kooperativen Radar-Videosensor-Fusion entwickelt. Es besteht aus einer Rückkopplungsschleife, in der verschiedene Sensoren Informationen auf niedriger oder mittlerer Ebene austauschen, um die Datenverarbeitung des jeweils anderen zu beeinflussen. Wenn beispielsweise das Radarsystem eines Fahrzeugs plötzlich eine starke Reflexion erfährt, wird der Schwellenwert der Bordkameras automatisch angepasst, um dies zu kompensieren. Auf diese Weise wird ein Fußgänger, der sonst nur schwer zu erkennen wäre, tatsächlich entdeckt, ohne dass das System überempfindlich wird und es zu Fehlalarmen kommt.
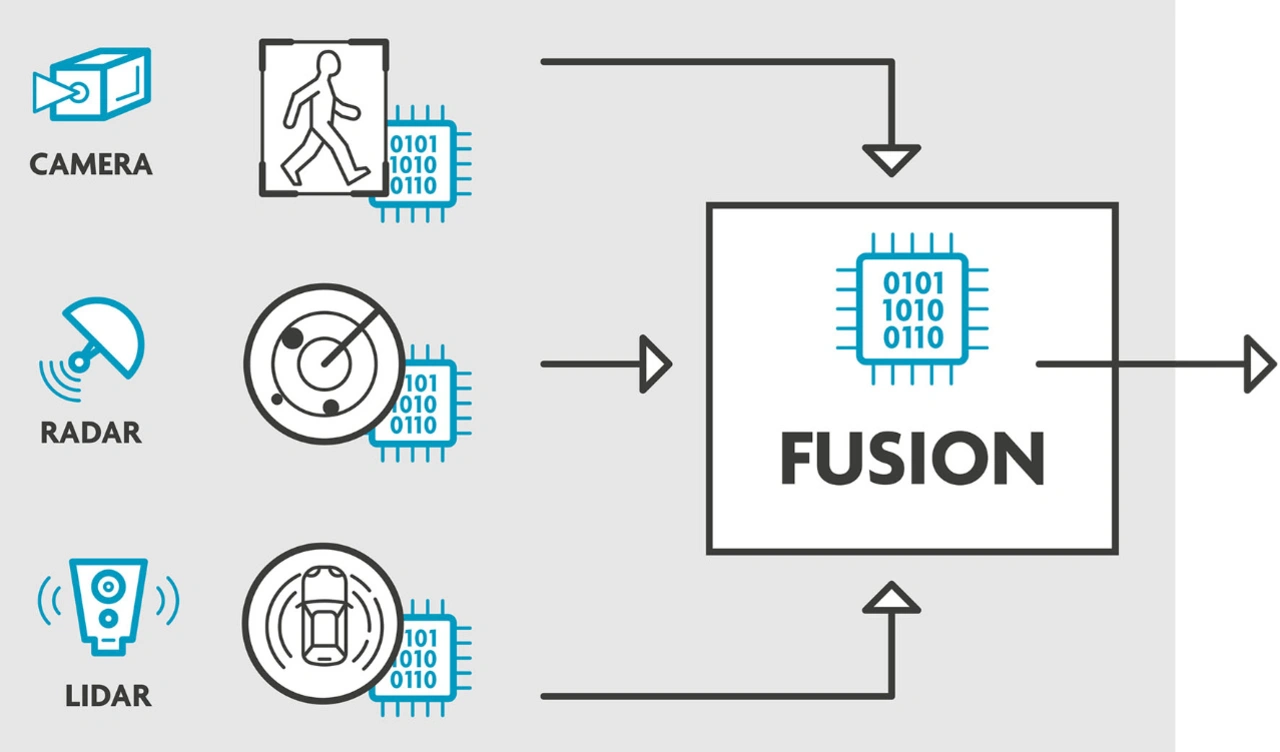
Genauigkeitsverbesserung gegenüber Late Fusion
Vergangenes Jahr haben die IPI-Forscher gezeigt, dass ihr kooperativer Sensorfusionsansatz die heute übliche Late-Fusion-Methode übertrifft. Darüber hinaus ist sie einfacher zu implementieren als die frühe Fusion, da sie nicht mit denselben Bandbreitenproblemen und Implementierungsbeschränkungen einhergeht. Bei der Auswertung eines Datensatzes komplexer Verkehrsszenarien in einem europäischen Stadtzentrum konnten die Forscher Fußgänger und Radfahrer um 20 % genauer verfolgen als ein reines Kamerasystem. Darüber hinaus übertraf ihr erstes Erkennungsmoment konkurrierende Ansätze um eine Viertelsekunde.
»In den letzten Monaten haben wir unser System weiter verfeinert und die Genauigkeit der Fußgängererkennung noch weiter verbessert, insbesondere unter schwierigen Verkehrs- und Wetterbedingungen«, erklärt David Van Hamme, leitender Forscher am IPI. »Bei einfachen Szenarien – das heißt tagsüber, ohne Verdeckungen und bei nicht allzu komplexen Szenen – bietet unser Ansatz jetzt eine um 41 % höhere Genauigkeit als reine Kamerasysteme und eine um 3 % höhere Genauigkeit als Late Fusion.«
»Aber vielleicht noch wichtiger sind die Fortschritte, die wir bei schlechter Beleuchtung, Fußgängern, die aus verdeckten Bereichen kommen, überfüllten Szenen usw. gemacht haben. Dies sind schließlich die Fälle, in denen Fußgängererkennungssysteme ihren Wert wirklich unter Beweis stellen müssen. Unter solch schwierigen Bedingungen sind die Vorteile der kooperativen Radar-Video-Sensorfusion noch beeindruckender, da sie eine 15-prozentige Verbesserung gegenüber der späten Fusion darstellt«, fügt Van Hamme hinzu.
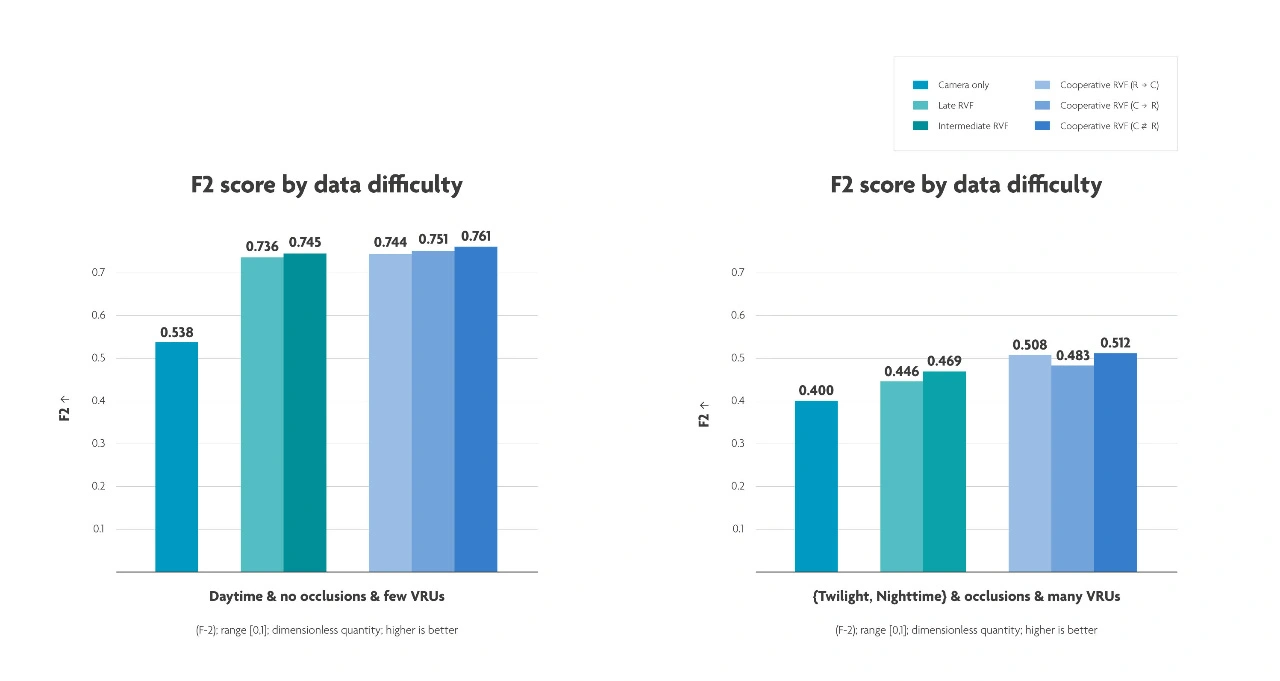
»Auch bei der Minimierung der Latenz, also der Verzögerung bei der Verfolgung, haben wir große Fortschritte gemacht. Bei schwierigen Wetter- und Verkehrsbedingungen erreichen wir jetzt beispielsweise eine Latenz von 411 ms. Das ist eine Verbesserung um mehr als 40 % gegenüber der Latenz, die bei reinen Kamerasystemen (725 ms) und bei der Late Fusion (696 ms) auftritt.«
Auf der Jagd nach weiteren Durchbrüchen
»Wir sind absolute Vorreiter, was die Identifizierung gefährdeter Verkehrsteilnehmer mit kombinierten Radar- und Videosystemen angeht. Die von uns vorgestellten Ergebnisse zeigen, dass unser Ansatz ein großes Potenzial hat. Wir sind der Ansicht, dass er ein ernstzunehmender Konkurrent für die heutige Fußgängererkennungstechnologie werden kann, die meist auf komplexere, umständlichere und teurere Lidar-Lösungen zurückgreift«, so David Van Hamme.
»Und wir erwarten noch weitere Durchbrüche in diesem Bereich. Einer davon ist die Ausweitung unseres Ansatzes der kooperativen Radar-Video-Sensorfusion auf andere Fälle, wie etwa die Fahrzeugerkennung. Die Entwicklung intelligenter Systeme, die mit plötzlichen Defekten oder Fehlfunktionen umgehen können, ist ein weiteres Thema, mit dem wir uns befassen möchten. Und schließlich wollen wir auch bei der Fortentwicklung der zugrunde liegenden neuronalen Netze einige Durchbrüche erzielen.«
»Denn ein konkretes Manko der heutigen KI-Systeme ist, dass sie darauf trainiert sind, möglichst viele gefährdete Verkehrsteilnehmer zu erkennen. Wir sind jedoch der Meinung, dass dies nicht der beste Ansatz ist, um die Zahl der Verkehrstoten zu verringern. Ist es wirklich zwingend erforderlich, den einen Fußgänger zu erkennen, der fünfzig Meter vor Ihrem Auto die Straße bereits überquert hat? Wir glauben nicht. Stattdessen sind diese Rechenressourcen an anderer Stelle besser aufgehoben. Die Umsetzung dieser Idee in ein neuronales Netz, das die Erkennung von gefährdeten Verkehrsteilnehmern in der Trajektorie eines Autos priorisiert, ist eines der Forschungsthemen, die wir zusammen mit einem oder mehreren kommerziellen Partnern angehen möchten«, schließt Van Hamme.
Automatisches Tone Mapping für die Bildverarbeitung im Kfz-Bereich
Wie erörtert, ist die Kameratechnologie ein Eckpfeiler der heutigen ADAS-Systeme. Aber auch sie hat ihre Unzulänglichkeiten. Kameras, die auf sichtbarem Licht basieren, sind beispielsweise nachts oder bei widrigen Witterungsbedingungen (starker Regen, Schnee usw.) nicht besonders leistungsfähig. Außerdem haben herkömmliche Kameras einen begrenzten Dynamikbereich, was in der Regel zu einem Kontrastverlust in Szenen mit schwierigen Lichtverhältnissen führt.
Sicherlich lassen sich einige dieser Einschränkungen durch die Ausstattung von Fahrzeugen mit HDR-Kameras (High Dynamic Range) ausgleichen. Aber HDR-Kameras machen die Signalverarbeitung komplexer, da sie Videoströme mit hoher Bitrate erzeugen, die die zugrunde liegenden KI-Engines von ADAS überfordern könnten.
Die IPI-Forscher vom imec und der Universität Gent haben das Beste aus beiden Welten kombiniert und ein automatisches Tone Mapping entwickelt - einen intelligenten Rechenprozess, der HDR-Bilder mit hoher Bitrate in Bilder mit niedriger Bitrate und geringem Dynamikbereich (LDR) umwandelt, ohne dass dabei Informationen verloren gehen, die für die Wahrnehmung im Auto entscheidend sind.
Datenverlust bedeutet nicht (notwendigerweise) Informationsverlust

»Tone Mapping gibt es schon länger, eine generische Variante wird in den heutigen Smartphones verwendet. Aber die Anwendung von Tone Mapping auf den Anwendungsfall Automotive und insbesondere die Fußgängererkennung erfordert ganz neue Überlegungen und Abwägungen. Es stellt sich die Frage, welche Daten erhalten bleiben müssen und welche Daten verworfen werden können, ohne das Leben von Menschen zu gefährden. Das ist die spezielle Aufgabe, mit der wir uns befasst haben«, meint Jan Aeltermann, Professor am IPI.
Das Ergebnis der Analyse ist in Bild 5 zu sehen. Es besteht aus vier Szenen, die mit einer HDR-Kamera aufgenommen wurden. Die Bilder auf der linken Seite wurden mit einer bestehenden Software tongemappt, während die Bilder auf der rechten Seite mit dem neuartigen CNN-Ansatz (Convolutional Neural Network) der Forscher zusammengestellt wurden.
»Wenn Sie das Bild unten links betrachten, sehen Sie, dass die Scheinwerfer des Autos sehr detailliert dargestellt sind. Das hat aber zur Folge, dass man keine anderen Formen erkennen kann«, sagt Jan Aelterman. »Auf dem Bild unten rechts sind die Details der Scheinwerfer zwar verloren gegangen, aber ein Fußgänger ist zu erkennen. Dies ist ein perfektes Beispiel dafür, was unser automatischer Tone-Mapping-Ansatz leisten kann. Unter Verwendung eines Kfz-Datensatzes wird das zugrundeliegende neuronale Netz darauf trainiert, nach Bilddetails auf niedriger Ebene zu suchen, die für die Wahrnehmung von Fahrzeugen wahrscheinlich relevant sind, und Daten zu verwerfen, die als irrelevant angesehen werden. Mit anderen Worten: Einige Daten gehen verloren, aber wir behalten alle wichtigen Informationen über die Anwesenheit gefährdeter Verkehrsteilnehmer«, fügt er hinzu.
»Ein weiterer Vorteil unseres auf neuronalen Netzen basierenden Ansatzes besteht darin, dass auch verschiedene andere Funktionen integriert werden können – wie beispielsweise Algorithmen zur Rauschunterdrückung oder zum Debayering und schließlich sogar Algorithmen zur Entfernung von Artefakten, die durch störende Wetterbedingungen (wie starken Nebel oder Regen) verursacht wurden.«
Natürliche Darstellung von Tone-Mapping-Bildern
Lebensrettende Informationen in einem Bild zu erhalten ist eine Sache. Aber es ist auch wichtig, diese Informationen auf natürliche Art und Weise darzustellen. Dies ist ein weiterer Aspekt, den die Forscher berücksichtigt haben.
Generische Tone-Mapping-Bilder sehen manchmal sehr merkwürdig aus. Ein Fußgänger könnte heller als die Sonne dargestellt werden, um Radfahrer könnten Lichthöfe entstehen, und die Farben könnten auf unnatürliche, fluoreszierende Werte angehoben werden. Für eine KI-Engine spielen solche Artefakte kaum eine Rolle. Aber auch menschliche Fahrer sollten in der Lage sein, Entscheidungen auf der Grundlage von Tone-Mapping-Bildern zu treffen. Zum Beispiel, wenn Bilder in die digitale Rückfahrkamera oder die Seitenspiegel eines Autos integriert werden..
Die visuellen Verbesserungen, die das automatische Ton-Mapping mit sich bringt, sind offensichtlich. Aber bedeutet es auch messbare Verbesserungen?
»Auf jeden Fall«, bestätigt Jan Aelterman. »Die Zahl der Fußgänger, die unerkannt bleiben, sinkt um 30 % – im Vergleich zur Verwendung einer SDR-Kamera. Und wir übertreffen die in der Literatur beschriebenen Tone-Mapping-Ansätze ebenfalls um 10 %. Auf den ersten Blick mag das nicht viel erscheinen, aber in der Praxis stellt jeder Fußgänger, der unerkannt vorbeigeht, ein ernsthaftes Risiko dar.«
»Wir untersuchen derzeit die Integration des automatischen Tone Mapping in die Forschungspipeline unserer Gruppe zur Sensorfusion. Schließlich handelt es sich hierbei um zwei sich perfekt ergänzende Technologien, die wesentlich leistungsfähigere Fußgängererkennungssysteme ermöglichen«, resümiert er.
Den Herstellern einen Vorsprung verschaffen
Als universitäres Forschungsteam ist es nicht die Aufgabe der Imec-Forscher, kommerzielle Fußgängererkennungssysteme zu entwickeln. Stattdessen können sich Anbieter an sie wenden, um die Herausforderungen und Hindernisse zu lösen, die sich bei der Entwicklung von Szenen- und Videoanalyse unter Verwendung verschiedener Sensoren, Sensorfusion und/oder neuronaler Netze ergeben. Durch die Nutzung der von den Imec-Forschern entwickelten und bereitgestellten Konzepte erhalten Anbieter kommerzieller Fußgängererkennungssysteme einen erheblichen Wettbewerbsvorteil.
Die Gesprächspartner

Jan Aelterman
ist Professor in der Gruppe Bildverarbeitung und Interpretation (IPI), einer imec-Forschungsgruppe an der Universität Gent (Belgien), wo er sich auf Bildmodellierung und inverse Probleme spezialisiert hat. Seine Forschung befasst sich mit Bild- und Videorestauration, Rekonstruktion und Schätzungsproblemen in Anwendungsbereichen wie HDR-Video, MRI, CT, (Elektronen-)Mikroskopie, Fotografie und Multiview-Verarbeitung.

David Van Hamme
ist leitender Forscher am IPI, der Forschungsgruppe für Bildverarbeitung und -interpretation des imec an der Universität Gent, der er 2007 beitrat. Zu seinen Forschungsthemen gehören Videosegmentierung, Brand- und Objekterkennung für industrielle Sicherheit, industrielle Inspektion und intelligente Fahrzeugwahrnehmungssysteme, über die er 2016 promovierte.
