Open-Source Hardware
Turbo für RISC-V-Prozessorkern
Für seine Flash-Speicher-Laufwerke (SSD, Solid State Disk) hat Western Digital einen RISC-V-Prozessorkern entwickelt: SweRV EH1. Dank einer neunstufigen Pipeline, mit zwei parallelen Pfaden, erreicht er die aktuell höchste Rechenleistung für Open-Source-RISC-V-Prozessorkerne.
Die RISC-V-Befehlssatzarchitektur (ISA, Instruktion Set Architecture) ist zu einem wichtigen Treiber für Open-Source-Hardware-Projekte geworden. In jüngster Zeit wurden viele Anwendungen auf der Basis von RISC-V vorgestellt, z.B. im Bereich des Internets der Dinge (IoT) und im Bereich Mikrocontroller für eine Vielzahl traditioneller eingebetteter Systeme und Anwendungen, die die Fähigkeit zum Betrieb von Inferenzmaschinen der künstlichen Intelligenz (KI) mit geringer Leistung auf der Basis von künstlichen neuronalen Netzen erfordern.
In den vergangen drei Jahren gab es dementsprechend eine rege Aktivität im Bereich der Open-Source-Hardware-Implementierungen auf Basis der RISC-V-Befehlssatzarchitektur [1, 2, 3]. Die RISC-V-Architektur ermöglicht eine Vielzahl von leistungsoptimierten Mikroarchitektur-Implementierungen für viele Rechenprobleme, die von einem IoT-Controller bis zu einem Rechenzentrumsprozessor reichen. Für alle diese Anwendungen können Entwickler die wichtigsten gängigen Open-Source-Softwarekomponenten wie Open-Source-Compiler, Debugger, Echtzeit-Betriebssysteme (RTOS) für Embedded-Systeme und allgegenwärtige Betriebssysteme wie Linux nutzen.
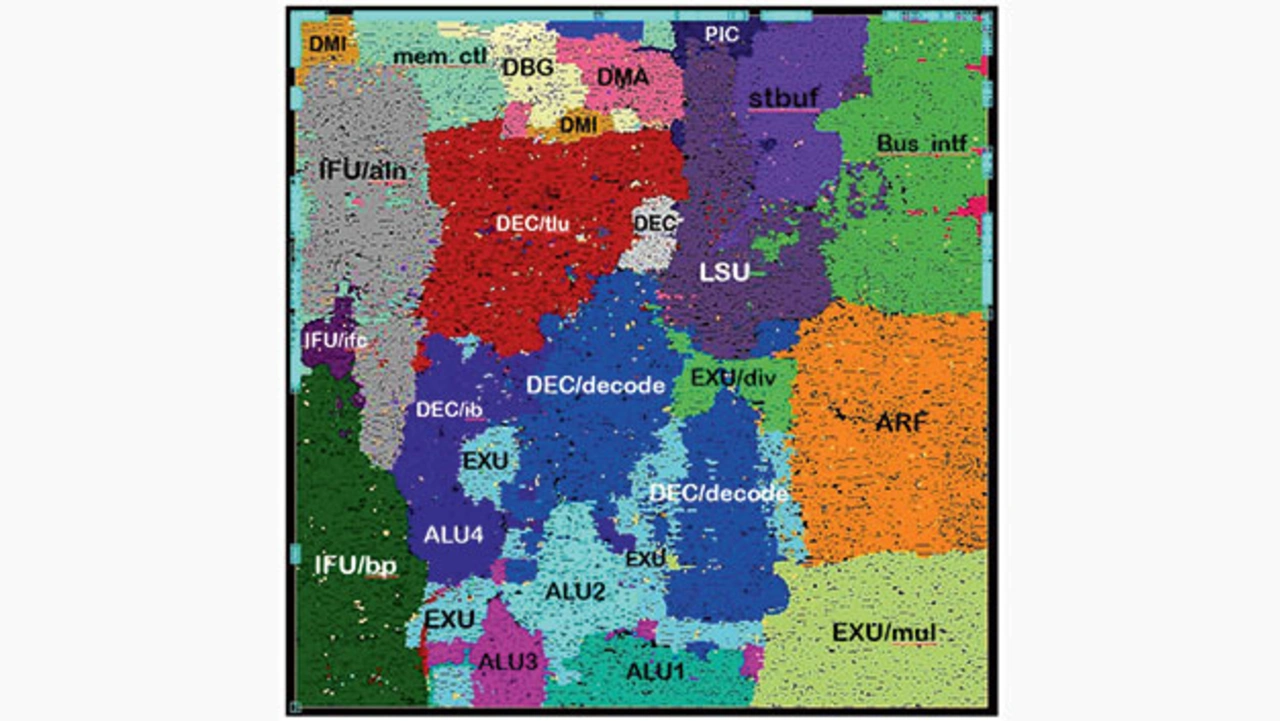
Western Digital hat einen superskalaren (zwei Wege) Prozessorkern mit neunstufiger Pipeline entwickelt, der größtenteils auf dem RISC-V-Befehlssatz RV32IMC basiert und SweRV EH1 heißt. Es handelt sich um einen Hochleistungs-Prozessorkern zum einbetten in SoCs, der im 28-nm-Prozess von TSMC implementiert wurde. Der RTL-Code für SweRV EH1 ist auf der Plattform von GitHub unter Open-Source-Lizenz verfügbar [4].
Der Prozessorkern SweRV EH1 ist für die Implementierung in SoCs für NAND-Flash-Controller vorgesehen (Bild 1). Die Ziel-Halbleitertechnik ist der 28-nm-Prozess von TSMC (125C, 150 ps Taktversatz). Die Si-Fläche für eine Implementierung, ohne Speicher, im Prozessbereich SSG (Slow Global) beträgt 0,132 mm2 bei 1 GHz und 0,093 mm2 bei 500 MHz. Wird der typische Prozessbereich gewählt (TTG, Typical Global) beträgt der Flächenbedarf für die Implementierung 0,092 mm2 bei 1 GHz und 0,088 mm2 bei 500 MHz.
Die Mikroarchitektur des SweRV-EH1-Kerns
Western Digital benötigt für seine Embedded-Anwendung, Speicher-Controller, keinen 64-bit-Speicheradressraum. Daher fiel die Entscheidung zugunsten einer 32-bit-Architektur. Allerdings benötigt diese Anwendung eine Unterstützung für Multiplikation/Dividieren (M) und komprimierte Befehle (C). Ausgewählt wurde schließlich die RISC-V-ISA-Variante RV32IMC.
Die Mikroarchitektur des SweRV-EH1-Prozessorkerns ist in Bild 2 dargestellt. Der Kern ist eine superskalare, neunstufige Pipeline, die vier arithmetische Logikeinheiten (ALU) mit der Bezeichnung EX1 und EX4 in jeweils zwei Pipelines I0 und I1 unterstützt. Außerdem enthält der Prozessorkern eine Lade-/Speicher-Pipeline, eine Multiplikator-Pipeline und einen Out-of-Pipeline-34-Zyklus-Latenzteiler.
Im Vergleich zu früheren Open-Source-RISC-V-Prozessorkernen wie Rocket [5] oder Pulpino [6], die eine klassische »ein Befehl pro Taktzyklus« (skalare) Pipeline verwendeten, wurde für SweRV EH1 eine superskalare »zwei Befehle pro Taktzyklus«-Mikroarchitektur gewählt. Dual-Issue-Pipelines verbessern verschiedene Leistungskennwerte (Benchmarks) typischerweise um 20–30 % [7], bei relativ geringen Kosten in der Produktion, hinsichtlich Anzahl der Gatter oder der Implementierungsfläche.
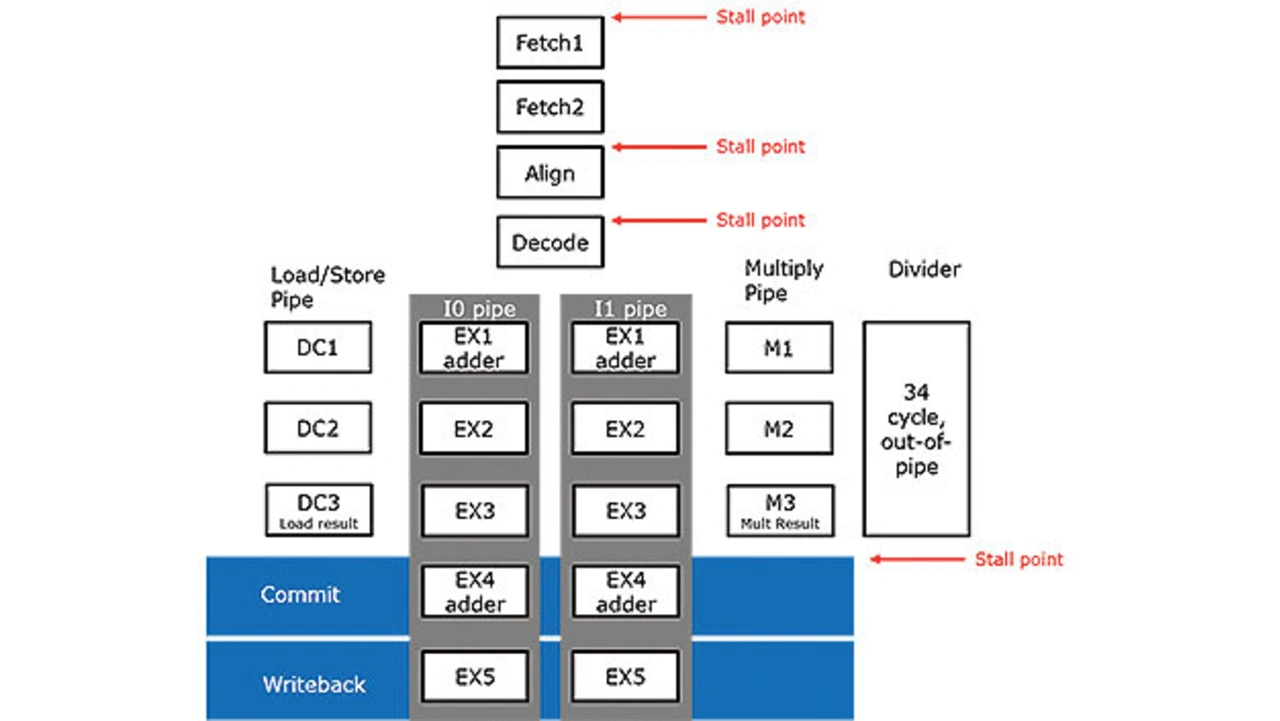
Nach den Recherchen von Western Digital ist der SweRV-EH1-Prozessorkern der erste superskalare RISC-V-Prozessorkern mit statischem Scheduling für SoCs, dessen RTL-Code als Open Source verfügbar ist [4]. Die in Bild 2 gezeigte Pipeline hat neun Stufen, einschließlich Rückschreiben. Es gibt insgesamt vier Haltepunkte (Stall Point) in der Pipeline: Fetch1, Align, Decode und Commit. Align bildet Anweisungen aus drei Fetch-Puffern. Decode dekodiert bis zu zwei Befehle aus vier Befehlspuffern. Commit wird bis zu zwei Instruktionen pro Zyklus übergeben, abhängig von der Arbeitslast.
Neben der doppelten Befehlsausgabe besteht ein Unterschied des SweRV-EH1-Kerns im Vergleich zu früheren RISC-V-Open-Source-Kernen [5, 6] im Vorhandensein von vier symmetrischen ALUs, die statisch den Pipelines I0 und I1 zugeordnet sind.
Die Lade-/Speicher-Pipeline hat eine Load-to-Use-Latenzzeit von zwei Zyklen für abhängige Lade-/Speicher-Adressen, z.B. Pointer-Chasing. Bei abhängigen ALU-Anweisungen variiert die Load-to-Use-Latenzzeit zwischen null und drei Zyklen. Dies bedeutet, dass arithmetische Operationen, die die erste Gelegenheit zur Berechnung in der EX1-Stufe verpassen, eine zweite Gelegenheit in der EX4 (Commit) erhalten können (Bild 2), was zu einer hohen Auslastung der Pipeline führt.

Zur Illustration dient der im Listing gezeigte Ausschnitt aus dem RISC-V-Assembler-Code. Die Befehlsabhängigkeiten sind in den Kommentaren dargestellt, z.B. add immediate instruction (addi) A4: verweist auf das Register x13, das mit dem Befehl L2 geladen wurde.
Die Ausführung der Pipeline des SweRV-EH1-Prozessorkerns ist in der Tabelle dargestellt. Wenn der Befehl A4 die Stufe EX1 in der Pipeline erreicht, ist im Taktzyklus vier das Register x13 nicht bereit, da der Ladevorgang des Befehls L2 zwei Taktzyklen dauern würde und das Register erst im Taktzyklus fünf geladen wird.

A4 setzt jedoch seinen Weg durch die Pipeline fort, und sobald der Befehl die Stufe EX4 erreicht, kann er ausgeführt werden – in der Tabelle rot dargestellt – da inzwischen der Befehl L2 geladen wurde und das Register x13 bereit ist.
Zusätzlich sind einige minimale Ausführungen mit dynamischem Scheduling möglich. Wenn die Ladeanweisung fehlschlägt und Zugriff auf den langsameren Speicher in der Hierarchie erfordert, wird die Ausführung bis zur nächsten Anweisung fortgesetzt, die von den Daten dieser Ladeanweisung abhängt.
Jobangebote+ passend zum Thema
- Turbo für RISC-V-Prozessorkern
- Speicher, Debug Controller und Platform Interrupt Controller