Smartes Maschinenmonitoring
Anomalien mit Edge-KI detektieren
KI-basiertes Maschinenmonitoring kann viel Zeit sparen, kostet aber oft viel Aufwand bis zum Einsatz. Oft fehlen auch Trainingsdaten. Zwei neue Methoden können per unüberwachtem Lernen Anomalien erkennen, ohne Fehlerzustände vorab zu trainieren. Die Edge-KI funktioniert ohne Cloud-Zugang.
KI und Machine Learning können in der industriellen Automatisierung viel Zeit sparen und die Effizienz steigern. Für die Maschinenüberwachung hat das gemeinnützige Institut für Mikroelektronik- und Mechatronik-Systeme (IMMS) neuartige Methoden entwickelt, die den oft immensen Initialaufwand deutlich senken und diese in zwei Demonstratoren implementiert. Für beide Szenarien konnte gezeigt werden, dass nicht nur ein schneller Einsatz von KI-basiertem Monitoring in Unternehmen und auf dem Shopfloor möglich ist, sondern dieser auch ohne Cloud-Zugang funktioniert und sich somit schlanke Monitoring-Systeme ableiten lassen.
Vorausschauende Wartung
Für effiziente Produktionsprozesse ist es entscheidend, Maschinenstörungen früh zu erkennen, Ausfallzeiten zu minimieren und teure Reparaturen zu vermeiden. Dafür braucht es ein kontinuierliches Monitoring, meist mittels Vibrationssignalen oder der Stromaufnahme.
Mit Machine Learning lassen sich komplexe Muster und kleinste Veränderungen erkennen, die konventionellen Methoden übersehen. Jedoch ist es in der Industrie und vor allem für KMU zeitlich und organisatorisch sehr aufwändig, Sensordaten aufzunehmen und potenzielle Fehler mit allen relevanten Betriebs- und Stördaten für ein Training von Algorithmen zu erfassen. Zudem treten im Normalbetrieb Defekte an Maschinen selten bis nie auf, manche Fehler wie defekte Maschinenteile lassen sich kaum gezielt erzeugen und Rohdaten müssen meist stark vorverarbeitet werden, um sie fürs Training eines KI-Modells zu nutzen.
Neuer Ansatz: Unüberwachtes Lernen
Beim unüberwachten Lernen wird ein bekannter Zustand, hier der fehlerfreie Gutzustand, erfasst und Algorithmen eingesetzt, um Abweichungen zu erkennen und entsprechende Maßnahmen einleiten zu können. In diesem Teilbereich des maschinellen Lernens werden Algorithmen eingesetzt, um Muster, Strukturen oder Zusammenhänge in Daten zu identifizieren – ganz ohne vorab definierte Zielwerte oder Labels. Zu den typischen Methoden zählen Clustering-Algorithmen wie k-Means zur Gruppierung ähnlicher Datenpunkte, Verfahren zur Dimensionalitätsreduktion wie Hauptkomponentenanalyse oder Singulärwertzerlegung zur Vereinfachung komplexer Datensätze sowie Anomalieerkennung, um ungewöhnliche oder unerwartete Beobachtungen zu entdecken.
Für die weiteren Untersuchungen wurden unterschiedliche Datensätze mit Vibrationsdaten, zum Teil öffentlich verfügbare wie z.B. der Pronostia-Datensatz verwendet.
Clustering von Daten
Der k-Means-Algorithmus ist ein Verfahren aus dem Bereich des unüberwachten Lernens und wird vor allem für Clustering-Aufgaben eingesetzt. Hierbei werden Datenpunkte in k Gruppen unterteilt, sodass Punkte innerhalb einer Gruppe möglichst ähnlich sind. K-Means arbeitet in der Regel sehr schnell und lässt sich gut auf größere Datenmengen anwenden. Allerdings kann das Verfahren empfindlich auf Ausreißer reagieren und liefert nicht immer gute Ergebnisse, wenn die Daten komplex oder ungleichmäßig verteilt sind.
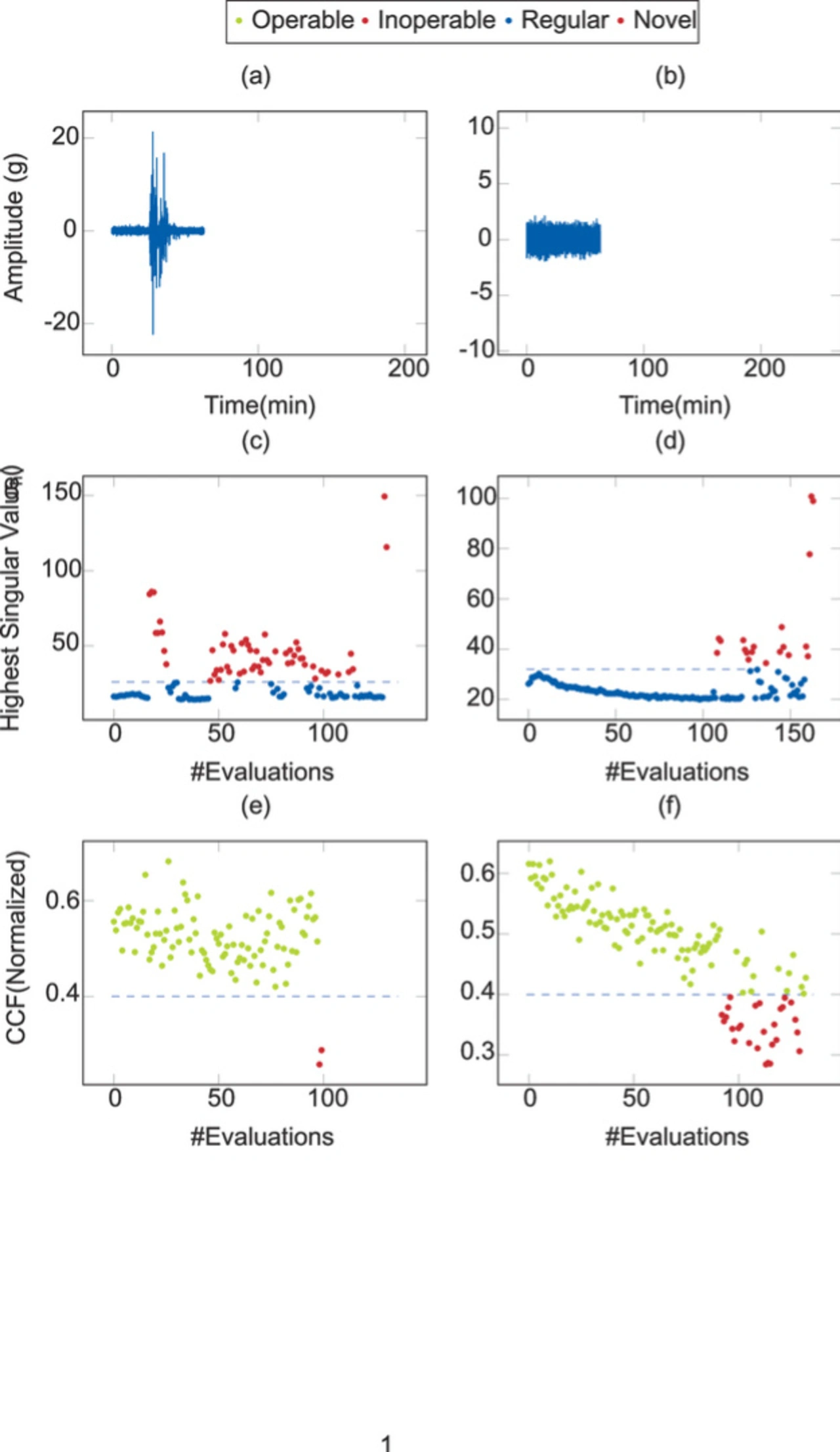
Datenreduktion
- Singulärwertzerlegung: Die Singulärwertzerlegung (Singular Value Decomposition, SVD) ist eine Methode der linearen Algebra, um die Dimensionalität von Daten zu reduzieren. Einen reduzierten Datensatz erhält man, indem nur die ersten k dominanten Singulärwerte und die entsprechenden Teile der Singulärwertzerlegung verwendet. Die Datenpunkte mit den größten Singulärwerten sind in Bild 1 Mitte dargestellt. Die Standardabweichung der Singulärwerte wurde genutzt, um einen Schwellwert (Ψ), dargestellt als gestichelte Linie in Bild 1 Mitte, für den Neuigkeitswert der Daten zu berechnen.
- Korrelation: Die Singularwerte können dazu genutzt werden, um in einem weiteren Schritt mittels Kreuzkorrelation Abweichungen von einem gelernten Gutzustand zu erkennen. Als Korrelationsalgorithmus wurde die Canonical Crosscorrelation Analysis (CCA) verwendet und für die Umsetzung drei Phasen; Lern-, Beobachtungs- und Implementierungsphase definiert.
Drei Phasen des KI-Trainings
In der Lernphase wird davon ausgegangen, dass sich die Maschine in einem intakten Gutzustand befindet. Die Singulärwertzerlegung wird auf das erfasste Vibrationssignal X angewendet.. Die für eine Analyse per Fast Fourier Transformation (FFT) in Frequenzanteile zerlegten zeitdiskreten Signale des Vektors der Singulärwerte wird als Merkmal für den intakten Zustand der Maschine verwendet und in einer Merkmalsmatrix F gespeichert und daraus ein Schwellenwerts ψ berechnet.
Die Beobachtungsphase ist optional, kann aber nützlich sein, um bestimmte Anomalien bzw. Zustände zu lernen und als Merkmal F zu speichern. Dies führt zur Aktualisierung der Merkmalsmatrix F und des Schwellenwertes ψ.
In der Implementierungsphase werden neue Vibrationswerte (X) aufgezeichnet und mit SVD zerlegt, um den Merkmalsvektor f zu erhalten. Dieses Merkmal wird dann mittels CCA mit der bereits erlernten Merkmalsmatrix F des Gutzustandes analysiert. Das Ergebnis der CCA-Analyse wird als Degradationskoeffizient bezeichnet. Ein Beispiel für einen sich verschlechternden Lagerzustand ist in Bild 1 unten dargestellt.
Diese Kombination aus Merkmalsextrakion mit SVD und nachfolgender Korrelation erlaubt eine automatisierte Merkmalsextraktion und anschließende Detektion von Zustandsänderungen. Weitere Details sind im Patent »Verfahren und Sensoranordnung zum Überwachen einer Funktion eines Bauteiles einer Maschine«, DE 10 2024 100 703 B3, beschrieben.
Anomalie-Detektion mit neuronalen Netzen
Neuronale Netze sind eine Möglichkeit, um Abweichungen vom Normzustand, d.h. Anomalien in den Daten, anhand wesentlich komplexerer Muster zu erkennen und somit ein zeitaufwändiges Erfassen bekannter Fehlerzustände überflüssig zu machen.
In dieser Untersuchung wurden zwei Modelle zur Anomaliedetektion verwendet: LSTM-AD (Long Short-Term Memory Anomaly Detection) und Autoencoder. Beide Modelle wurden mit Vibrationsdaten trainiert, die ausschließlich den normalen, also fehlerfreien Zustand einer Maschine repräsentieren. Sie lernen auf Basis einer festgelegten Fenstergröße, also eines bestimmten Zeitabschnitts der Messdaten, das typische Verhalten der Maschine und sagen anschließend die nächsten Messwerte voraus.
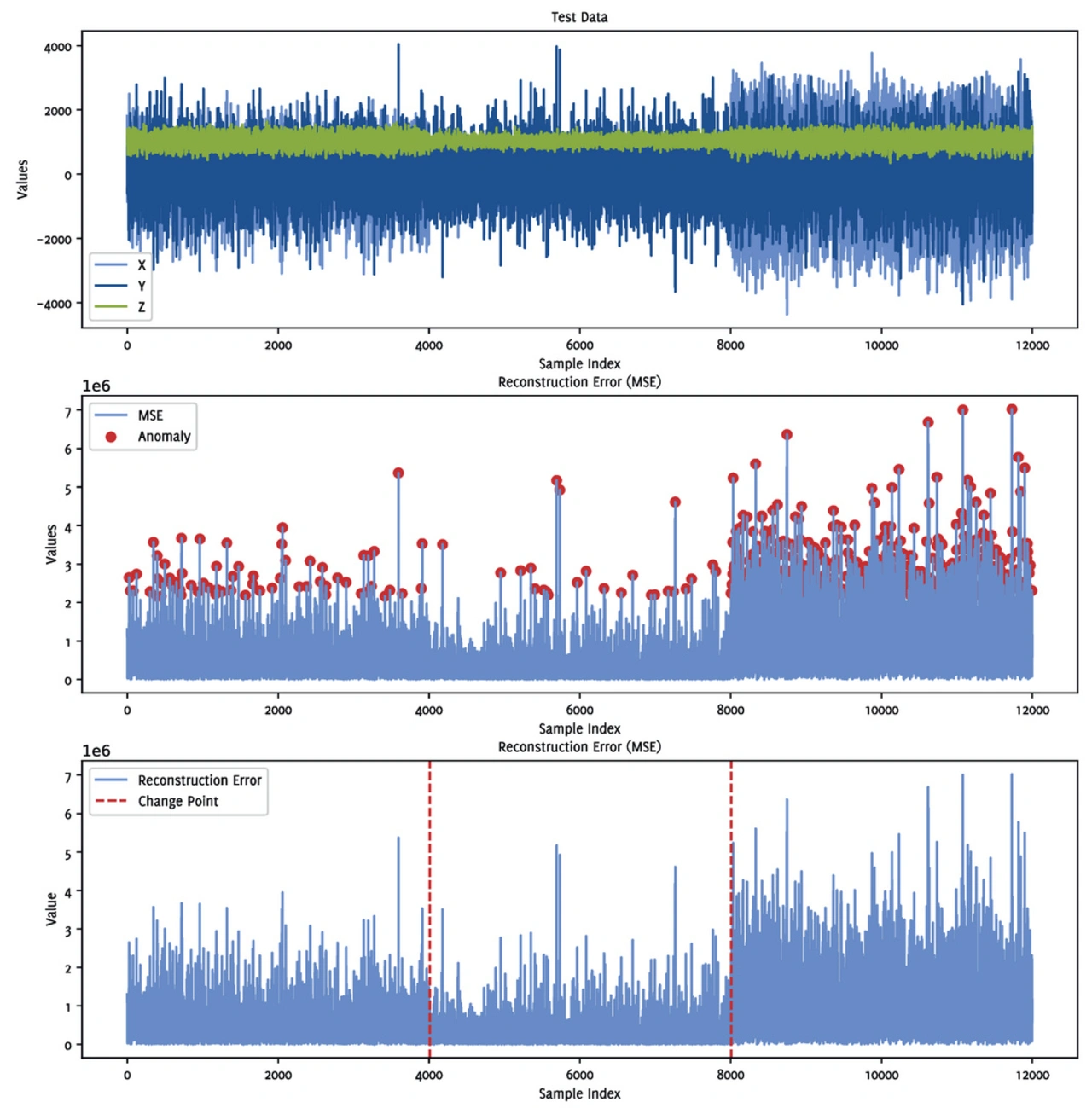
Um die Robustheit der Modelle zu testen, wurden sie mit verschiedenen Testdaten evaluiert, sowohl mit fehlerfreien als auch mit fehlerhaften Daten, die bereits Anomalien enthalten können. Da die Modelle jedoch nur auf Gutzustände trainiert wurden, gelingt ihnen die Rekonstruktion der Vibrationsdaten bei Vorliegen einer Anomalie nicht mehr präzise. Es entsteht ein sogenannter Rekonstruktionsfehler, also die Differenz zwischen dem tatsächlichen und dem vorhergesagten Signal. Aus diesem Fehler wird ein Anomalie-Score berechnet, der Hinweise auf ungewöhnliches Verhalten liefern kann.
Der aus dem Modell resultierende Rekonstruktionsfehler wird anschließend einem Change-Point-Detection-Algorithmus übergeben. Dieser sucht mithilfe eines fensterbasierten, schrittweisen Verfahrens nach Punkten im Signal, an denen sich das Verhalten signifikant ändert, also potenziellen Anomalien. Auf diese Weise lassen sich Veränderungen im Maschinenzustand automatisiert und zuverlässig erkennen. In Bild 2 sind die Vibrationsdaten, der Rekonstruktionsfehler mit erkannten Anomalien, einmal mit einem statischen Schwellwert und einem Change Point Detektion Algorithmus dargestellt.
LSTM-AD oder Autoencoder?
Die untersuchten Modelle erlauben eine Detektion von Anomalien. LSTM-AD ist besonders geeignet für die Analyse zeitabhängiger Daten, da es durch seine rückgekoppelte Struktur sowohl langfristige als auch kurzfristige Muster in sequenziellen Signalen erfassen kann. Allerdings erfordert der Einsatz von LSTM-AD eine größere Menge an Trainingsdaten sowie eine aufwendigere Modellanpassung und ist damit auch rechenintensiv.
Im Gegensatz dazu bieten Autoencoder einen effizienteren Ansatz zur Anomaliedetektion, da sie versuchen, Eingabedaten möglichst originalgetreu zu rekonstruieren. Weicht das rekonstruierte Signal stark vom Original ab, kann dies auf eine Anomalie hinweisen. Autoencoder sind besonders gut geeignet, wenn es sich um stationäre Vibrationsdaten handelt, also Daten, deren Muster sich über die Zeit wenig verändern. Sie sind einfacher zu trainieren als LSTM-Modelle, eignen sich jedoch weniger für stark zeitabhängige oder dynamisch veränderliche Zustände.
Mit allen Methoden lassen sich Abweichungen von Normalzuständen in Daten erkennen. Die Singulärwertzerlegung ist eine robuste Methode zur Dimensionsreduktion und zur Identifikation neuartiger Muster in linearen Daten. Algorithmen zur Anomaliedetektion sind flexibler und leistungsfähiger bei der Analyse komplexer oder nichtlinearer Systeme. Sie können jedoch rechenintensiver sein und erfordern eine sorgfältige Parametrierung.
Demonstratoren
Um eine mögliche Anwendung im industriellen Umfeld zu veranschaulichen, wurden Algorithmen für zwei Szenarien in zwei Demonstratoren implementiert (Bild 3).

Der einfache k-Means-Algorithmus wurde direkt auf einem kleinen, energieautarken Sensorsystem als lokale KI implementiert und mit einem Demonstrator zum Lüftermonitoring als Beispiel für die Überwachung von Lagern evaluiert. Der Sensor kann auf den Zustand des einen intakten Lüfters trainiert werden. Ein weiterer »intakter« und ein »defekter« Lüfter können dann entsprechend erkannt und klassifiziert werden, ohne dass die Daten vorher aufgezeichnet wurden. Angezeigt wird das Ergebnis über eine grüne und rote LED.
Eine komplexere, leistungsfähigere Anomalie-Detektion wurde in einem energieeffizienten Edge-KI System mit lokaler Vorverarbeitung auf dem Sensorknoten und Anomalie-Detektions-Algorithmen auf dem Edge-Device mit einer Datenverarbeitung anhand der Überwachung von Vibrationen auf einem Shaker demonstriert. Der Sensorknoten ist auf dem Erregersystem montiert. Mit dem System kann nun ein Gutzustand trainiert werden. Der Sensorknoten erfasst zyklisch das Vibrationssignal, was von ein Mal pro Sekunde bis zu ein Mal pro Stunde einstellbar ist, und überträgt es zu dem Edge-Device, in dem Fall ein Raspberry Pi ohne Cloud-Zugang. Auf diesem werden dann Abweichungen vom Gutzustand detektiert und per Dashboard im Browser auf einem Tablet visualisiert. Wird nun das erzeugte Schwingungssignal verändert, werden diese Änderungen detektiert und grafisch angezeigt.
KI-Monitoring mit wenig Aufwand
Die vorgestellten Ergebnisse helfen, Aufwand und Kosten beim Implementieren von KI-basiertem Monitoring zu senken. Vibrationssensoren standen im Fokus: Sie sind gängige Praxis zur Erfassung von Maschinenzuständen. Einfache Algorithmen wie ein Clustering wurden in einem Mikrocontroller implementiert, um zu zeigen, dass diese sich direkt auf Ultra-Low-Power-Sensorik ausführen lassen. Für komplexere Aufgaben müssen Daten vom Sensorknoten zu einem Edge-Device übertragen werden, auf dem die KI-Algorithmen laufen. Dafür wurden Kompressionsalgorithmen untersucht und auf dem Sensorknoten implementiert, um dessen Batterien zu schonen, da nur die benötigten Daten an das Edge-Device gesendet werden. Es wurde gezeigt, dass sowohl das Training als auch die Inferenz, also die KI-basierte Schlussfolgerung, direkt auf dem Sensorknoten oder bei komplizierten Algorithmen auf Edge-Devices wie einem Raspberry Pi ohne Cloud-Zugang implementierbar sind.
| Über das IMMS / Förderung |
|---|
| Das Institut für Mikroelektronik- und Mechatronik-Systeme arbeitet gemeinnützig als F&E-Partner für Anwendungsentwicklungen von Unternehmen, u.a. in Kooperation mit der TU Ilmenau. Die im Beitrag vorgestellten Systeme wurden in der internen, vom Freistaat Thüringen geförderten KI-Forschungsgruppe des IMMS und im Projekt HoLoDEC entwickelt. Das IMMS ist bestrebt, Weiterentwicklungen voranzubringen und sucht dafür nach Anwendungspartnern. Das diesem Bericht zugrunde liegende Vorhaben HoLoDEC wurde mit Mitteln des Bundesministeriums für Bildung und Forschung unter dem Förderkennzeichen 16ME0703 gefördert. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt beim Autor. |
