Projekt »GreenICT – EdgeLimit«
Energieeffiziente Orchestrierung
Bei verteilten Systemen, die in der Regel aus Embedded-Systemen aufgebaut sind, unter Nutzung von Containern und einer energieeffizienten Orchestrierung Energie zu sparen und damit den CO2-Ausstoß reduzieren? Die vorgestellten Ansätze sind im Rahmen des Projekts »GreenICT – EdgeLimit« entstanden.
Das Projekt »GreenICT – EdgeLimit« behandelt Energieeinsparpotenziale in 5G Radio Units und wird vom Bundesministerium für Bildung und Forschung (BmBF) gefördert. Die Ergebnisse sind aber auf beliebige verteilte Systeme übertragbar. Davon existieren eine Menge im täglichen Einsatz.
Verteilte Embedded-Systeme
In diesem Kontext werden als »verteilte Systeme« miteinander vernetzte Prozessorsysteme verstanden, die eine mit einem Raspberry Pi vergleichbare Leistungsfähigkeit und den entsprechenden Ressourcenbedarf besitzen. Ein besonderer Schwerpunkt liegt auf SoC-FPGAs. Das sind System-on-Chips, die neben typischerweise auf auf Arm-Technologie basierenden Prozessorkernen programmierbare Hardwarestrukturen integrieren.
Die Frage ist, wie man mit dieser Art von miteinander vernetzten Embedded-Systemen Energie sparen kann. Das Sparpotenzial zeigt sich, wenn eine dieser vernetzten Komponenten nicht im Volllastbetrieb, sondern im Teillastbetrieb arbeitet. In diesem Fall besitzt sie einen schlechteren Wirkungsgrad bei der Energieaufnahme. Dies liegt daran, dass sich je nach aktueller Leistung die Energieaufnahme dieser Komponente aus einem statischen Anteil und dem dynamischen Teil zusammensetzt. Unter Volllast sieht man zwar eine maximale Leistungsaufnahme, aber das Verhältnis von Nutzleistung zur statischen Leistung ist deutlich besser als in einem Betrieb mit halber Prozessorlast. Das Ziel der energieeffizienten Orchestrierung ist, durch eine geschickte dynamische Verteilung von Applikationen über verschiedene vernetzte Knoten und die Möglichkeit einer Abschaltung von einzelnen Knoten Energie einzusparen.
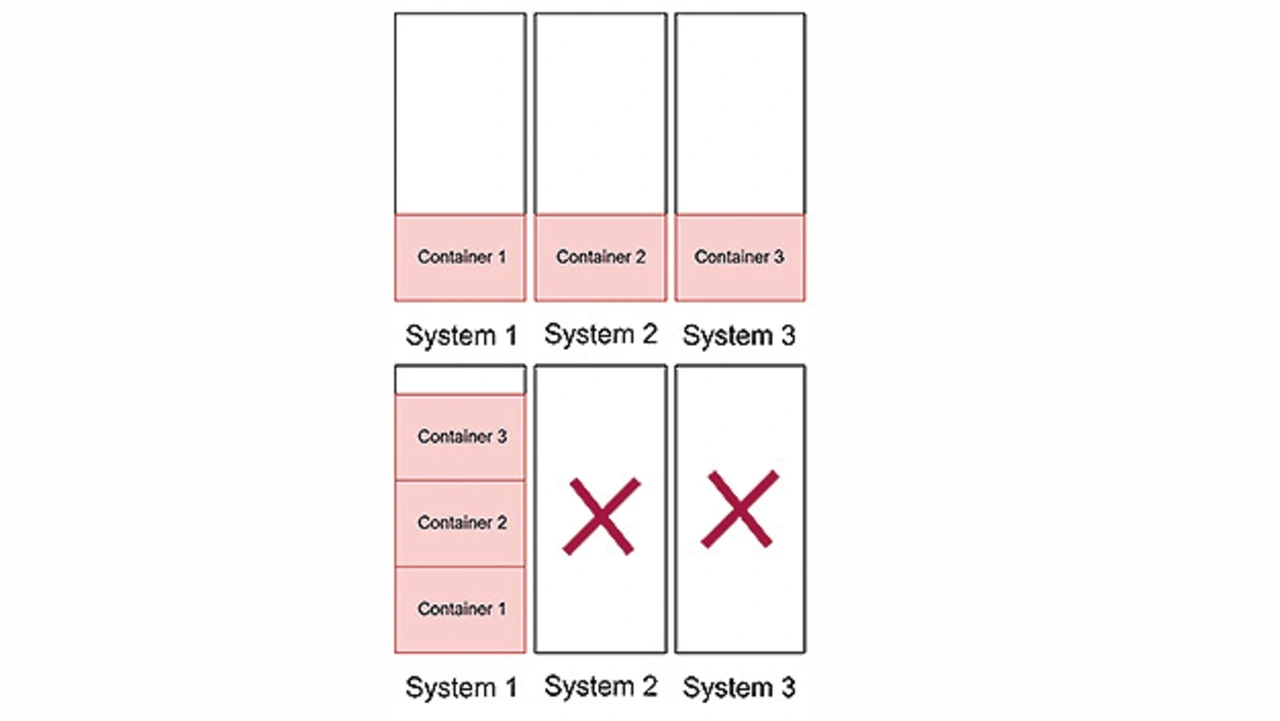
Bild 1 zeigt das Grundprinzip der Energieeinsparung durch Nutzung von Containern und energieeffizienter Orchestrierung. Bei der Orchestrierung wird darauf geachtet, dass alle Systeme möglichst nahe an der Volllast arbeiten. Software auf Systemen in Teillast werden verschoben, um das System zu leeren. Systeme im Leerlauf werden abgeschaltet. Mit dieser Vorgehensweise wird ein energetisch ineffizienter Betrieb von Einzelkomponenten vermieden.
In dem Projekt EdgeLimit geht es darum, in einem Millimeterwellen-Radio-Access-Network bei Teilauslastung Funktionen zwischen den Komponenten zu verschieben. Sobald Teile einer Radio-Unit oder die ganze Komponente abgeschaltet werden kann, beginnt die Energieeinsparung. Ähnliche Szenarien kann man sich im Produktionsbereich vorstellen. Beispielsweise wenn in einer Produktion in zwei Schichten gearbeitet wird und in der dritten Schicht entweder Wartungsarbeiten durchgeführt oder viele Systeme im Leerlauf betrieben werden.
Leistungsaufnahme unterschiedlicher verteilter Komponenten
Ein Server oder Embedded-System im Leerlauf benötigt trotz Energiesparmodi in der Regel Energie, die für keinerlei sinnvolle Funktion aufgewendet wird. Das kennt jeder im kleineren Maßstab von einem Fernsehgerät im Stand-by. Ein Arm Cortex in einem SoC-FPGA der Firma Xilinx zusammen mit den Ressourcen eines Evaluationsboard benötigt im Leerlauf 7,1 Watt. Die Leistungskennlinie über die Auslastung zeigt einen linearen Verlauf. Bei Volllast nähert sich die Leistungsaufnahme der 8-Watt-Grenze.
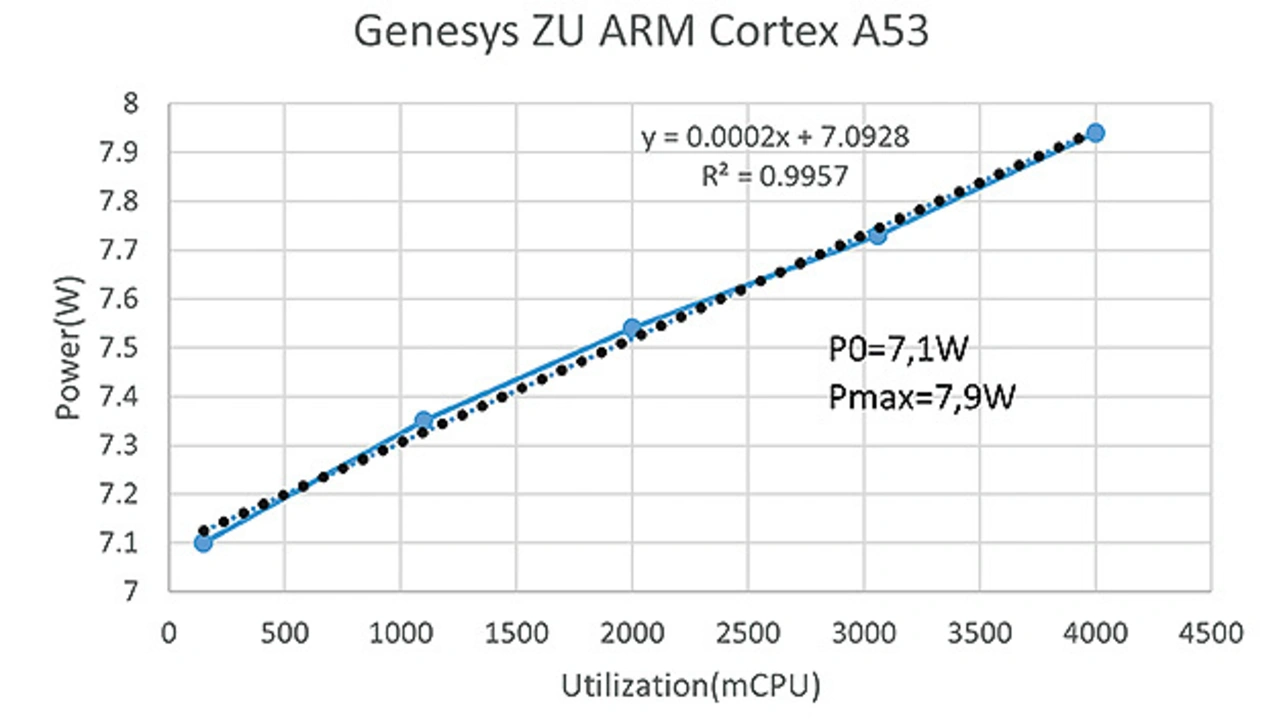
Bild 2 zeigt die gemessenen Werte einschließlich einer errechneten Regressionsgerade. Die Prozessorleistung ist in Form von milliCPU skaliert. Diese Skalierung berücksichtigt die Anzahl der genutzten Kerne. Da der Arm Cortex Core vier Kerne besitzt, läuft er unter Volllast mit 4000 milliCPU. An dieser Kurve wird deutlich, dass die Leistungsspanne zwischen Leerlauf und Volllast nur 0,8 Watt beträgt. Arbeiten in einem verteilten System mit zwei Boards beide Prozessoren mit halber Leistung, beträgt die aufgenommene Leistung circa 15 Watt. Nutzt man dagegen den Prozessor auf einem Board zu 100 % aus und schaltet das andere Board ab, liegt die Leistungsaufnahme bei 7,9 Watt. Damit wird rein rechnerisch eine Energieeinsparung von circa 50 % erreicht.
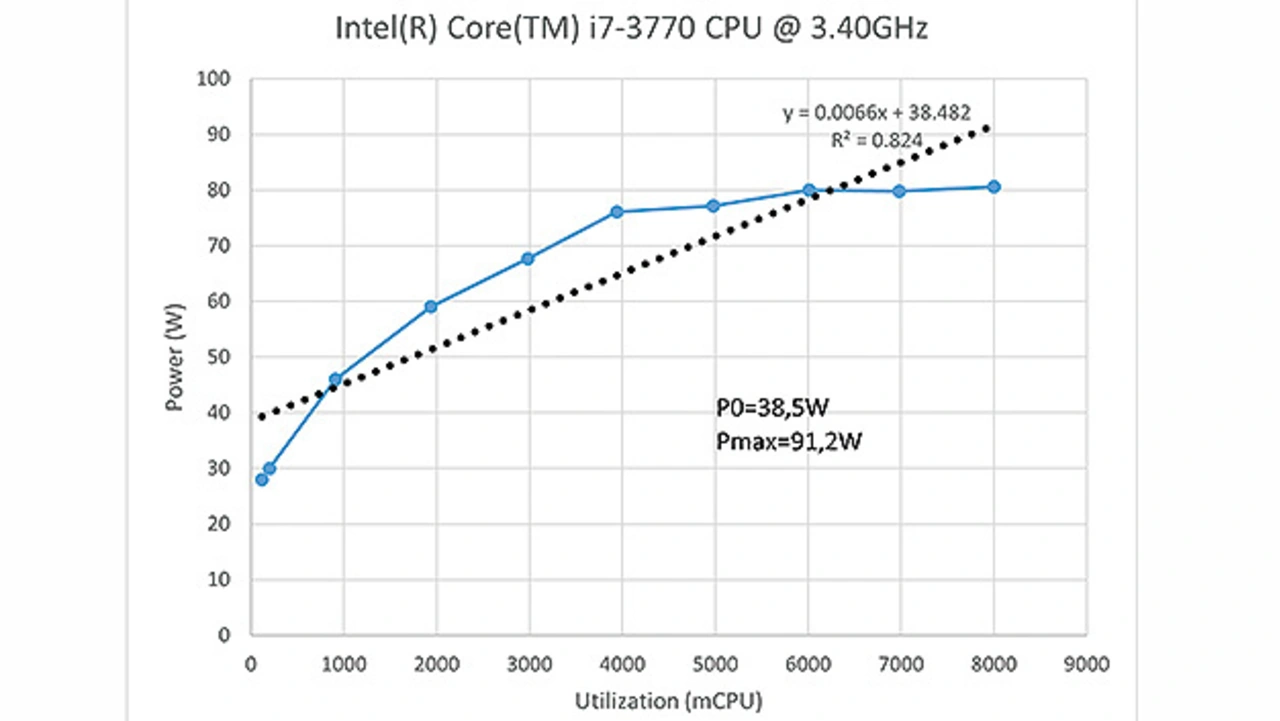
Bild 3 zeigt die Leistungskurve eines älteren Intel-i7-Prozessors zusammen mit den Ressourcen seines Motherboards. Nach Informationen des Task-Managers besitzt der Prozessor acht logische Prozessoren und vier physikalische Kerne. Bei der Betrachtung der Kurve fällt auf, dass die Leistungsaufnahme bis zu 4000 milliCPU linear ansteigt. Ab dieser Grenze generiert die Zunahme der Prozessoren keine weitere Steigerung der Leistungsaufnahme. Dies lässt sich damit erklären, dass bis 4000 milliCPU die physikalischen Kerne eingesetzt werden. Sobald diese genutzt werden, unterstützt jeder Hardwarecore zwei virtuelle Prozessoren. Der Einsatz dieser Prozessoren verbraucht keine zusätzliche elektrische Leistung. Allerdings wird auch die Rechenleistung in Summe nicht gesteigert, wie es die steigenden milliCPU-Werte suggerieren. Die minimale Leistungsaufnahme im Leerlauf beträgt in diesem System 38,5 Watt, unter Volllast beträgt die Leistungsaufnahme des Edge-Servers 91,2 Watt.
Basistechnologien
Im Folgenden werden die einzelnen Komponenten der energieeffizienten Orchestrierung auf verteilten Embedded-Systemen vorgestellt.
Das System besteht aus den folgenden Komponenten:
➔ Softwarevirtualisierung
➔ Hardwarevirtualisierung
➔ Energieeffiziente Orchestrierung
Softwarevirtualisierung
Im Rahmen des Projekts wurden unterschiedliche Container-Laufzeitumgebungen für den Einsatz auf Embedded-Systemen untersucht.
Da es für Echtzeit-Betriebssysteme keine Open-Source-Lösungen gibt, konzentrierten sich die Untersuchungen auf Linux-Lösungen. Ein wichtiges Auswahlkriterium war dabei, dass die Laufzeitumgebung leicht auf den üblichen Lightweight-Varianten von Linux installierbar ist. Beim XILINX-FPGA-SoC muss eine Installation auf PetaLinux erfolgen. Die Wahl fiel auf »containerd«.
Hardwarevirtualisierung
Der Begriff Hardwarevirtualisierung ist im Augenblick noch nicht geläufig. Diese Art von Virtualisierung setzt voraus, dass sich eine Hardware im Betrieb ändern lässt. Partiell rekonfigurierbare FPGAs unterstützen diese Vorgehensweise optimal. Bei dieser Art von Virtualisierung beinhaltet ein Softwarecontainer neben Softwarekomponenten Programmierinformationen für die verschiedenen Hardwarestrukturen. Diese werden bei Bedarf in ausgewählte Bereiche des FPGA geladen. Typische Anwendungen umfassen z. B. Koprozessoren, die mit Hardwarestrukturen ausgewählte Berechnungen im Vergleich zu einer puren Softwarelösung beschleunigen können. Dabei ist zu beachten, dass es sich um keine reine Hardwarelösung handelt. Ein Koprozessor benötigt zwingend einen Proxy in Software, der die Hardware mit Daten versorgt und das Ergebnis der Berechnung abholt.
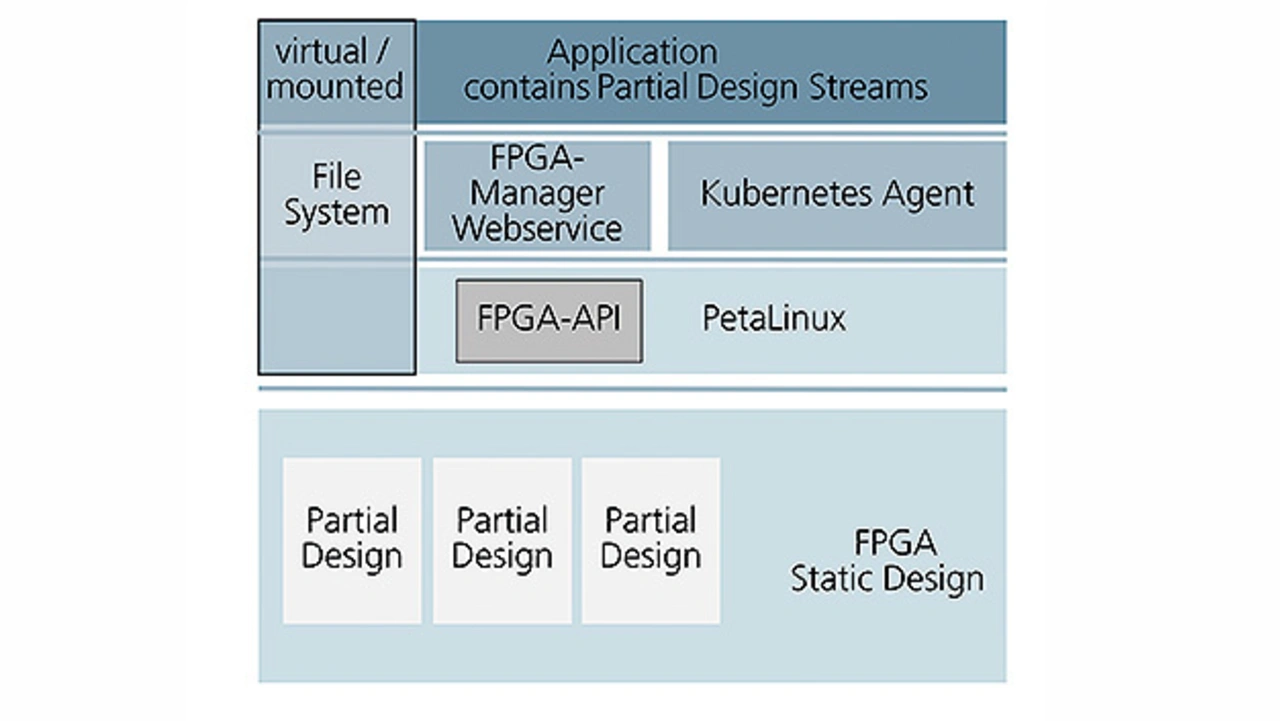
In das auf dem FPGA-SoC genutzten PetaLinux wurde ein Applikationsinterface zum FPGA integriert. Über dieses API können vom Prozessor Teilbereiche innerhalb des FPGA programmiert oder Daten an die Hardwarestruktur übergeben und gelesen werden. Für die Datenübertragung zum FPGA wurde in das Hardwaredesign ein AMBA-Businterface (Advanced Microcontroller Bus Architecture) integriert.
Der FPGA-Manager WEB-Service realisiert die Schnittstelle zwischen der Software in dem Container und dem FPGA-API. An dieser Stelle werden entweder IP-Sockets oder Pipes als Schnittstelle zur Datenübertragung genutzt. Bei den Untersuchungen zur Schnittstelle hat sich gezeigt, dass die Nutzung von Pipes deutlich performanter und damit energieeffizienter ist.
Die Applikationen arbeiten in der virtualisierten Containerumgebung. Beim Aufstarten eines Containers fragt die Software beim FPGA-Manager WEB-Service nach, ob für die zugehörige HW-Implementierung ausreichend Platz in einem partiellen Bereich des FPGA zur Verfügung steht. Wenn dies der Fall ist, wird das HW-Design in das FPGA geladen. Sind nicht ausreichend Ressourcen vorhanden, startet stattdessen eine im Container vorgehaltene Softwarekomponente.
Um die Ergebnisse der HW-Virtualisierung bewerten zu können, entstand ein Testdesign in Form eines neuronalen Netzes als der typische Vertreter eines Koprozessors. Im Anschluss wurden verschiedene Implementierungen auf ihre Leistungsfähigkeit und Energieeffizienz untersucht. Es entstanden folgende Varianten:
➔ Reine SW-Lösung im Container in Form eines C-Code für den Arm-Prozessor in dem SoC
➔ Koprozessor im FPGA wird aus der PetaLinux-Ebene bedient
➔ Reine SW-Lösung im Container unter Nutzung von optimiertem NEON-Code des Arm-Prozessors
➔ Koprozessor im FPGA wird aus dem Container bedient. Die Kommunikation erfolgt über Named Pipes
➔ Koprozessor im FPGA wird aus dem Container bedient. Die Kommunikation erfolgt über TCP/IP-Sockets in Form von WEB-Services.
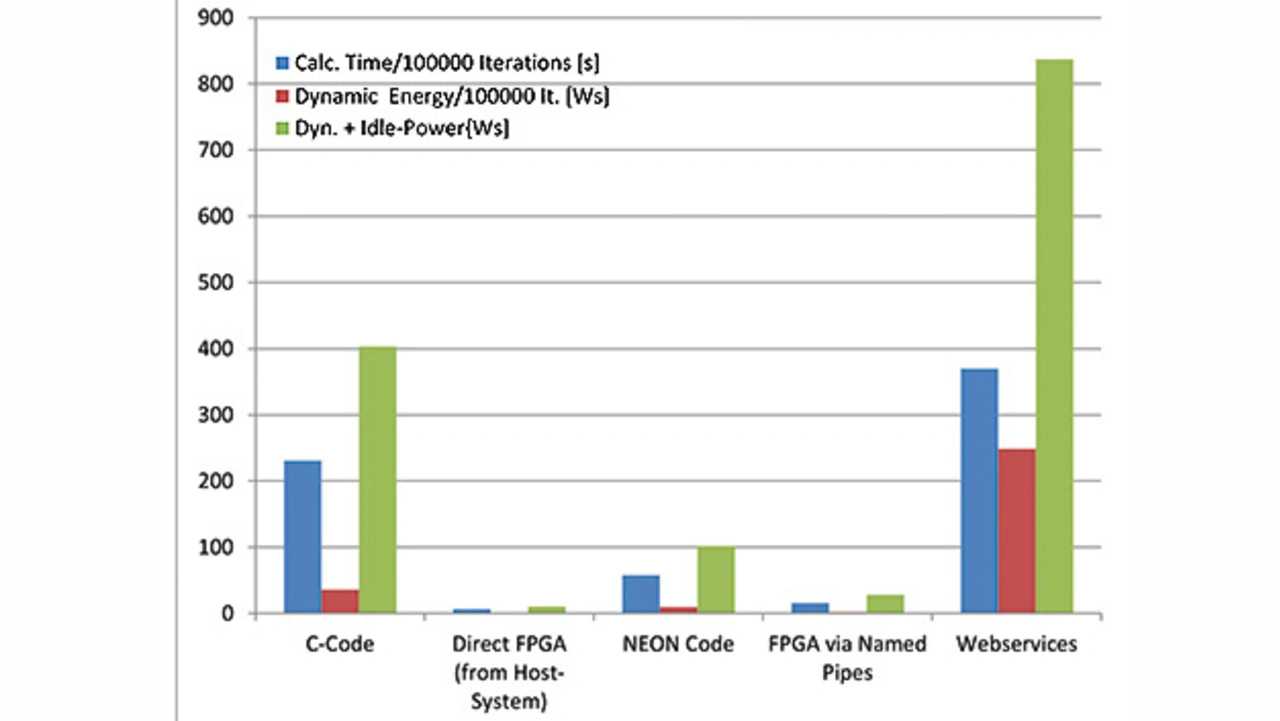
Bild 5 zeigt den Vergleich der verschiedenen Lösungen bezüglich der Rechenzeit und der dynamischen Energieaufnahme.
Das von der Performance und der Energieeffizienz beste Ergebnis liefert die Lösung, die ohne Virtualisierung direkt unter dem Betriebssystem PetaLinux arbeitet und den Koprozessor in dem FPGA-Bereich mit Daten lädt und nach der Berechnung das Ergebnis abholt. Dieses Design dient als direkter Vergleich zu einer Ansteuerung aus dem Container heraus. So kann bestimmt werden, wieviel zusätzliche elektrische Leistung und Laufzeit eine Applikation mit der gleichen Funktionalität aus dem Container heraus benötigt. Es zeigte sich, dass die Verwendung von Named Pipes die Energieaufnahme geringfügig erhöhte. Eine Nutzung von TCP/IP-Sockets führte zu einer drastischen Verschlechterung und zum schlechtesten Ergebnis. Alle reinen SW-Lösungen sind von der Performance und der Energieaufnahme deutlich schlechter als die Implementierung der HW-Virtualisierung. Damit hat sich gezeigt, dass die Nutzung einer HW-Virtualisierung zu einer deutlichen Beschleunigung der Bearbeitung verbunden mit einer signifikanten Energieeinsparung führen kann.
Jobangebote+ passend zum Thema
- Energieeffiziente Orchestrierung
- Energieeffiziente Orchestrierung