KI-Beschleuniger
Wenn »TOPS« in die Irre führen
KI-Beschleuniger werden häufig mit dem Leistungsmerkmal »TOPS« – Trillion Operations per Second – charakterisiert. Das allein reicht aber nicht aus. Es ist wichtig, zu wissen, wie diese Beschleuniger arbeiten und was bei einem Vergleich zu beachten ist.
Hardwarebeschleuniger für Künstliche Intelligenz haben viele Namen. Bekannt sind sie unter Bezeichnungen wie Neural Accelerator, AI Accelerator, Deep Learning Accelerator, Neural Processing Unit (NPU), Tensor Processing Unit (TPU), Neural Compute Unit (NCU), etc. Alle bezeichnen das Gleiche: Eine Elektronik, die auf Matrix-Operationen optimiert ist, welche benötigt werden, um Neuronale Netze der Künstlichen Intelligenz (KI) besonders effektiv zu berechnen. In den Jahren zuvor haben vor allem die GPUs von Nvidia das KI-Feld dominiert. Mit der zunehmenden Ausweitung des KI- Bereichs auf die Edge (mobile Endgeräte, industrielle End-Hardware, etc.) werden seit einigen Jahren dedizierte Hardware-Komponenten für Edge-Produkte entwickelt. Diese fokussieren sich vor allem auf Low-Precision-Berechnungen (meist Integer), moderne Datenfluss-Architekturen und eine optimale Speicheranbindung. Im Folgenden heißen sie einheitlich NPUs.
Was sind TOPS?
Um die verschiedenen Architekturen der NPUs auf einfache Weise vergleichen zu können, wurde die Metrik »Trillion Operations per Second« (TOPS) ins Leben gerufen. Unter Fachleuten gilt die Metrik nicht als der Weisheit letzter Schluss, aber sie fasst eine komplexe Fragestellung in eine einfach zu verstehende und vergleichbare Zahl. Wie viele mathematische Operationen kann mein Chip in einer Sekunde liefern? Mit dieser Zahl lassen sich die unter-schiedlichen Chips schnell vergleichen. Die Qualität der Operationen oder auch, um welche Operationen im Genaueren es sich handelt, wird nicht in Betracht gezogen. In vielen Fällen fokussieren sich die Chips auch auf eine bestimmte Aufgabe, bei der sie dann ihre maximale Leistung abrufen können. Ein direkter Vergleich ist demnach nicht immer gerechtfertigt.
| i.MX 8M Plus | Lightspeeur 2803S |
|---|---|
| 2,3 TOPS | 16,8 TOPS |
| elQ-Library | Gyr SKD/MDK |
| elQ-Library | Tensorflow, Caffe |
| CNN, RNN, ML, ... | CNN |
| Alle Modelltypen | VGG, ResNet, MobileNet |
| Langzeitverfügbar (15 Jahre) | Verfügbarkeit nicht garantiert |
Tabelle 1: Vergleich NXP vs. Gyrfalcon.
Gemessen werden die TOPS in den meisten Fällen mit dem Klassiker »ResNet50«. Das ResNet50 wird mittlerweile in Applikationen durch modernere Netzwerke ersetzt. Nichtsdestotrotz bietet es eine gute Grundlage für einen Vergleich.
Universell oder spezialisiert
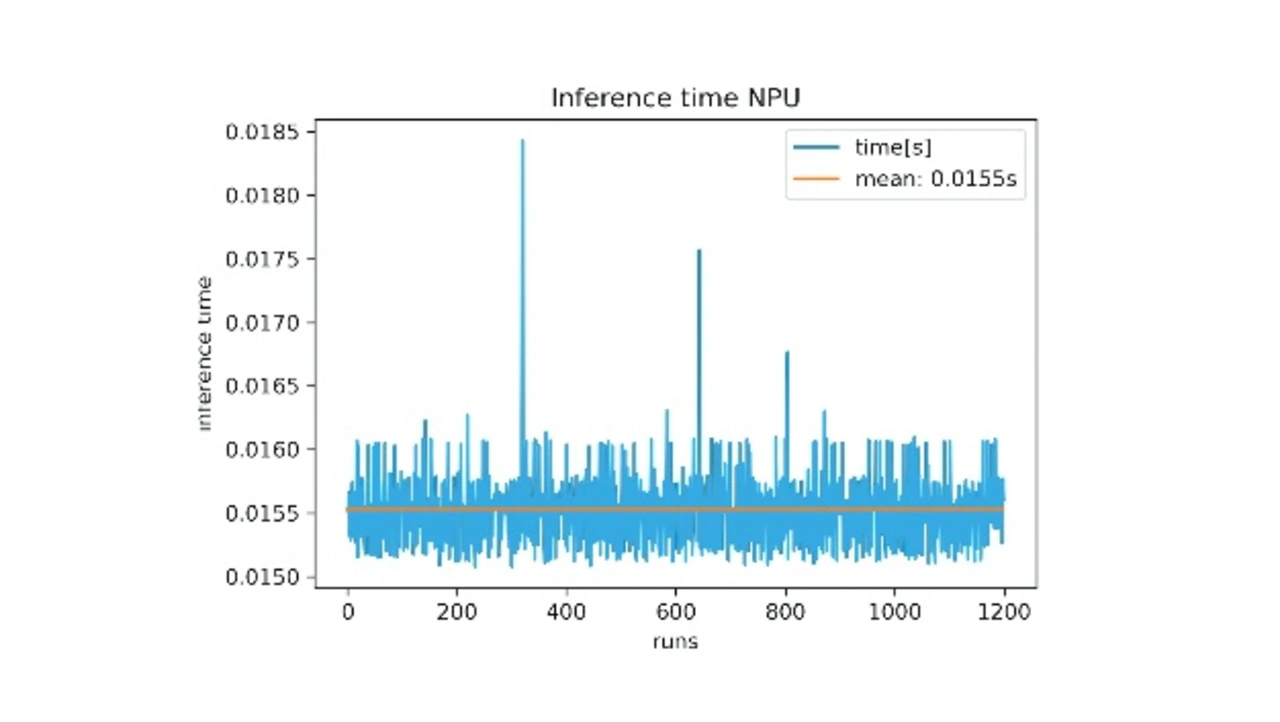
Der Single-Board-Computer phyBOARD-Pollux (Bild 1) basiert auf dem Prozessor i.MX 8M Plus Quad von NXP. Die NPU des i.MX 8M Plus ist mit 2,3 TOPS angegeben. Das allein sagt aber noch wenig über den Datendurchsatz aus, der dadurch erreicht werden kann. Ein Bildverarbeitungstest dieser NPU mit einem ResNet50 ergab einen Durchsatz von 60+ frames per second (fps) bei einer durchschnittlichen Inferenzzeit von 16 ms pro Bild (224 × 224 px), siehe Bild 2. NXP selbst gibt für das kleinere MobilNet eine Inferenz-Zeit von rund 3 ms an.
Im Vergleich zwischen dem i.MX 8M Plus von NXP und dem Lightspeeur 2803s von Gyrfalcon wird klar, dass Letzterer dem 8M Plus an TOPS deutlich überlegen ist. Wenn jedoch die Details betrachtet werden, erkennt man, dass die Chips nicht nur anhand der TOPS verglichen werden sollten und beide ihr berechtigtes Einsatzgebiet haben (Tabelle 1).

Ein großer Pluspunkt des i.MX 8M Plus ist die Bereitstellung der eIQ Library von NXP. Diese sorgt für die Anbindung des Modells beziehungsweise des neuronalen Netzes an die NPU. eIQ unterstützt TensorFlow Lite, PyTorch, und ONNX-Modelle direkt und sorgt für eine reibungslose Implementierung der Modelle auf der Embedded-Hardware. Für eIQ reicht eine simple Konvertierung und Quantisierung in TensorFlow Lite, um das Modell der NPU bereitzustellen.
Bei Gyrfalcon hingegen ist die Implementierung über ein MDK und SDK (Model- und Software-Development-Kit) umständlicher. Eine einfache Implementierung sollte nicht unterschätzt werden, da eine einfache Adaption des Modells mehr Zeit für Applikation und Modell-Entwicklung lässt und damit schnellere Iterationen im agilen Modus ermöglicht.
Ein weiterer Unterschied ist, dass der i.MX 8M Plus alle derzeitigen Modelltypen und -architekturen unterstützt. Der Gyrfalcon hingegen fokussiert sich auf Convolutional-Neural-Networks (CNN), die für die Bildverarbeitung verwendet werden. Dabei wird beim Gyrfalcon auch nur eine Architekturauswahl aus den drei wichtigsten Modellen unterstützt, dem VGG, ResNet und MobileNet. Diese sind drei häufig eingesetzte Basisarchitekturen, jedoch werden angepasste Modelle, moderne Architekturen sowie andere Typen an Netzwerken (zum Beispiel recurrent/rückgekoppelte Neuronale Netze) hierbei vernachlässigt. Durch diesen Fokus wird das Erreichen der TOPS durch den Gyrfalcon ermöglicht.
Ein entscheidender Faktor für viele Industrie-Anwendungen ist die Langzeitverfügbarkeit des i.MX 8M Plus. Edge-Geräte in Industrieanlagen sollen oft über Jahre wartungsarm und unter speziellen Bedingungen laufen. Hier ist der Gyrfalcon eher für Anwendungen aus dem Consumer-Bereich geeignet, wo man von Gerätelaufzeiten von zwei bis drei Jahren bei handelsüblicher Nutzung ausgehen kann. Eine Verfügbarkeit über ein Jahr hinaus wird momentan nicht gewährleistet. Bei dem neuen i.MX 8M Plus wird von einer Langzeitverfügbarkeit von mehr als zehn Jahren ausgegangen.
Mit den beschriebenen Punkten sieht man, dass beide Chips einen anderen Fokus und eine andere Zielgruppe haben. Ein reiner Vergleich durch die TOPS wäre hier irreführend. Der i.MX 8M Plus ist eher ein Universalchip, der vielseitig einsetzbar ist, wohingegen der Gyrfalcon für eng definierte Anwendungen mit hohen Leistungsanforderungen geeignet ist.
Wann brauche ich die TOPS?
Die Frage stellt sich unter dem Gesichtspunkt, wann der Gyrfalcon dem i.MX 8M Plus wirklich überlegen ist. Schnell fallen einem hohe frames per second ein, bei denen eher mehr als weniger TOPS bevorzugt werden. Jedoch muss einem bewusst sein, dass die meisten Kameras nur 30 bis 60 fps liefern können. Hier wäre der i.MX 8M Plus, selbst mit einem etwas schwerfälligen ResNet50, noch vollkommen ausreichend.
Batch-Processing, bei dem ein Bildstrom verarbeitet wird, wird ebenfalls oft mit TOPS in Verbindung gebracht. Batch-Processing nutzt man jedoch eher im Training von neuronalen Netzen. Bei der klassischen Inferenz wird ein Bild nach dem anderen verarbeitet, das heißt, eine Batch von eins.
Wo tatsächlich viele TOPS zum Tragen kommen, ist die »Real-Time-critical«-Applikation, insbesondere im Bereich des autonomen Fahrens. Massive Rechenleistung in Form von TOPS sind nötig, wenn in weniger als eine Millisekunde, bei 360 Grad Multistream und pixelgenau erkannt werden soll, ob etwa ein Kind auf die Fahrbahn läuft. Hier ist zum Beispiel der Gyrfalcon definitiv die richtige Wahl.
Grundsätzlich zu bedenken ist, dass die reine Inferenz nicht die einzige Aufgabe in einer KI-Applikation ist. In vielen Fällen muss mindestens noch eine Datenvorverarbeitung und eine Verwendung der Ergebnisse stattfinden. Übermäßig viele TOPS haben keinen Einfluss, wenn die NPU nicht mit genügend Daten versorgt wird. Eine gut durchprogrammierte und schlanke Applikation ist erstmal mehr wert als eine hochgetunte NPU. Beides kombiniert, lässt natürliche Barrieren fallen.
Der Gesamteindruck entscheidet
Reine TOPS geben kein vollständiges Bild, ob eine NPU für die geplante Anwendung geeignet ist. Die Unterstützung verschiedener Modelle und vor allem die reibungslose Implementierung der Modelle auf dem Chip sind mindestens von ebenso großer Bedeutung wie die reine Leistung.
Ebenfalls muss bedacht werden, dass die Hardware sowie die umgebende Software-Applikation die NPU-Leistung überhaupt ausreizen beziehungsweise bedienen kann. Eine nicht optimierte Software-Applikation kann nicht durch mehr TOPS aufgefangen werden. Grundsätzlich gilt: Die NPU muss in das Gesamtkonzept passen. Dabei ist TOPS nur eine von vielen Kennziffern.
Bei der Frage, ob nun eine TPU nötig ist, kann man sich an Folgendem orientieren: Gibt es eine Aufgabe, die »klassisches Machine-Learning« bewältigen kann (support vector machine, tree learner, …), reicht in vielen Fällen der Einsatz einer CPU aus. Sobald es zum Einsatz von Deep-Learning-Architekturen kommt, empfiehlt sich die Verwendung einer NPU.
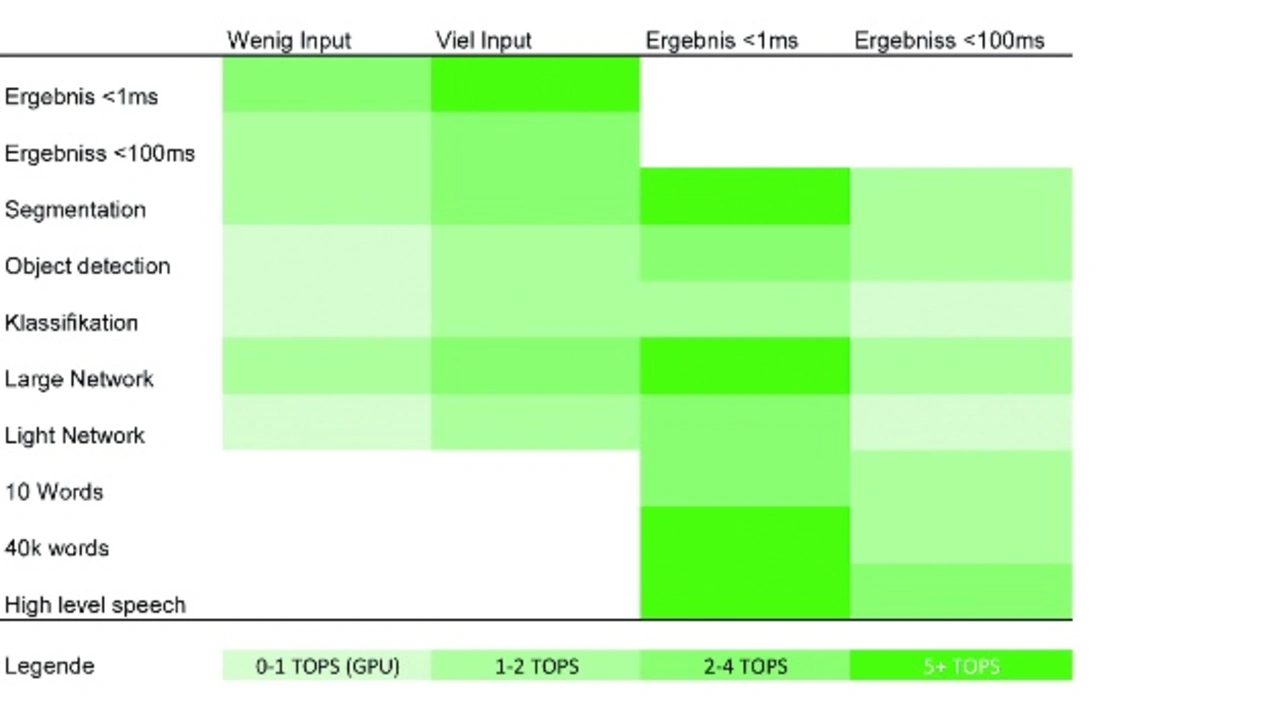
Bei der Frage nach der Anzahl an benötigten TOPS kann man sich grob an folgende Richtlinie halten: Fallen große Input-Daten an, zum Beispiel eine Bildverarbeitungs-Anwendung mit HD-Bildern, und sind Ergebnisse unter 1 ms das Ziel, sollte man einen Chip mit 5+ TOPS wählen. Reichen aber zum Beispiel 15 ms, ist ein Chip mit 2 TOPS ausreichend.
Wichtig ist dabei auch die genaue Aufgabenstellung wie zum Beispiel Klassifizierung versus Segmentierung, bei der unterschiedlicher Rechenaufwand benötigt wird, oder auch wie komplex das Netzwerk/Modell ist. Die Auflistung in Tabelle 2 soll einen groben Überblick geben, wann wie viele TOPS nötig sind.
Grundsätzlich gilt: Jedes Problem benötigt seine eigene Herangehensweise.
Die Untersuchungen basieren auf dem Phytec KI-Kit.