Neuromorphes Computing
Spiking Neural Networks
Die KI-Forschung schreitet beeindruckend schnell voran. Als Fortschrittsbremse hat sich die hohe Leistungsaufnahme von KI-Chips entpuppt, die vermutlich nur durch eine CMOS-Nachfolgetechnik ganz gelöst wird. Ein erster Schritt sind Spiking Neural Networks.
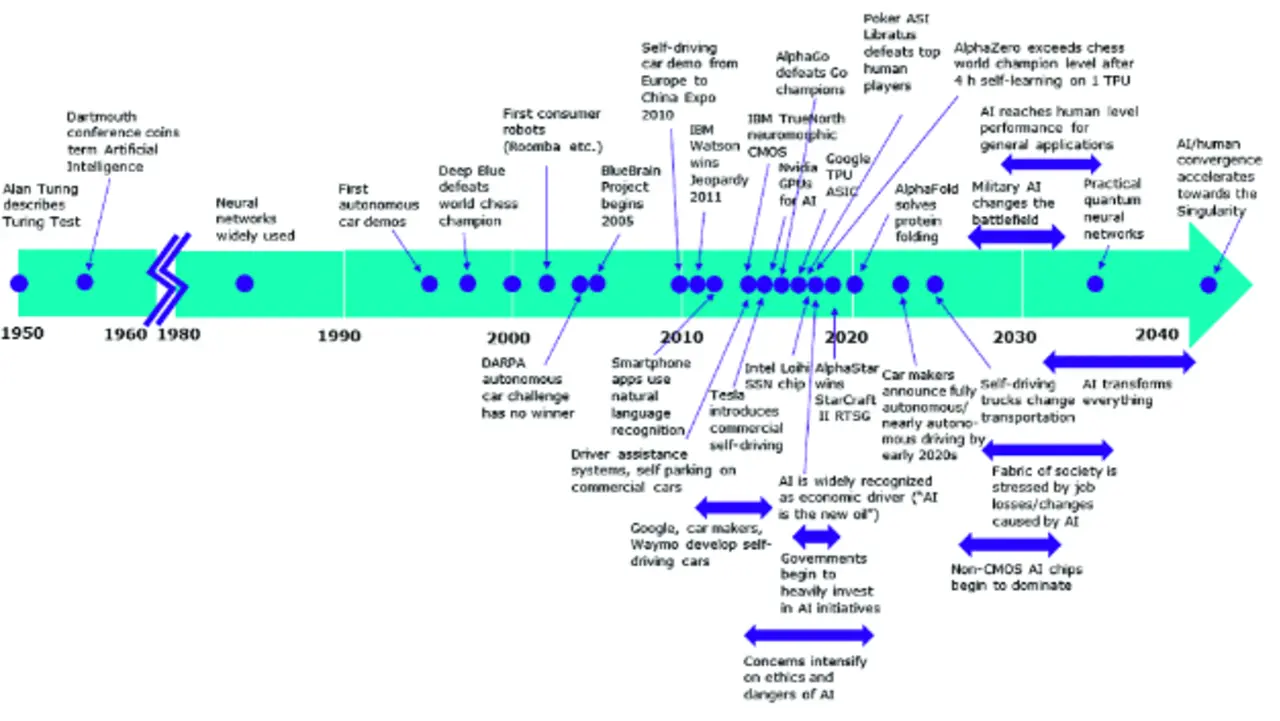
Kaum eine andere Schlüsseltechnologie hat das vergangene Jahrzehnt so geprägt wie künstliche Intelligenz (KI). Bild 1 zeigt, welche Anwendungen mit KI im Laufe der Zeit möglich geworden sind. Die Auswahl bezieht sich auf die technischen Meilensteine sowie besonders öffentlichkeitswirksame Forschungserfolge. Angesichts der vielversprechenden Durchbrüche stellt sich nun die Frage: Was kommt danach? Wenn es nach Zukunftsforschern wie Ray Kurzweil geht, werden Mensch und Computer um 2045 eine Symbiose zu einer Superintelligenz eingehen. Dieser Schritt würde die Welt so grundlegend verändern, dass danach nichts mehr vorhersehbar sein wird. Die Geschwindigkeit der Veränderungen wäre praktisch unendlich. Mathematisch gesehen handelt es sich um eine Singularität. Technologisch betrachtet gilt neuromorphes Computing als einer der vielversprechendsten Kandidaten, um den nächsten großen Entwicklungsschritt der KI praktisch umzusetzen.
Deep Learning und kNN
Ein Großteil der bisherigen Erfolge von KI geht auf Deep Learning zurück, wo die Berechnungen in künstlichen neuronalen Netzen (KNN) durchgeführt werden. Ein KNN besteht aus mehreren Lagen miteinander verbundener künstlicher Neuronen und lehnt sich mehr oder weniger stark an die neurale Struktur des menschlichen Gehirns an. KNN sind nicht neu, die Grundlagen wurden bereits in den 1970ern entwickelt. Mit bis zu Hunderten von Lagen und Millionen von Knoten erzeugen sie jedoch erst jetzt genügend Rechenleistung für den breiten technischen Einsatz.
Für das Trainieren der KNN werden riesige Datensätze durch das Netzwerk geschickt. Je nach Komplexität der Aufgabe kann der Trainingsvorgang sehr aufwendig sein, was die benötigte Rechenleistung und die elektrische Leistungsaufnahme massiv erhöht. Im trainierten Modell wird jedem Neuron ein optimiertes Gewicht zugewiesen. Soll nun für einen neuen Datensatz bestimmt werden, ob es sich beispielsweise um ein Katzen- oder ein Hundebild handelt, wird der Datensatz in einem Inferenzlauf in das KNN eingegeben. Da dieser Inferenzlauf deutlich schneller und gleichzeitig weniger aufwendig als der Trainingsvorgang ist, besteht das Bestreben, den Lauf möglichst nahe am Endbenutzer ablaufen zu lassen, z.B. auf dem Computer oder Smartphone oder zumindest am Rande der Cloud. Dies ist derzeit noch nicht immer möglich. Im Gegensatz zur Gesichtserkennung, die auf dem Endgerät abläuft, werden Spracheingaben bei Google Maps oder Alexa weiterhin an Server übertragen.
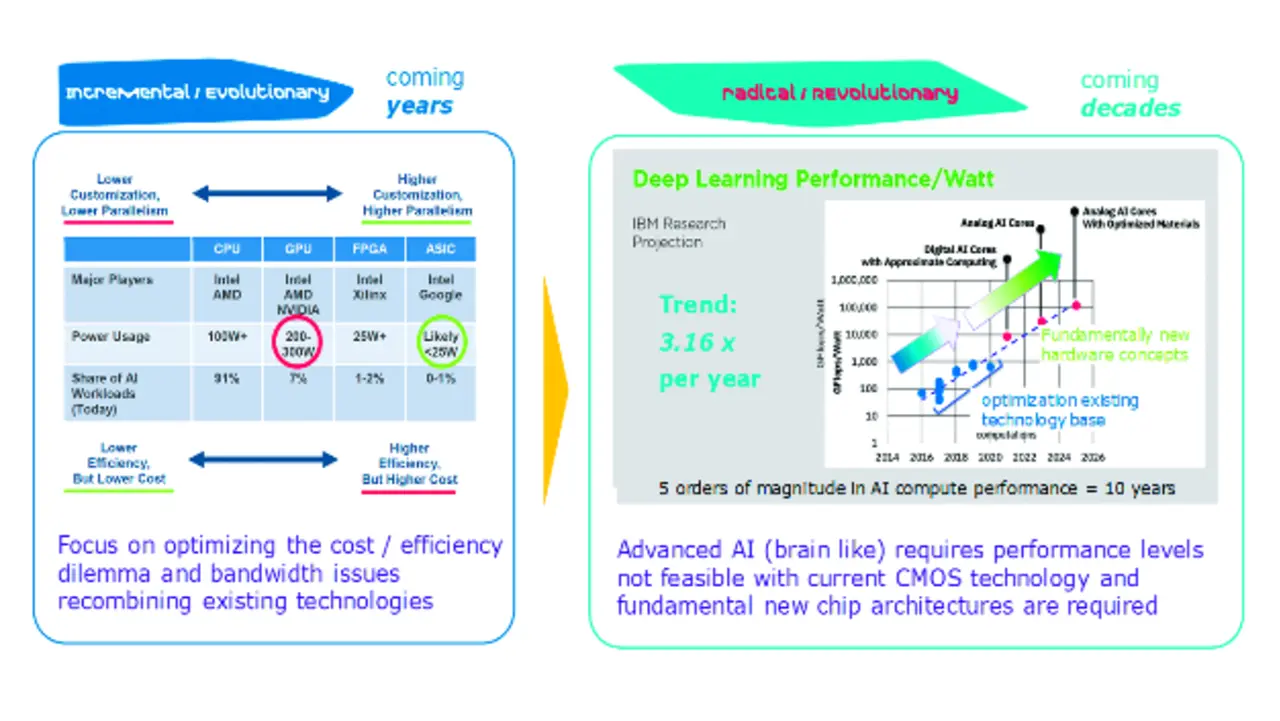
In klassischen KNN laufen alle Rechenprozesse hochparallel und synchron. Diese Anforderungen gleichen in vieler Hinsicht denen von Grafikkarten. Tatsächlich basierten einige der ersten KNN auf modifizierten Grafikprozessoren. Diese können jedoch sehr heiß laufen. Die elektrische Leistungsaufnahme bisheriger KNN war daher enorm. Mit der Entwicklung spezieller ASIC-Schaltkreise wie z. B. der Google TPU oder der Tesla-Selbstfahrchips konnte die Leistungsaufnahme um den Faktor 10 reduziert werden (siehe Tabelle in Bild 2). Gleichzeitig hat sich die Rechenleistung von KI-Chips um etwa den Faktor 3 pro Jahr erhöht.
Die Grenzen von CMOS
Um diesen Trend weiterzuführen, bedarf es grundlegend neuer Chip-Architekturen. Nach einem Whitepaper von OpenAI hat sich der Rechenbedarf des Trainings für die größten KNN-Modelle zwischen 2012 und 2018 um den Faktor 300.000 erhöht. Das heißt, der Rechenbedarf verdoppelte sich alle 3,5 Monate beziehungsweise etwa 25.000 Mal schneller als Moore’s Law zu seinen besten Zeiten. Zwar wurde künstliche Intelligenz erst durch Moore’s Law möglich, gleichzeitig hat KI die Errungenschaften dieses Grundsatzes in Rekordzeit kannibalisiert. Inzwischen sind die Kosten und der Zeitbedarf für das Training dieser großen Modelle so hoch, dass die KI nicht mehr durch Ideen für neue Anwendungen begrenzt wird, sondern durch die verfügbare Rechnerkapazität. Das Training kann Wochen oder Monate in Anspruch nehmen, Unsummen an Geld verschlingen und Hunderte von Tonnen CO2-Emissionen verursachen.
Bisher werden alle KNN-Funktionen in CMOS-Technik ausgeführt. Allerdings benötigen CMOS-Chips viel elektrische Leistung. Ende 2019 berichteten Forscher von OpenAI von einem Algorithmus, der mittels einer robotischen Hand das Rubrik-Würfel-Rätsel lösen kann. Die Entwicklung des entsprechenden Modells lief über mehrere Monate auf etwa 1.000 PCs und einem Dutzend Maschinen mit speziellen GPUs. Nach unabhängigen Schätzungen könnte dies etwa 2,8 Gigawattstunden Energie gekostet haben. Das entspricht der stündlichen Leistung von drei Kernkraftwerken.
Auch KNN-Superchips sind keine Lösung
Die moderne KI hat also zwei Probleme: wo kann sie die benötigte Rechnerleistung finden, und wie kann diese mit überschaubarem Energiebudget bereitgestellt werden?
Der Silicon Valley-Startup Cerebras hat eine Antwort auf die erste Frage. In einem beispiellosen Kraftakt der Elektroingenieurstechnik wurde ein Chip geschaffen, der die Leistungsfähigkeit eines gesamten Rechenzentrums auf einem Chip bündelt. Der von der taiwanesischen Foundry TSMC nach Cerebras-Plänen hergestellte Superchip ist mit 21,5 x 21,5 cm = 462 cm2 Fläche der mit Abstand größte jemals hergestellte Chip. Er enthält 400.000 KI-Rechenkerne mit insgesamt 1,2 Billionen Transistoren und 18 GB On-Chip-Speicher. Zu seiner Herstellung mussten völlig neue Verfahren entwickelt werden, um die einzelnen Belichtungsfelder miteinander zu verbinden und den Riesenchip in das endgültige Packaging zu bringen.
Ohne Frage ist der Cerebras-Chip eine Meisterleitung der Ingenieurstechnik, und sicher löst er das kurzfristige Problem der Bereitstellung von mehr Rechenleistung. Langfristig können solche KNN-Superchips jedoch nicht die Lösung sein, zumindest nicht, wenn sie weiter auf der CMOS-Technik beruhen. Bedingt durch den Energiehunger der CMOS-Schaltkreise benötigt der Cerebras-Chip 15 kW – und das vor Berücksichtigung der speziellen Kühlsysteme, die den Chip vor dem Schmelzen bewahren. Möglicherweise sehen zukünftige Ingenieur-Generationen diese Entwicklung als ein letztes Aufbäumen der CMOS-Technik.
Neue Chiparchitekturen: Spiking Neural Networks
Die Zukunft von KNN wird anderen Chip-Architekturen und Schaltungstechniken gehören. Besondere Hoffnungen sind mit Spiking Neural Networks (SNN) verknüpft, die der Arbeitsweise des Gehirns näherkommen als herkömmliche KNN. Wie das Gehirn arbeiten die SNNs asynchron, d.h. ein Neuron wird nur aktiv, wenn die Summe der in ihm gespeicherten Impulse einen Grenzwert übersteigt. Obwohl auch diese Chips derzeit noch in CMOS-Technik gefertigt werden, hält sich die Leistungsaufnahme in Grenzen.
| Hersteller | Chip | Technologie | Integrationsdichte | Leistungsaufnahme |
|---|---|---|---|---|
| IBM | True North | Digital ASIC, 28 nm CMOS | 1M Neuronen, 256 M Synapsen | 26 pJ pro Synapsen-Operation, 70 mW |
| Intel | Loihi | Digital ASIC, 14 nm CMOS | 130k Neuronen, 130 M Synapsen | 23,6 pJ pro Synapsen-Operation |
Brainchip | Akida | Digital ASIC, 14 nm CMOS | 1.2 M Neuronen und 10 B Synapsen | 100x besser als IBM oder Intel-Chips* |

Da die meisten der Neuronen zu jedem Zeitpunkt inaktiv sind, kommen diese Chips mit rund 70 mW Leistung oder weniger aus - etwa 68 Mal weniger als eine CMOS-KNN. In Tabelle 1 sind drei Chips mit Hersteller und Leistungsaufnahme aufgelistet, die nach dem SNN-Prinzip arbeiten. Der Loihi-Chip aus Zeile 2 der Tabelle ist in Bild 3 gezeigt, zusammen mit einem Großrechnersystem, bestehend aus insgesamt 768 Loihi-Chips mit 98.304 neuromorphen Rechenkernen. Das System vereint 100.663.296 (~108) Neuronen und 99.840.000.000 (~1011) Synapsen. Zwar ist dies noch deutlich weniger als der menschliche Neocortex mit ca. 2 x 1012 Neuronen und ~1014 Synapsen, doch es kommt schon in die Nähe eines Rhesusaffen-Neocortex mit ~ 1,7 x 109. Zukünftige analoge SNN-Schaltungstechniken, die beispielsweise auf der neuen Electrochemical RAM (ECRAM)-Technik beruhen könnten, wären in der Lage, diesen Wert um eine weitere Größenordnung zu senken. Ähnliche Einsparungen sind für herkömmliche KNN möglich, wenn zukünftige CMOS-Nachfolgetechniken wie die Magneto-Elektrische Spin-Orbit-Logik (MESO) zum Einsatz kommen, in der nicht mehr mit der Elektronenladung, sondern mit dem Elektronenspin gerechnet wird.
Aufwendige SNN-Programmierung
SNN sind jedoch erheblich schwieriger zu programmieren als KNN. Die sogenannte Rückpropagation der Daten beim Netzwerktraining ist bisher ungelöst. Bisher setzt man SNN daher eher zu Inferenzanwendungen ein. Dabei werden die Gewichte der Netzwerkknoten in herkömmlichen KNN bestimmt und dann auf die SNN übertragen.
Bislang sind KNN Meister im Lösen von Aufgaben in eng begrenzten Gebieten, für die große Datenmengen zum Training bereitgestellt werden können, z. B. indem ein Schachprogramm millionenfach gegen sich selbst spielt oder das Netzwerk mit Hunderttausenden Bildern eines Pferds gefüttert wird. Dies ist noch grundverschieden vom Lernen eines Kindes, dem man ein oder zwei Bilder eines Pferdes zeigt, und das danach problemlos Pferde auf Bildern erkennen kann. Dieses schnelle Lernen nachzuvollziehen ist eines der Hauptziele der KI-Forschung. Ein Ansatz ist die sogenannte weiche Klassifizierung, in der ähnliche Eigenschaften von verschiedenen Objekten in einem Bild vereinigt werden. Die Erkennung handgeschriebener Zahlen mit einem KNN braucht einen Datensatz von etwa 60.000 Bildern – mit »soft labels« erreicht man bereits mit zehn Bildern eine Genauigkeit von 94 %. Diese Bilder sind aber für Menschen nicht mehr erkennbar.

Tatsächlich ist meist völlig unklar, welche Kriterien KNN anwenden, um Entscheidungen zu treffen und Bilder zu erkennen. Dies zeigt sich in ihrer Anfälligkeit für »feindliche Angriffe«, in denen kleine Änderungen an Bildern, wie etwa kleine Aufkleber auf Verkehrsschildern, das Ergebnis von »30 km/h« auf »freie Fahrt« verändern. Ähnlich erkennt ein auf Bananen trainiertes Netzwerk nach Zugabe eines Stickers plötzlich einen Toaster, und niemand weiß warum (Bild 4). Dies mag in diesem Beispiel zwar lustig sein, jedoch wird es ernst, wenn ein selbstfahrendes Auto eine folgenschwere Entscheidung trifft, die keiner ergründen kann.
Vorbild menschliches Gehirn
Die KI in ihrer heutigen Form kann viele begrenzte, gut definierbare Probleme bereits wesentlich besser lösen als der Mensch. Von einer allgemeinen Intelligenz, der »starken« KI, ist sie allerdings noch weit entfernt, und es ist noch nicht einmal klar, ob die heutigen Ansätze uns wirklich voranbringen können. Vielleicht müssen wir unser Gehirn erst besser verstehen, bevor echte Fortschritte realisierbar sind.
Der Autor

Ralph R. Dammel ist Technology Fellow im CTO-Office von Merck Electronics. Er hat 1986 an der Goethe-Universität Frankfurt in Chemie promoviert und ist Autor von mehr als 200 wissenschaftlichen Arbeiten auf dem Gebiet der Chemie und Mikrolithografie. Zudem ist er Inhaber von über 470 Patenten in 100 Patentfamilien in diesem Bereich. Seit 2009 ist Dr. Dammel SPIE Fellow.