Software Optimierung
ARM-Prozessor-Tuning für harte Echtzeit
Echtzeitkritische Regelungen stellen hohe Anforderungen an Hard- und Software – und die Entwickler. Hier helfen Prozessoren mit immer höherer Taktfrequenz wenig. Das ganze System – Prozessor, Speicher, Beschleuniger und Software – muss optimiert werden, um harte Echtzeitanforderungen zu erfüllen.
Die Komplexität moderner Echtzeitsysteme nimmt kontinuierlich zu aufgrund der immer anspruchsvolleren Anforderungen und Aufgaben. Regelungssysteme mit einer Vielzahl an Freiheitsgraden – nicht selten im hohen zweistelligen Bereich –, Signal-Processing-Pipelines, Bildverarbeitung oder maschinelles Lernen in Echtzeit sind nur einige Beispiele hierfür. Typische Werte für Regelungszyklen sind 10 – 20 kHz (100 – 50 µs). Zur eigentlichen Regelung kommen meist noch Aufgaben wie Pre/Post-Processing, Performance Monitoring – Regelabweichung, Collision Detection etc. – und weitere hinzu, sodass zur maximalen Zykluszeit noch ein Leerlauf (Slack) von z. B. 5 µs für den Nicht-Echtzeitanteil hinzukommt.
Um den gestiegenen Anforderungen gerecht werden zu können, um bestimmte echtzeitkritische Regelungsaufgaben überhaupt ausführen zu können, sind deutliche Leistungssteigerungen und -optimierungen unerlässlich, wobei es erfahrungsgemäß ab zehn und mehr Freiheitsgraden zunehmend schwierig wird, zu optimieren. Dabei müssen Software und Hardware durch immer komplexere Architekturen nachziehen. Allerdings stößt die Hardwareentwicklung zunehmend auf physikalisch-technische Grenzen: Unter anderem wegen thermischer Bedingungen konnten die Taktfrequenzen der Prozessoren in den vergangenen Jahren durch rein halbleitertechnische Weiterentwicklung nicht mehr signifikant gesteigert werden.
Um dennoch Prozesse weiter zu beschleunigen, müssen andere Wege gefunden werden. So konnten nennenswerte Leistungssteigerungen durch softwaregestützte Techniken wie Branch-Prediction, Out-of-Order-Ausführungen oder spekulative Ausführungen von Instruktionen erreicht werden. Zudem verwenden moderne Prozessoren eine ausgeklügelte Instruktionspipeline und können mehrere Instruktionen unter Verwendung mehrerer funktionaler Einheiten gleichzeitig ausführen. Nachfolgend werden drei wesentliche Wege zur Leistungsoptimierung skizziert, wobei dies aufgrund der enormen Bandbreite der Thematik nur beispielhaft geschehen kann.
Cache-Optimierung
Die Beschleunigung von Prozessgeschwindigkeiten umfasst nicht alle Bereiche der Interaktion von Hardware und Software in gleichem Maße. Die Zugriffsgeschwindigkeit von Speichern etwa konnte bisher nicht im selben Umfang wie die Ausführungsgeschwindigkeit der Prozessoren gesteigert werden. Die Erfahrung zeigt, dass heutzutage an vielen Stellen nicht die Ausführungszeit des Prozessors, sondern die Speicherzugriffe den limitierenden Faktor bei Prozessbeschleunigungen bilden.
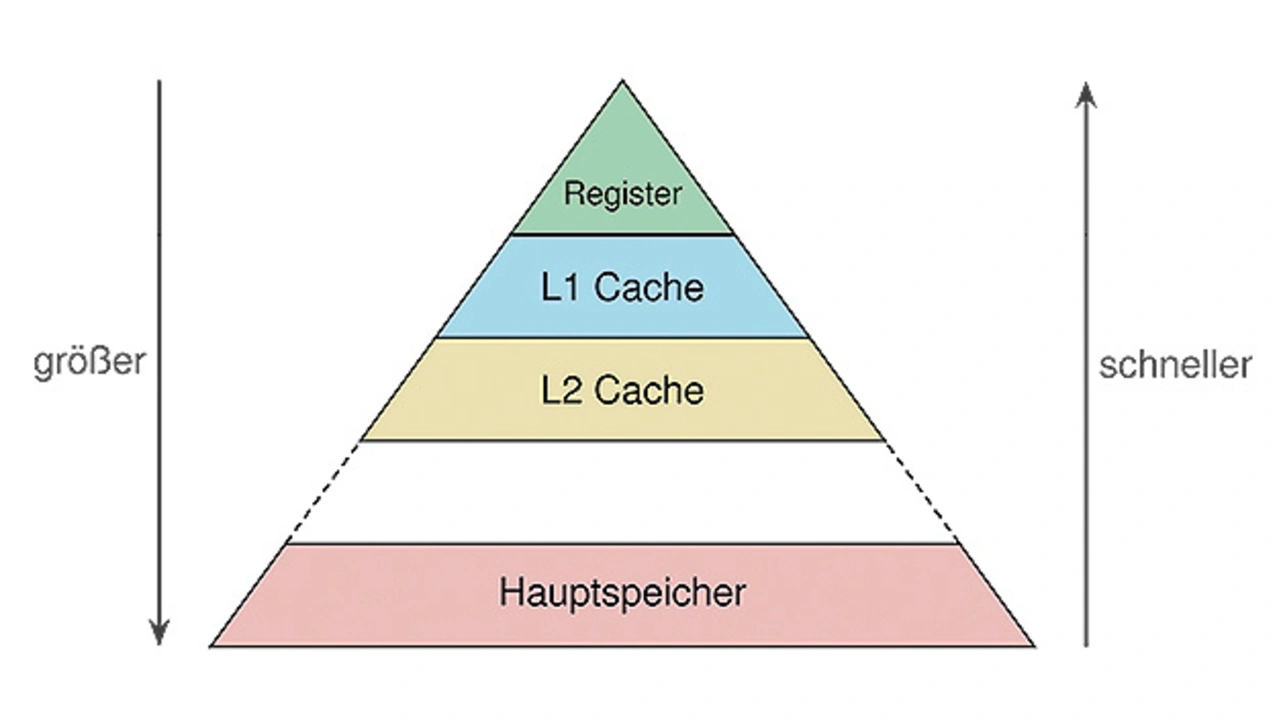
Deswegen sind mittlerweile Speicherhierarchien mit Caches üblich, in denen häufig genutzte Daten in einem kleineren, aber zugriffsschnelleren Speicher (Cache) als Kopie abgelegt sind. Effizienzsteigerungen sind hier durch mehrstufige Speicher möglich (Bild 1). Das zugrundeliegende Prinzip ist einfach: Je höher die Speicherkapazität des Cache, desto niedriger die Zugriffsgeschwindigkeit und umgekehrt. So sind Speicherkomplexe wie in Bild 1 gezeigt möglich, bei denen das Register die kleinste Einheit an der Spitze bildet, auf deren Inhalte aber am schnellsten zugegriffen wird. Darunter folgen mehrere Cache-Ebenen – L1, L2 etc. – mit zunehmender Kapazität, in denen die Kopien von Daten aus dem zuunterst liegenden Hauptspeicher abgelegt sind.
Daraus folgt, dass es von großer Bedeutung sein kann, die Eigenschaften solcher Cache-Hierarchien bei der Programmierung zu berücksichtigen. Allerdings können dabei wie bei allen Optimierungen unerwünschte Nebeneffekte wie Cache Trashing, konkurrierende Zugriffe etc. auftreten, denen durch geeignete Maßnahmen wie Cache-Lockdown, manuelles Cache-Management oder bestimmte Access Patterns begegnet werden muss.
Parallelisierung
Eine der wichtigsten Techniken zur Optimierung ist die Parallelisierung der Abarbeitung bestimmter Aufgaben. Dabei werden Algorithmen in voneinander möglichst unabhängige Teilprobleme aufgeteilt, die gleichzeitig berechnet werden können. Dies kann feingranular erfolgen, z. B. durch SIMD-Instruktionen (Single Instruction, Multiple Data) oder in Form größerer funktionaler Blöcke, die auf zusätzlichen Prozessorkernen oder auf Hardwarebeschleunigern laufen. Letzteres erfährt durch die zunehmende Popularität von SoCs mit integrierter programmierbarer Logik (FPGA, Field Programmable Gate Array) immer mehr Aufmerksamkeit. Dies führt zu hochgradig heterogenen Architekturen, bei denen Teile des Algorithmus in Software und andere Teile auf dedizierter Hardware laufen. Hierbei beschäftigt sich das Hardware/Software-Codesign damit, eine möglichst optimale Partitionierung sowohl funktional als auch temporal zu erreichen. Zwei typische Optimierungsmöglichkeiten dieser Art sind:
- Die Verwendung von SIMD-Instruktionen – eine relativ einfache Möglichkeit
- Das Prinzip des Hardware/Software-Codesigns – eine besonders effektive Methode zur Leistungsoptimierung.
SIMD-Instruktionen an einem Beispiel
Das Grundprinzip von SIMD-Instruktionen ist die parallele Ausführung ein und derselben Operation auf mehreren Datenbereichen. Typische Anwendungsfälle sind Bild- oder Videodaten, bei denen sich dieselben Operationen häufig wiederholen. Klassische SIMD- bzw. Vektorprozessoren gibt es schon seit Anfang der 1970er-Jahre. Mit den steigenden Anforderungen für Multimediaanwendungen wurden auch RISC-Prozessoren um spezialisierte SIMD-Instruktionen erweitert. So werden beispielsweise moderne Intel-Prozessoren durch SSE bzw. AVX als SIMD-Einheit und ARM-Prozessoren durch den NEON-Befehlssatz erweitert. Da im Embedded-Umfeld ARM-Prozessoren eine dominante Position einnehmen, wird im Folgenden die Verwendung der NEON-Erweiterung speziell für ARM erläutert.
| NEON-Auto-Vektorisierung |
|---|
ARM gibt für die NEON-Auto-Vektorisierung, folgende Grundregeln an: |
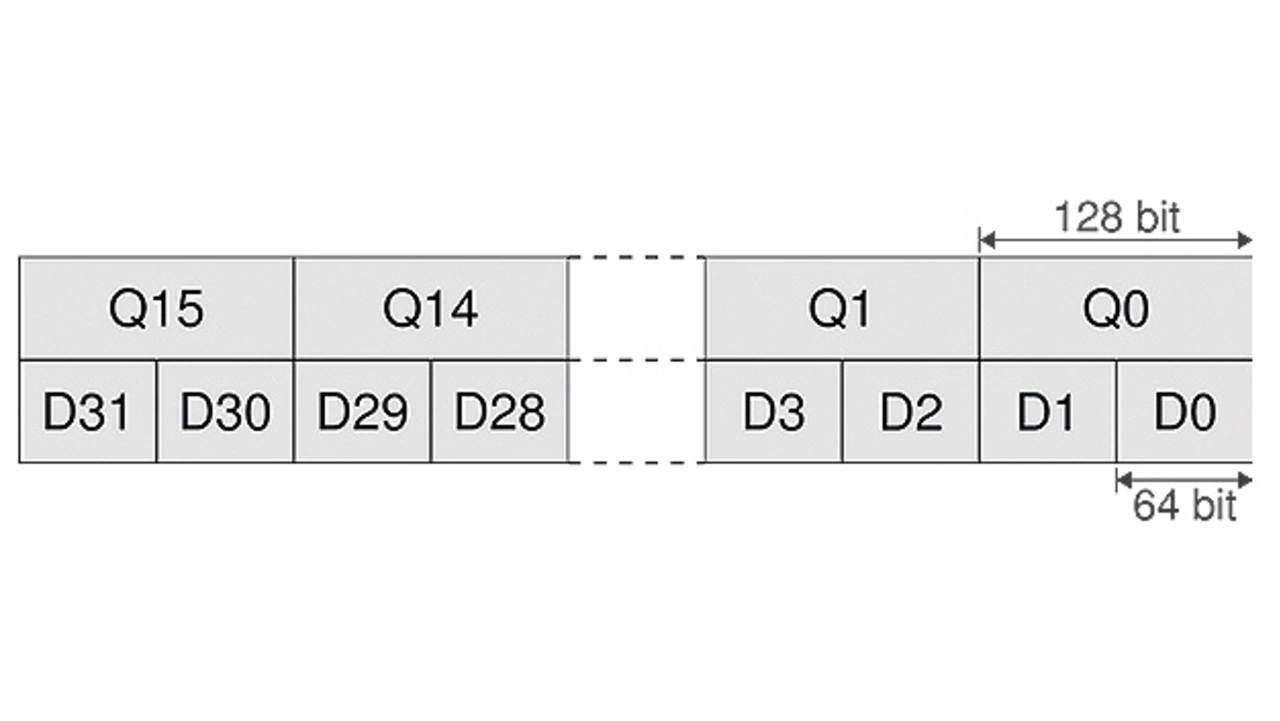
Die NEON-Technik von ARM ist eine Erweiterung des ARM-Befehlssatzes um zusätzliche Assembler-Instruktionen zur parallelen Datenverarbeitung, die als grundlegende Datenstruktur Vektoren verwendet. NEON-Instruktionen arbeiten mit einem eigenen 256-Byte-Registerfile (Bild 2), das entweder als 32×64-bit-Register (D0, D1, D2 ...) oder als 16×128-bit-Register (Q0, Q1, ...) ausgelesen werden kann.
NEON-Instruktionen werden als packed SIMD-Instruktionen ausgeführt. Dabei wird jedes Register als Vektor mit einer bestimmten Anzahl an Elementen interpretiert. Die Vektorelemente können vorzeichen- lose oder vorzeichenbehaftete Integerzahlen mit 8 bit, 16 bit, 32 bit oder 64 bit oder 32-bit-Fließkommazahlen sein. Die Besonderheiten von NEON sind:
- Es ist ein Start-up-Code nötig.
- Bei Benutzung von NEON-Instruktionen innerhalb von Unterbrechungsroutinen sollten die Lanes gesichert werden.
- NEON ist neben LDM/STM (Load Multiple/Store Multiple) sehr gut geeignet für Block-Transfers ohne DMA (Direct Memory Access).
NEON-Instruktionen haben die Form:
Die Komponenten in {} sind optional, die anderen fakultativ. Die Namen der Instruktionen beginnen stets mit V, sodass die kürzest mögliche Instruktion folgende Form hat:
V<op> bedeutet die Instruktion, <dest1> das erstangegebene Ziel sowie <src1> die erste Quelle im Register. Zusätzlich können noch Modifikationen (<mod>), Bedingungen (<cond>) bzw. Datentypen (.<dt>) angegeben werden. Die Instruktion
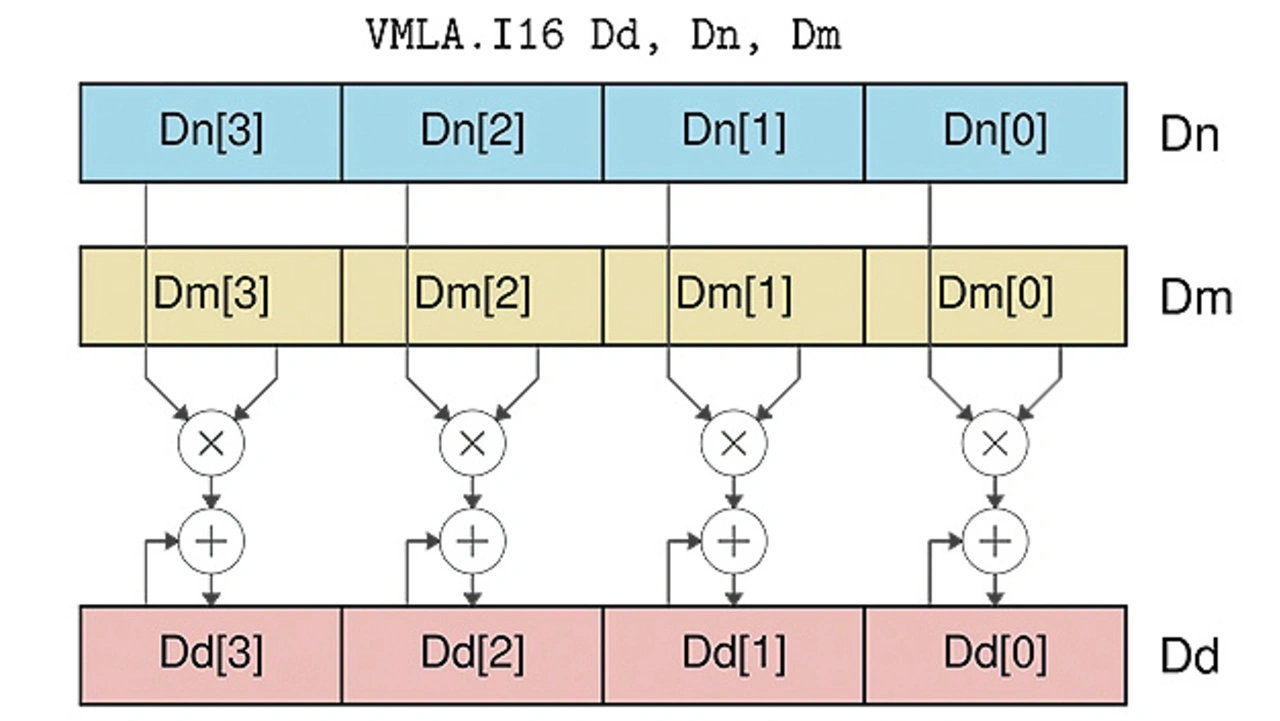
führt beispielsweise eine Multiply-Accumulate-Operation (VMLA, Fused Multiply Add) auf dem Datentyp 16 bit Int (.I16) aus, die effiziente Matrix-Multiplikationen ermöglicht (Bild 3). Die 64-bit-Quellenregister (D1, D2) werden als Vektoren mit vier 16-bit-Integer interpretiert und das Ergebnis landet als vier 16-bit-Integer im Zielregister D0. Die Quellenregister müssen hierfür vorher mit den entsprechenden Ladebefehlen befüllt werden.
Bei bestimmten Operationen können Datentypen auch vermischt werden. Beispielsweise resultiert
in einer Multiplikation von jeweils vier 16-bit-Integern (D8, D9), wobei das Ergebnis in vier 32-bit-Integern (Q2) gespeichert wird. Dies zeigt das Q des Zielregisters an. Das zweite L im Instruktionsname VMULL bedeutet, dass der Zieloperand ein größerer Datentyp ist als der Typ der Quellregister. Dieses Beispiel soll illustrieren, dass notfalls bitgenau festgelegt werden kann, wie berechnet und abgelegt wird.
Zwar kann es lohnenswert sein, in bestimmten Fällen handoptimierten NEON-Code selbst zu schreiben, falls die auf herkömmlichem Weg erreichten Optimierungen nicht ausreichen – ARM lässt das zu, gibt aber dazu nicht allzu genaue Hinweise.
In den allermeisten Fällen wird man jedoch auf eine bereits optimierte Bibliothek oder die Autovektorisierung des Compilers zurückgreifen. Darunter versteht man die Möglichkeit des Compilers, parallele Strukturen im Programmablauf zu erkennen und entsprechende SIMD-Instruktionen zu erzeugen. Um die Autovektorisierung des Compilers zu aktivieren, sind je nach Compiler unterschiedliche Flags nötig. Um sie beispielsweise in GCC zu aktivieren, muss man die geeignete Prozessorarchitektur mit -mcpu bzw. -march auswählen. Zudem muss der Compiler über -mfpu=neon instruiert werden, dass eine NEON-Erweiterung vorhanden ist. Als letztes muss noch die Autovektorisierung selbst mit -ftree-vectorize aktiviert werden, was je- doch bei entsprechender Optimierungsstufe gegebenenfalls auch wegfallen kann.
Zur Erzeugung möglichst effizienten NEON-Codes müssen bei der Programmierung einige Besonderheiten (Code-Styles) beachtet werden – siehe auch Kasten NEON-Auto-Vektorisierung:
- Es sollten möglichst einfache und kleine Schleifen verwendet werden.
- If-Bedingungen und Break-Anweisungen sollten in Schleifen vermieden werden.
- Sind Informationen über die Anzahl von Schleifen bekannt, sollten sie dem Compiler mitgeteilt werden.
- Direkte Adressierungen sind Dereferenzierungen vorzuziehen.
- Wenn Speicherbereiche sich nicht überlappen, sollte das dem Compiler mit __restrict angegeben werden.
Folgendes Beispiel zeigt, wie die Autovektorisierung für die bereits gezeigte Multiply-Accumulate-Operation (Bild 3) richtig verwendet wird:

Hierbei wird dem Compiler mit __restrict angezeigt, dass sich der Zielvektor Dd – bzw. dest[i] – und die Quellvektoren Dn (src1[i]), Dm (src2[i]) nicht überlappen. Daher muss vom Compiler kein zusätzlicher Code erzeugt werden, der die Überlappung berücksichtigt. Vektorüberlappung würde bedeuten, dass Dn == Dd bzw. Dm == Dd, sei es auch nur zeitweise. In dem Fall würde während der Operation das Source- register möglicherweise überschrieben, was zur Laufzeit durch Extracode mit entsprechendem Aufwand und Performanceverlust überprüft werden müsste. Mit der Maskierung der Schleifenvariablen (n & ~3), wird dem Compiler mitgeteilt, dass die Schleifenzahl durch 4 teilbar ist. Damit kann zusätzlicher Code zur Behandlung von nur teilweise gefüllten Registern herausoptimiert werden.
(Download im PDF-Format)
Hier war es dem Compiler möglich, mit den gegebenen Informationen eine optimale Implementierung mit SIMD-Instruktionen zu generieren: Sie besteht nur aus VMLA und Load/Store-Befehlen (VLD, VST) sowie der Schleife (CMP, BNE). Insgesamt besteht die Funktion aus elf Instruktionen. Wird z. B. die genannte Maskierung und das __restrict weggelassen, wächst die Funktion auf 128 Instruktionen, weil dann sämtliche Sonderfälle behandelt werden müssen. Der Assemblercode ohne die Optimierung würde so aussehen:
(Download im PDF-Format)
Es kann sich also durchaus lohnen, von Anfang an SIMD-freundlichen Programmcode zu schreiben: Die bei Mixed Mode gewonnene Erfahrung zeigt, dass die Leistung je nach Architektur durch die Verwendung von NEON-Instruktionen für einfache Signalverarbeitungsalgorithmen verdoppelt oder verdreifacht werden kann.
Jobangebote+ passend zum Thema
- ARM-Prozessor-Tuning für harte Echtzeit
- Hardware/Software-Codesign in Echtzeitsystemen