Efinix AI Solutions
»TinyML Quantum«- und »eCNN«-Accelerator
FPGAs eignen sich hervorragend für KI-Anwendungen. Efinix unterstützt diese mit zwei Ansätzen: Sapphire-SoC mit Quantum Accelerator für kleinere Modelle, eCNN für größere Netze mit über 40 Operatoren.
Künstliche Intelligenz (KI) ist längst kein exklusives Privileg von Cloud-Servern oder High-End-GPUs mehr. Mit dem Erfolg von TinyML (Tiny Machine Learning), einem Framework für die Optimierung von neuronalen Netzen für den Einsatz auf ressourcenbeschränkten Systemen, rückt die Verarbeitung von KI-Modellen direkt dorthin, wo die Daten entstehen: in die Sensoren, IoT-Geräte oder in eingebettete Systeme. Während Mikrocontroller in Bezug auf Latenz und Inference-Zeit oft an ihre Grenzen stoßen, bieten FPGAs (Field-Programmable Gate Arrays) eine flexible und energieeffiziente Alternative.
Hier kommen die AI-Lösungen von Efinix ins Spiel. Je nach Anforderungen der Applikation kann zwischen zwei verschiedenen Lösungsansätzen gewählt werden: dem Hardware-Beschleuniger »Quantum Accelerator« für das TinyML-Framework und dem Hardware-Beschleuniger »eCNN« für leistungsstärkere Designs. Mit beiden Beschleunigern können Entwicklern vortrainierte KI-Modelle direkt auf das FPGA bringen. Durch die Kombination aus quantisierten Modellen, Hardware-Beschleunigern und der Quantum-Architektur von Efinix lassen sich Latenzzeiten minimieren, der Energieverbrauch senken und gleichzeitig die Skalierbarkeit sicherstellen.

TinyML
Die Efinix TinyML AI Solution basiert auf drei zentralen Komponenten: dem TensorFlow Lite Framework als Software-Grundlage, einem RISC-V-SoC, dessen Leistungsfähigkeit an die Anwendung angepasst werden kann, und einem konfigurierbaren Quantum-Accelerator. Diese Kombination bildet nicht nur die technische Basis, sondern bietet im Zusammenspiel auch ein hochflexibles Ökosystem mit umfassenden Skalierungsmöglichkeiten. Bevor wir uns jedoch mit den Skalierungsoptionen und weiteren technischen Details beschäftigen, lohnt sich ein genauerer Blick auf das Sapphire-SoC. Je nach Anwendungsfall lässt sich das Sapphire-SoC in verschiedenen Konfigurationen einsetzen, die sich in der Art ihrer Implementierung und Performance unterscheiden. Zum einen gibt es den Sapphire Soft-Core. In dieser Implementierung wird der komplette RISC-V mit bis zu 4 Kernen in der FPGA-Logik abgebildet und kann in Titanium-FPGAs mit einer Systemfrequenz von bis zu 400 MHz betrieben werden. Wenn diese Performance nicht ausreicht, besteht die Möglichkeit, auf Efinix FPGAs mit mehr Logikelementen und »High-Performance Sapphire« umzusteigen. Hierbei handelt es sich um denselben RISC-V wie beim Soft-Core des Sapphire-SoCs, aber in diesem Fall handelt es sich um eine festverdrahtete Variante, das heißt, dieser Core ist direkt im Silizium implementiert und benötigt keine Logik-Ressourcen des FPGAs. Der High-Performance Sapphire verfügt über 4 Kerne, die mit 1GHz betrieben werden können und verbraucht dabei typisch 500 mW. Innerhalb der Efinix TinyML Solution übernimmt das Sapphire-SoC eine zentrale Rolle: Er führt die KI-Anwendung, die auf der TensorFlow Lite Micro Bibliothek basiert, aus. Der Vorteil hierbei ist, dass der Entwickler bestehende Modelle, die schon auf einem RISC-V laufen, problemlos auf die FPGAs von Efinix portieren kann. Um die Vorteile eines FPGAs – etwa die parallele Ausführung vieler Operationen – nutzen zu können, benötigt das Saphhire-SoC eine effiziente Anbindung an die FPGA-Logik. Hierfür stehen zwei Möglichkeiten zur Verfügung:
- Custom Instructions: Für benutzerdefinierte Befehle stehen in der RISC-V-ISA vier Opcodes (0x0B, 0x2B, 0x5B und 0x7B) zur Verfügung. Jeder dieser Opcodes kann mit dem 10-Bit-Function Code erweitert werden, wodurch sich 1024 effektive Befehle für jeden Opcode ergeben. Zusammen mit den zwei 32-Bit-Input- und einem 32-Bit-Output-Register können Funktionsblöcke in der FPGA-Core-Logic angesprochen und Daten übergeben werden. Mithilfe dieser flexiblen Schnittstelle können dedizierte Funktionen ausgelagert werden und die Vorteile der parallelen Verarbeitung im FPGA genutzt werden. Dies reduziert die CPU-Last und beschleunigt die Gesamtverarbeitung.
- DMA-Transfer: Wenn das neuronale Netz große Datenmengen verarbeitet, kann der »Custom-Instruction«-Ansatz durch einen effizienten Direct-Memory-Access-Mechanismus (DMA) ergänzt werden. In diesem Fall erhält der Quantum Accelerator eine Speicherschnittstelle mit einem DMA-Controller. Somit kann der Beschleuniger schnell und effektiv auf Eingangsdaten zugreifen und Ergebnisse in den Speicher schreiben.
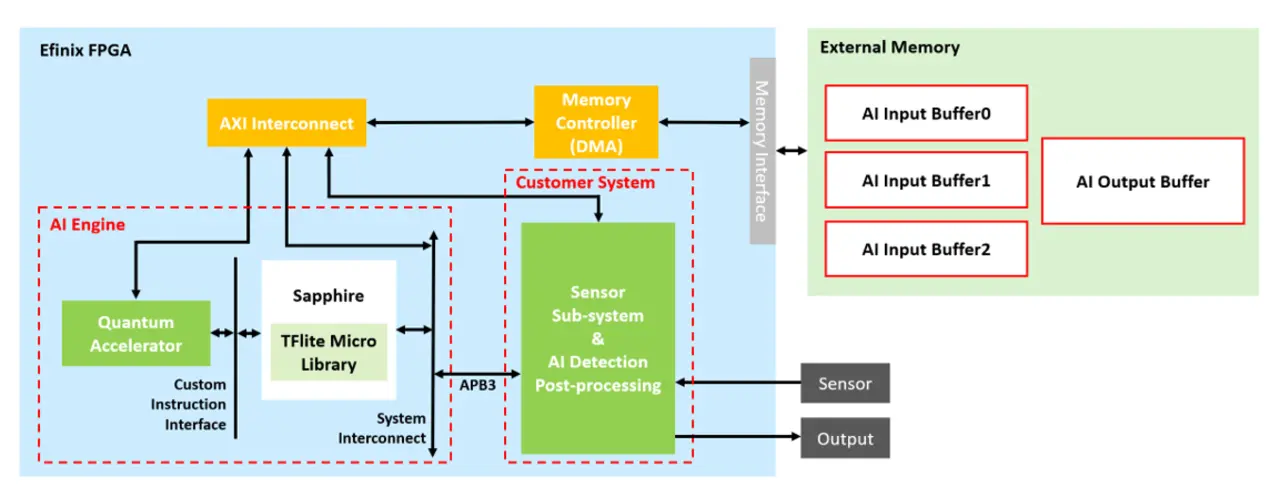
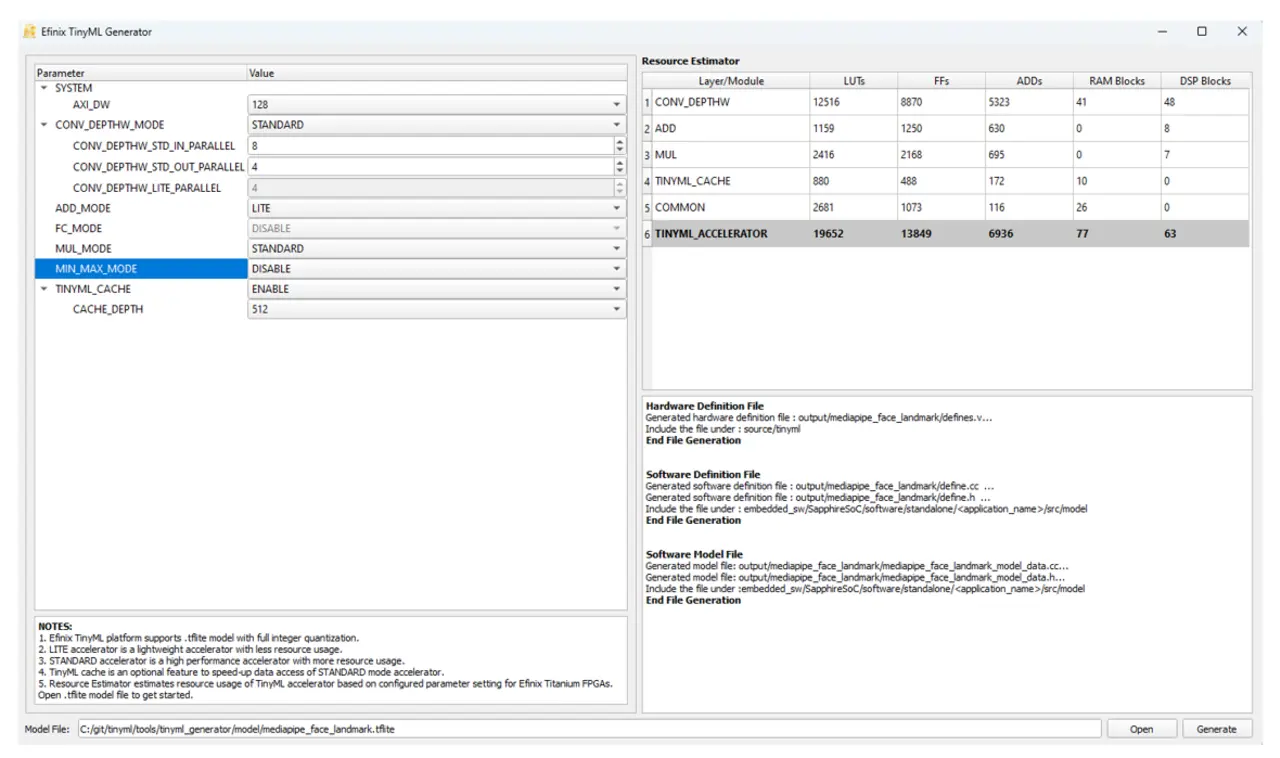
Ein zentrales Werkzeug zur Konfiguration des Quantum-Accelerators ist der Efinix TinyML Generator, der auf der GitHub-Seite von Efinix [1] frei zugänglich ist und ein trainiertes und optimiertes Modell im TensorFlow Lite-Format entgegennehmen kann. Nach der Analyse der verschiedenen Layer werden die Optimierungsmöglichkeiten entsprechend angegeben und der Nutzer kann entscheiden, was er nutzen möchte. Um die optimale Konfiguration des Quantum Accelerators für die Anwendung zu ermitteln, bietet die TensorFlow Lite Micro Library eine leistungsstarke Profiling-Funktion. Während der Laufzeit zeichnet das Profiling die Verarbeitungszeiten der einzelnen Layer des neuronalen Netzes auf und gibt diese aus. Die gewonnenen Laufzeitdaten ermöglichen eine zielgerichtete Anpassung des Accelerators über den Efinix TinyML Generator. Besonders rechenintensive Layer, wie etwa Faltungsoperationen (Convolution), lassen sich durch Beschleunigungsoptionen (z. B. CONV_DEPTHW_MODE) optimieren. Durch die Kombination aus Profiling-Ergebnissen und dem TinyML Generator können Entwickler verschiedene Konfigurationen systematisch testen, um den optimalen Kompromiss zwischen Hardware-Ressourcen und Inference-Time zu finden. Die Beispielprojekte auf der Efinix-GitHub Page [1] bieten eine ideale Grundlage, um dieses Vorgehen mit vordefinierten Modellen zu evaluieren.
Das Sapphire-SoC bietet zahlreiche Konfigurationsmöglichkeiten, etwa bei der Anzahl der CPU-Cores, der Taktfrequenz oder der Auswahl spezifischer RISC-V Extensions. In Kombination mit den anpassbaren Hardware-Funktionen des Quantum-Beschleunigers und der Auswahl verschiedener FPGA-Familien ergibt sich ein außergewöhnliches hohes Maß an Skalierbarkeit. Diese Flexibilität ermöglicht eine präzise Abstimmung zwischen Rechenleistung, Energieverbrauch und Systemkosten, sodass für jede Anwendung die optimale Balance gefunden werden kann. Da sich sowohl das Sapphire-SoC als auch der Quantum Accelerator in ihrem Funktionsumfang exakt auf das benötigte Minimum konfigurieren lassen, sinkt der Ressourcenbedarf deutlich. Dadurch lässt sich eine KI-Applikation mit Quantum Accelerator sogar in dem Titanium-FPGA Ti60W64 mit einer Fläche von lediglich 3,4 mm x 3,5 mm realisieren.
Ein anschauliches Beispiel für diese Skalierbarkeit zeigt die Implementierung der YOLO-Person-Detection-Demo (verfügbar auf GitHub [1]), die auf drei verschiedenen FPGA-Modellen getestet und optimiert wurde. Die Wahl des geeigneten FPGAs hängt dabei im Wesentlichen von den Anforderungen an die Inference-Zeit und die resultierende Framerate ab. Für Anwendungen mit moderaten Performance-Anforderungen eignet sich der Titanium Ti60, der mit einer Verlustleistung von unter 400 mW überzeugt. In dieser Konfiguration läuft der Sapphire RISC-V mit 4 Kernen mit 350 MHz. Sobald höhere Frameraten gefordert sind, können Entwickler auf leistungsfähigere FPGAs wie den Ti180 oder den Ti375 zurückgreifen, die über deutlich mehr Logikelemente verfügen. Dadurch stehen zusätzliche Ressourcen für die Konfiguration des Efinix Quantum Accelerators zur Verfügung. Beim Ti180 steht dem Entwickler weiterhin der Soft-RISC-V im Zusammenspiel mit dem Accelerator zur Verfügung. Beim Ti375 kommt zusätzlich zu der höheren Anzahl an Logikelementen auch der High-Performance Sapphire mit bis zu 1GHz und vier Kernen als Option dazu.
Bemerkenswert ist, dass der Anstieg der Leistungsaufnahme bei diesen größeren FPGAs nicht proportional zur Performance-Steigerung ausfällt. Darüber hinaus ermöglicht eine gezielte Reduzierung der Systemfrequenz selbst bei größeren FPGAs eine weitere Optimierung des Energieverbrauchs.

Diese flexible Skalierbarkeit macht die Efinix-AI-Lösung besonders attraktiv für Edge-Anwendungen, bei denen eine effiziente Ressourcennutzung entscheidend ist - sei es in batteriebetriebenen Geräten, industriellen Echtzeitsystemen oder kostensensiblen Massenanwendungen. Die Möglichkeit, Performance und Energieverbrauch präzise an die jeweiligen Anforderungen anzupassen, ohne damit die Flexibilität des Gesamtsystems einzuschränken, stellt einen entscheidenden Vorteil gegenüber anderen Hardware Lösungen dar.
eCNN
Für Anwendungen, in denen der kostenfreie Efinix TinyML-Ansatz an seine Leistungsgrenzen stößt, bietet Efinix mit dem eCNN IP-Core eine weitere skalierbare Hardware-Lösung zur Beschleunigung von neuronalen Netzen. Der lizenzpflichtige Accelerator integriert sich nahtlos in etablierte Open-Source-Ökosysteme wie PyTorch, TensorFlow, ONNX oder Caffe und nutzt den kostenfreien Buildflow von Efinix.
Der eCNN-Accelerator unterstützt über 40 gängige Operatoren von neuronalen Netzen (u.a. Convolution, DepthToSpace, ReLU, Reshape), was deutlich kürzere Inferenzzeiten gegenüber rein Software-basierten Ansätzen ermöglicht. Der Workflow beginnt mit der Quantisierung des vortrainierten Modells in das INT8 Datenformat. Dazu können gängige Open-Source Frameworks wie TensorFlow oder PyTorch genutzt werden. Anschließend wird das Modell mit bereitgestellten Tools in ein binäres Format überführt, damit es im DRAM abgelegt werden kann. Da der Beschleuniger über eine integrierte Data Processing Unit (DPU) verfügt, ist kein zusätzlicher Prozessor notwendig. Die Steuerung erfolgt über AXI4-Lite-/APB3-Interface mit einfachen Kommandos wie Start und Stop. Ein-/Ausgabedaten sowie DPU-Firmware und Modelldaten liegen im DRAM und werden über AXI4 übertragen.
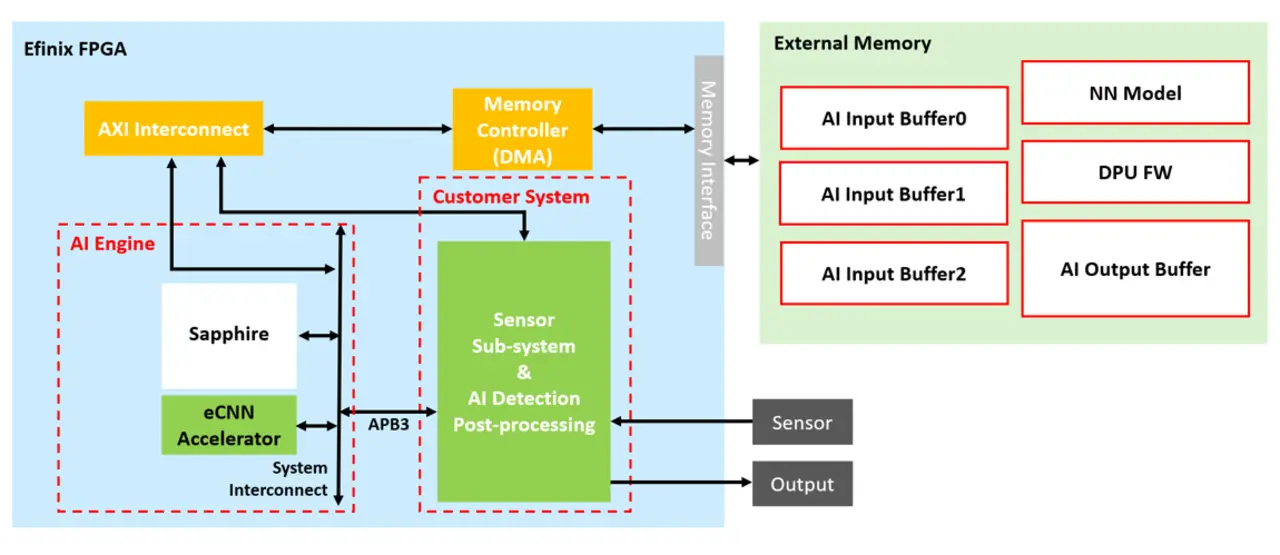
Auch der eCNN-Ansatz kann skaliert werden. Dies erfolgt durch die mehrfache Instanziierung des eCNN-Cores. Jeder Core beansprucht ca. 35k XLR Zellen, 1 MB RAM und 80 DSP-Blöcke im Efinix-FPGA.
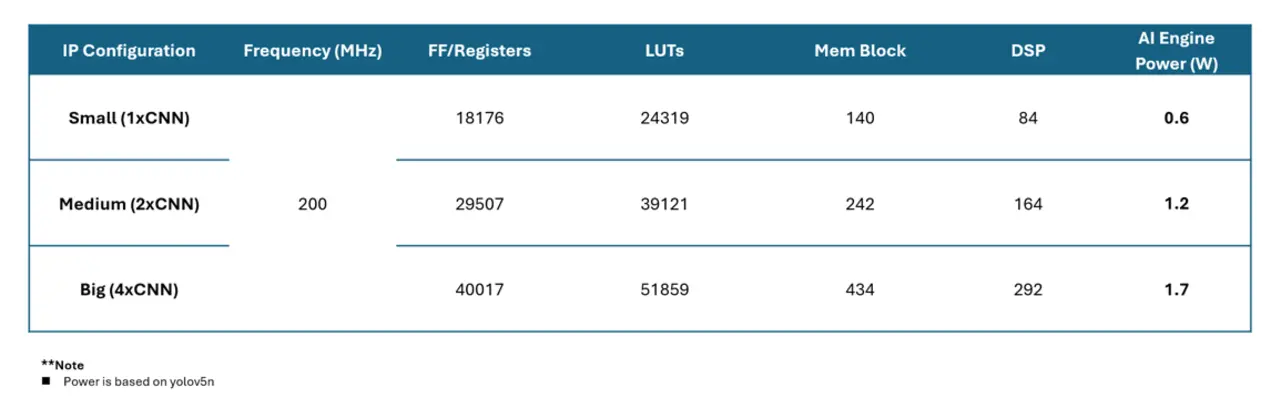
Bei eCNN können bis zu acht Cores kombiniert werden, was eine Rechenleistung von 1,8 TOPS (INT8) ergibt. Im Vergleich zum Efinix TinyML Ansatz ermöglicht der eCNN Accelerator den dynamischen Austausch von Modellen zur Laufzeit. Zur Beschleunigung der Entwicklung stellt Efinix vortrainierte und optimierte Referenzmodelle bereit. Nachfolgend sind Leistungsbeispiele für den Einsatz von vier eCNN-Cores bei einer Frequenz von 200 MHz aufgeführt. Der Energiebedarf liegt dabei bei lediglich 600 mW pro Unit (gemessen bei Yolov5n).

Im Vergleich zu Lösungen anderer FPGA-Hersteller mit Deep-Learning-Processor-Units (DPU), benötigt der eCNN Accelerator ca. 30 Prozent weniger FPGA-Ressourcen bei doppelter Effizienz in der Ausführung. Gegenüber generalistischen Embedded AI-SoCs (System-on-Chip) bietet der FPGA-basierte Ansatz von Efinix ein um 50 Prozent besseres Performance-Verlustleistungsverhältnis (verifiziert mit tiny_yolov3). Der eCNN IP-Core eignet sich für Echtzeit-Objekterkennung (z. B. Traffic Monitoring, Überwachungssysteme), Bildverbesserung (Upscaling in Thermal Imaging oder Security-Kameras) und industrielle Inspektion (Defekterkennung und -segmentierung in Fertigungslinien). Der eCNN Accelerator von Efinix adressiert die Lücke zwischen dem Efinix TinyML-Ansatz und spezialisierten AI-SoCs. Durch FPGA-spezifische Skalierbarkeit, geringe Latenz und Energieeffizienz ermöglicht er den Einsatz komplexer neuronaler Netze in Edge-Szenarien, ohne Kompromisse bei der Integration in bestehende KI-Workflows einzugehen.
Die Efinix AI Solutions mit TinyML Quantum Accelerator und eCNN IP-Core bieten Entwicklern alle Werkzeuge, um KI-Modelle effizient auf FPGAs zu implementieren, auch ohne eine Zeile RTL-Code zu schreiben.
Referenzen:
- [1] https://github.com/Efinix-Inc/tinyml
- [2] https://www.efinixinc.com/blog/blog-2023-risc-v-custom-instruction.html