Tools richtig einsetzen
Embedded-KI beschleunigt Applikationen
Lokale KI auf eingebetteten Systemen ist ein junger, wenn auch rasch aufsteigender Trend. Grund hierfür sind die steigende Zahl an Softwareplattformen sowie Beschleunigungsmöglichkeiten in den Halbleitern. Wie Entwickler KI auf kleinen Bausteinen zum Laufen bringen, zeigt AITAD.
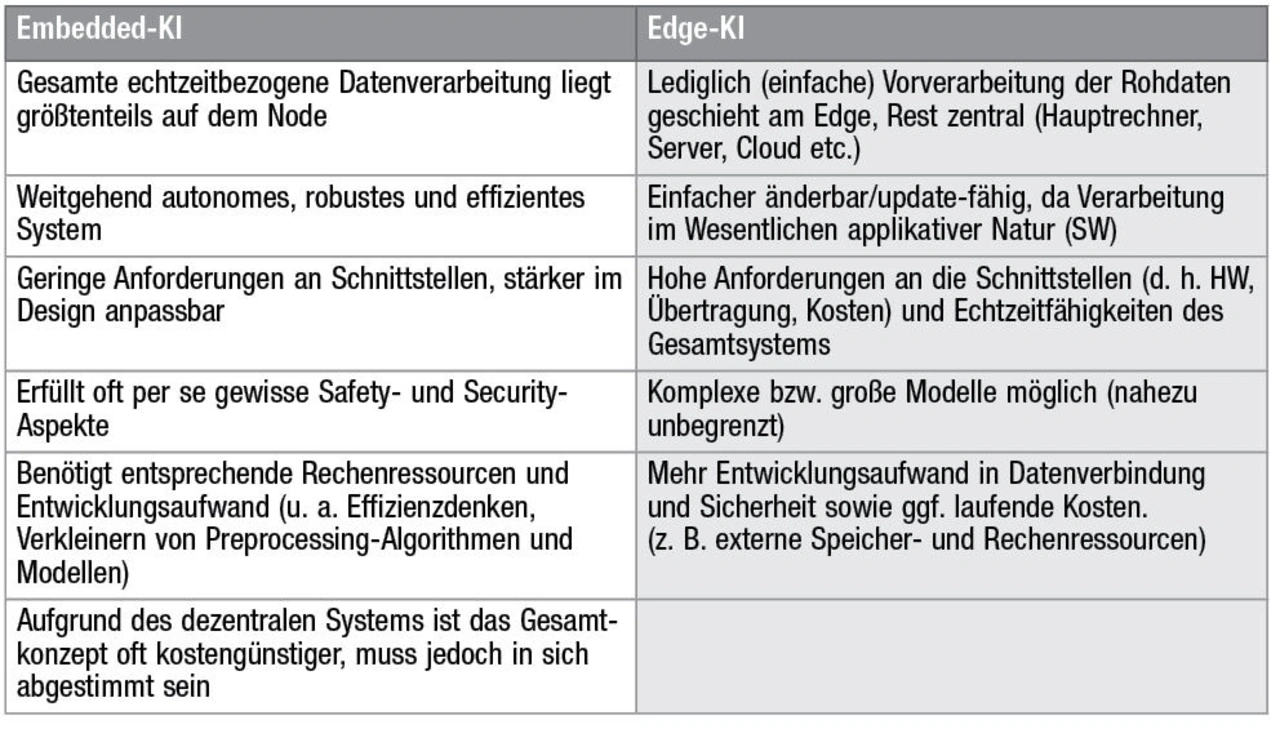
In den beiden »KI-Wintern« in den 1960er- und 1980er-Jahren machte sich nach den hoch gesteckten Erwartungen in die neue Technologie schnell Ernüchterung breit. In den 2000er-Jahren änderte sich das: Die Rechenleistung der großen Rechnersysteme schoss über das Signifikanzniveau von künstlicher Intelligenz (KI) in der Praxis hinaus. Zunächst etablierte sich KI in Servern und großen PCs. Mit dem Weiterentwickeln von KI verankerte sie sich im Heimgebrauch – ab den 2010er-Jahren kam der Edge-KI-Vorverarbeitungstrend auf. Er mündete darin, KI-Prozessabläufe gänzlich lokal und autark auf kleinen Systemen laufen zu lassen (Tabelle 1).
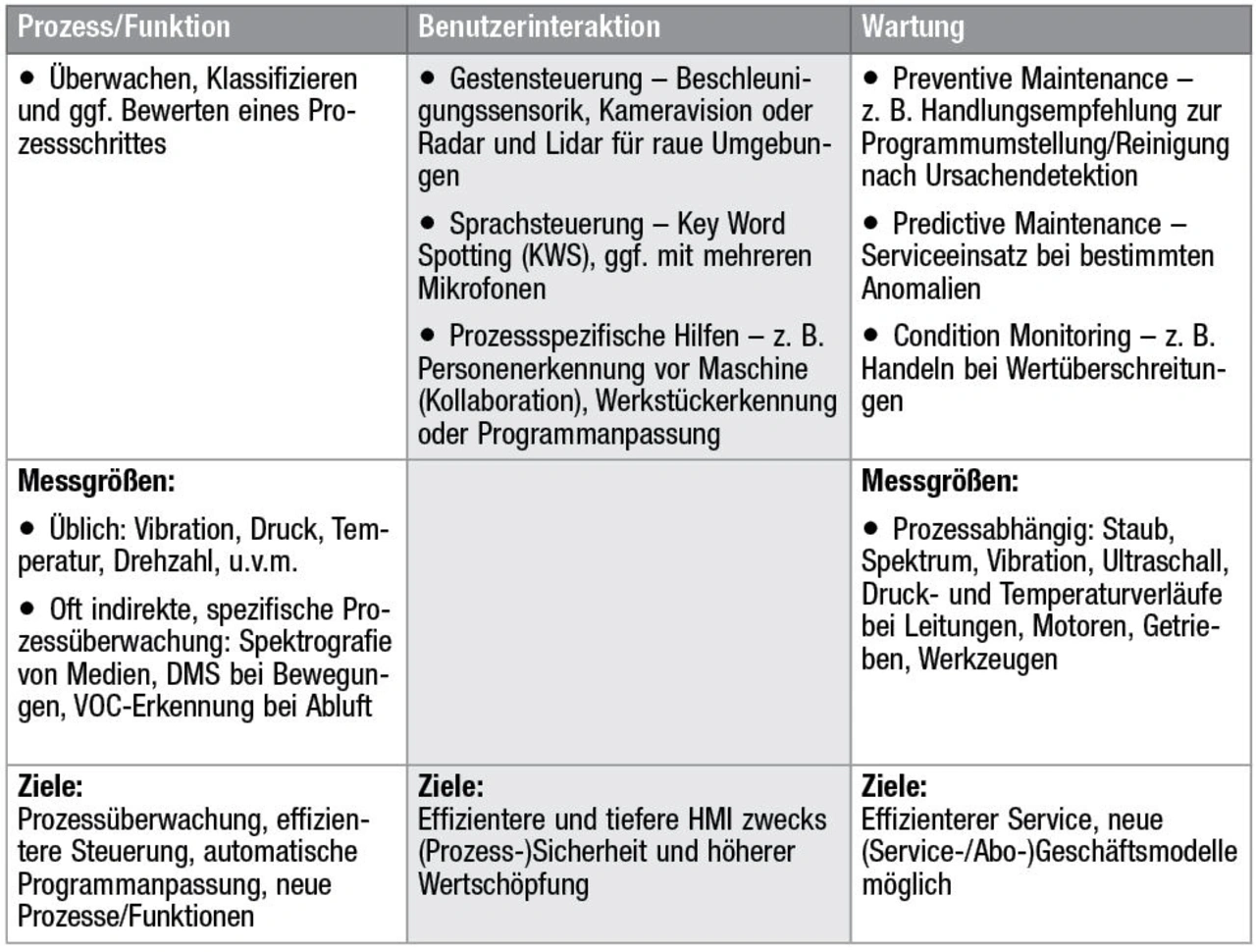
Embedded-KI lässt sich in der Praxis in drei wesentliche Einsatzgruppen (Tabelle 2) aufteilen:
- Prozess/Funktion
- Benutzerinteraktion
- Wartung
Ersteres ermöglicht neue Funktionen, die den Zielnutzen eines Produkts optimieren oder gar verändern. Als zusätzliches, sich daraus ergebendes Feld wird die Benutzerinteraktion ausgelagert. Sie kann einiges bieten: von einfacher Sprachbefehlseingabe (KWS, Keyword Spotting) über das Erkennen von Gesten bis hin zu komplexen Mensch-Maschine-Kollaborationen. Zum Beispiel Bediener- und Augen-Tracking oder das Erfassen von Werkstücken. Größte »Hidden Needs« – also versteckte Bedürfnisse – vieler Produkthersteller sind die typischen Wartungsthemen wie vorausschauendes und vorbeugendes Warten oder »Condition Monitoring«.
Effizienz ist entscheidend
Neben der nicht nötigen Netzwerkanbindung – Autarkie – sowie der Echtzeitfähigkeit, ist die Effizienz eine wesentliche Motivation für Embedded-KI-Systeme. Hierbei lassen sich die Datenreduktion und Stromeffizienz unterscheiden.
In einem vereinfachten Rechenbeispiel werden die Rohdaten einer mittelgroßen FPGA/MPU-Sensorapplikation betrachtet. Entscheidend sind die Rohdaten, denn vom KI-Modell selbst ist das »Preprocessing«, also das Filtern und die Merkmalextraktion abhängig, was sich bei Änderungen entsprechend volatil verhält. Als Beispiel dient die vorausschauende Wartung einer Antriebskomponente im Fahrzeug mit vier Analog-Ultraschallmikrofonen mit 200 kHz Grenzfrequenz. Abgetastet werden sie der Einfachheit halber mit ganzen 16 bit, es entstehen also nach Nyquist mit 400-kHz-Sampling: 4 Mikrofone x 2 Bytes pro Sample x 400.000 Samples/s = 3,2 MB/s, was multipliziert mit 8 bit wiederum 25,6 Mbit/s bedeutet.
Eine systemübergreifende CAN-FD-Schnittstelle (5 bis 8 Mbit/s) kommt also nicht infrage, alternativ bleibt lediglich Fast Ethernet. Allerdings würde es bei mehreren Teilnehmern schon früh ins Gigabit-Ethernet (ab 1.000 Mbit/s) gehen. Sogar Glasfaser wäre bei größeren Nodes mit 3D-Sensor-Daten nicht ausgeschlossen. Der Verkabelungsaufwand für das Übertragen zu einer größeren Verarbeitungseinheit wie einer Electric Control Unit (ECU, Steuergerät) oder gar weiter zu einem Server steht also bei vielen Sensoren in nicht hinnehmbarer Kosten-Nutzen-Relation.
Aus dem Grund eignen sich bei solchen Fällen lediglich dezentrale oder hybride Konzepte. Hier gelangen wir wieder zu Embedded-KI, bei der die gesamte Verarbeitung auf dem Sensor-Node im Arbeitsspeicher in Echtzeit passiert. Daher kann man nicht nur Datenmengen drastisch auf die Scores reduzieren, sondern dabei ebenfalls besonders tief in den Informationsgehalt der (Roh-)Daten blicken. Das bedeutet wiederum oftmals eine bessere Erkennungsleistung.
Noch einfacher lässt sich die Stromeffizienz überschlagen, wenn man Intels i5 CPU der 11. Generation mit der Low Power MPU »STM32L0« von ST Microelectronics vergleicht – verbotenerweise, da Pipelining oder Befehlssatz unberücksichtigt bleiben. Je nach Modus nimmt der Intel-Prozessor 1,4 mA/MHz auf (mit sporadischer Beschaltung), während der ST-Mikrocontroller mit seinem Cortex-M0+-Kern bis zu 88 µA/MHz erreichen kann.
Auf die richtigen Tools setzen
»TinyML« mit Python-Libraries wie »Keras« und »TensorFlow« sowie vielen mathematischen Bibliotheken bietet gerade mit einfachen Evaluierungsboards eine gute Einstiegsmöglichkeit in den professionellen Bereich. Erstellt ein Entwickler seine Machine-Learning(ML)-Modelle und das Preprocessing überwiegend individuell, kann er die Transfer-Tools und -Frameworks der jeweiligen Halbleiterhersteller nutzen. Sie dienen unter anderem dazu, das Netz zu analysieren, zu verkleinern und in Controller-angepasste C-Funktionen zu packen.
Beispiele solcher Werkzeuge erstrecken sich über den gesamten Halbleitermarkt: von NXP Semiconductors »eIQ« über Renesas »e-AI« bis hin zu ST Microelectronics »STMCube.AI«. Nichtsdestotrotz müssen Entwickler bis heute bei manchen der Tools, gerade bei selbst entwickelten Modellen, mit Einschränkungen rechnen. So sind immer noch einige Bugs, fehlende Kompatibilitäten und folglich nicht unterstützte Funktionen bekannt. Zum Beispiel das Feld der sogenannten Time Delay künstlicher neuronaler Netze (KNNs) bei »TF Light« vergangener Versionen.
Die Rolle des passenden und ressourcenschonenden Preprocessings, der Datenstream-Pipeline und des Scorings sind stets modellbezogen sehr herausfordernd. Wichtige Faktoren sind hierbei die Umsetzbarkeit, die Latenz und der Speicherbedarf. Das ist der Grund, weshalb die entsprechenden Transfer-Tools oft nur einen Teil des Entwicklungs-Know-hows abdecken. Hierzu muss der Entwickler den Rahmen der möglichen Verarbeitungsalgorithmen auf dem Zielsystem kennen, angefangen zum Beispiel bei Arm »CMSIS-NN«. Wobei es gerade bei entsprechenden Peripherieelementen wie Beschleunigern spannend wird – dazu später mehr.
Das geht bereits so weit, dass Entwickler aufgrund der Leistung häufiger bestimmte Preprocessing-Arten wie Frequenzdomänen annähernd modellieren, statt sie herkömmlich algorithmisch auszurechnen. Zum Beispiel »(s)FFT« und »MFCCs« – mit gefalteten künstlichen neuronalen Netzen (Convolutional Neural Network, CNN).
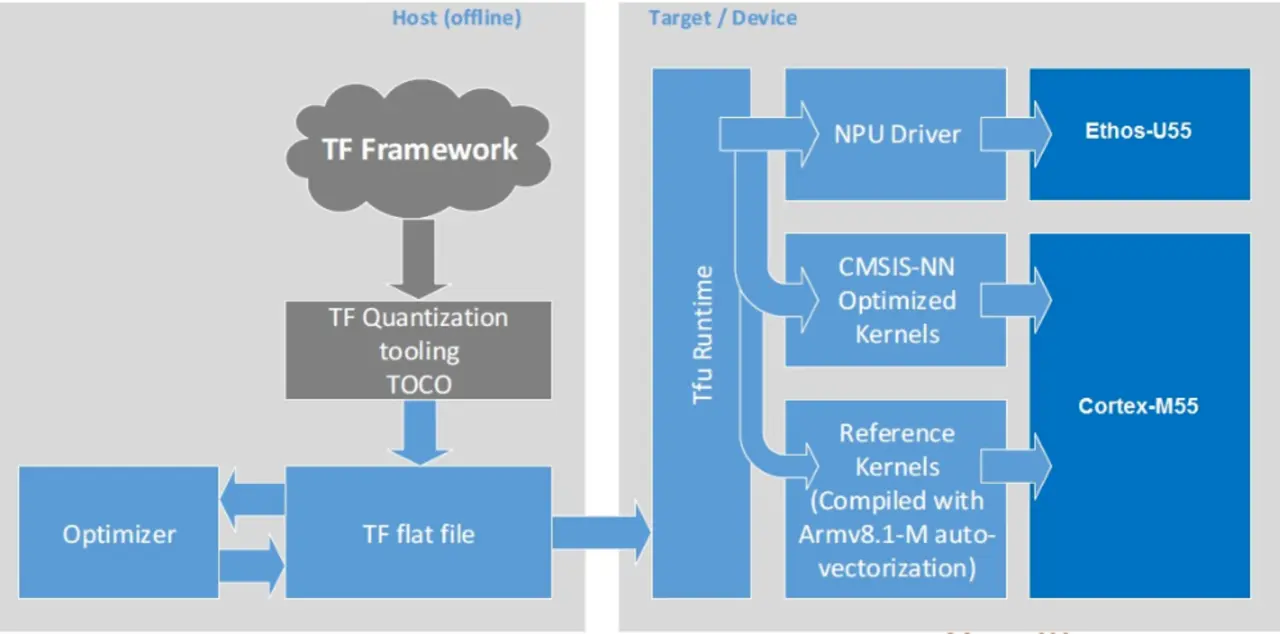
Arten der KI-Beschleunigung
Die Optimierungs- bzw. Beschleunigungsbedarfe bei Embedded-KI werden in zwei miteinander einhergehende Bereiche getrennt: Als »Offline-Tooling« bezeichnet man das Optimieren auf Seite der Software-Frameworks, also sozusagen auf dem Entwickler-PC. Die KI-Beschleunigung in der »Runtime« auf dem System, respektive dem Halbleiter, ist die andere Seite (Bild 1). Beides erläutert der Artikel an einigen Beispielen, meistens für MCUs/MPUs und für das Nutzen von KNNs.
Offline-Tooling
Beim Offline-Tooling sind die Grundtechniken der bekannten Frameworks beziehungsweise Transfer-Tools der Python-Modelle auf C meist ähnlich. Ziel ist es stets, später die Runtime auf dem Halbleiter möglichst schnell und mit möglichst wenig Speicherressourcen auszuführen. Aus dem Grund kann der Entwickler in dem Prozessschritt vieles auf die Endapplikation vorausschauend anpassen.
Das fängt bereits beim »Quantisieren« an, also dem Abbilden der Werte auf eine zumeist reduzierte Werteskala. Hiermit lässt sich Speicher für Gewichte und Input-/Durchlaufwerte sowie deren Verarbeitungszeit minimieren (später auch in der Runtime mit Preprocessing). Der Datentyp »q7_t«, also ein Byte mit einem Nachkomma-Bit für das Darstellen einer Festkommazahl, ist beim gängigen Arm-»CMSIS-NN«-Framework ein berühmter Vertreter. Jedoch fanden »floats«, also Fließkommazahlen, in den vergangenen Jahren ab einer bestimmte Halbleiterleistung immer mehr Einzug. Allerdings fanden diese mit einer der Praxis geschuldeten Latenz erst kürzlich Einzug in die Transfertools.
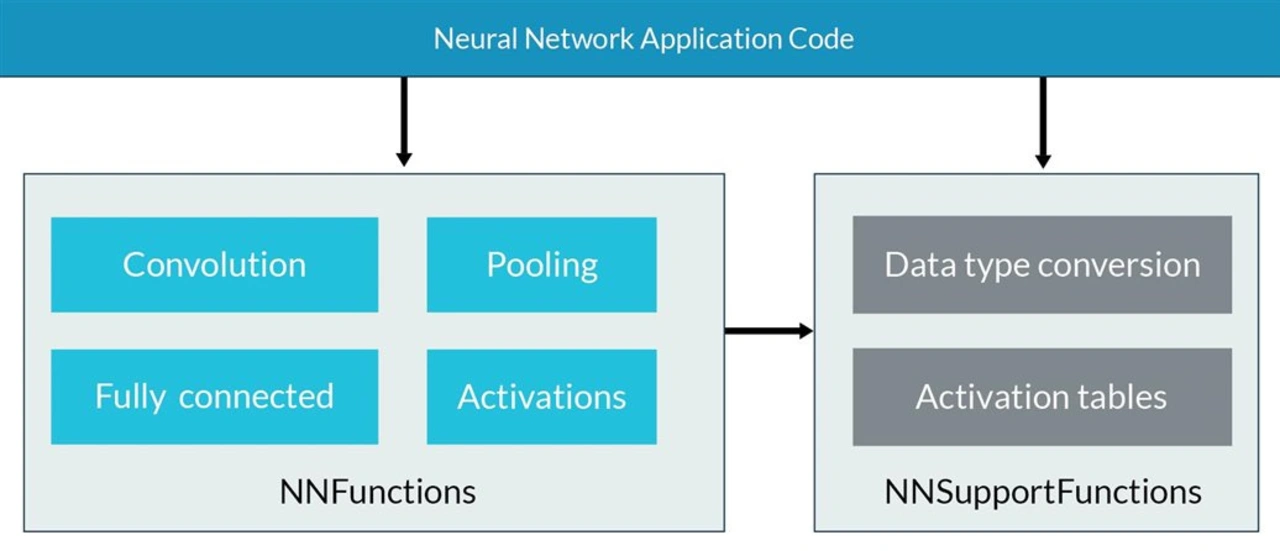
Ein weiterer altbekannter Trick, der nicht KI-spezifisch ist, ist das Speichern von Wertetabellen anstatt entsprechender Algorithmen für das Berechnen. Bezüglich der Performance reicht das dennoch aus und ist hierbei besonders schlank. Auch das ist in der CMSIS-NN Usus, prominente Beispiele sind die Aktivierungsfunktionen bei KNNs, beispielsweise die »Sigmoid«-Funktion (Bild 2).
Unter der Prämisse, die Leistung seitens des Befehlssatzes und der Register einer Halbleiter-Recheneinheit möglichst auszunutzen, optimiert ein Entwickler architekturspezifisch noch umfangreicher. Als Beispiel hierfür dient das »Weight Interleaving«, welches ebenso bereits im Offline Tooling mit den Gewichten der KNNs ausführbar ist. Hierbei muss man etwas ausholen: Für die Inferenzen der KNNs in Funktion sind Matrixmultiplikationen für das Berechnen von Input-Signalen mit den Gewichten der jeweiligen Neuronen nötig. Sie können wiederum aus vielen unabhängigen Multiply Accumulate(MAC)-Operationen bestehen. Es dreht sich grundsätzlich oft
um möglichst schnelle und parallel-verarbeitete MACs.
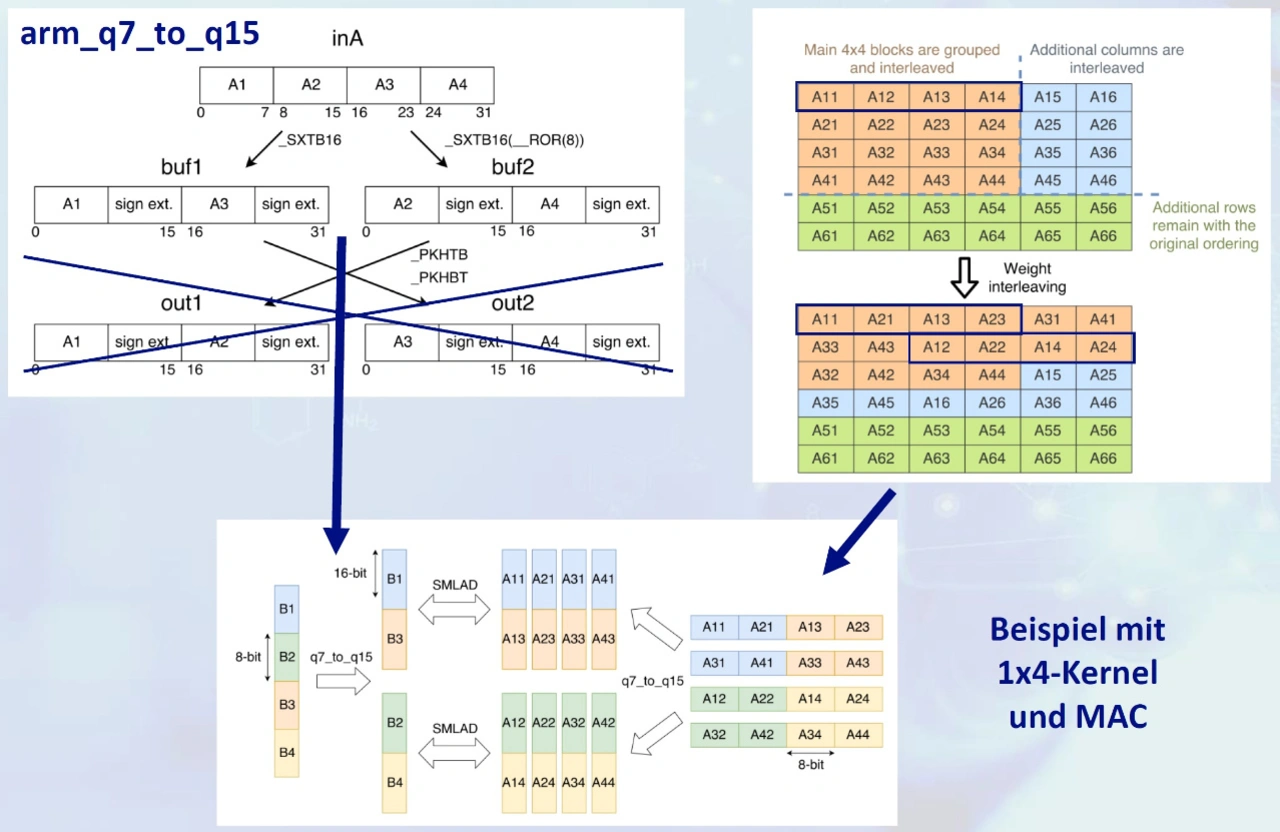
Wie in Bild 3 an einem Arm-CMSIS-NN-Beispiel gezeigt, tritt bei der Datentyperweiterung mit dem »SXTB«-Befehl ein halbleiterbedingtes, nicht numerisch sortiertes Vermengen der Eingangswerte auf. Um den MAC-Befehlstyp »SMLAD« also ohne Umordnen in Zwischenpuffern beziehungsweise -Registern zu meistern (vgl. Bild 3 unten), sind die entsprechenden Gewichtswerte in der nicht numerisch sortierten Reihenfolge abzuspeichern (vgl. Bild 3 rechts oben). Beide Eingangsdatenstreams verdreht passen also wiederum zusammen – das ist der Trick. Das Ganze kann ein Entwickler mit Kenntnis der Netzwerkstrukturen und der Gewichtswerte gleich vor dem Laden des Speichers (Flashen der MCU/MPU) tun, deshalb gehört das ebenso zum Offline Tooling.
Runtime-Beschleunigung
In der Runtime geht es mit Beschleunigungszielen weiter. Grundsätzlich kann jedes Parallelisieren der Datenverarbeitung oder jede spezifische Operationsunterstützung für die jeweilige Applikation behilflich sein. Konkret gemeint sind (mehrdimensionale bzw. mehrkanalige) Direct Memory Accesses (DMAs), Grafikeinheiten, Co-Prozessoren und digitale Signalprozessor(DSP)-Einheiten sowie digitale Filter. Zudem spielt der Befehlssatz mit beispielsweise den Single-Instruction-, Multiple-Data(SIMD)- oder Float-Befehlen oder die entsprechende Pipelining-Kette eine grundlegende Rolle.
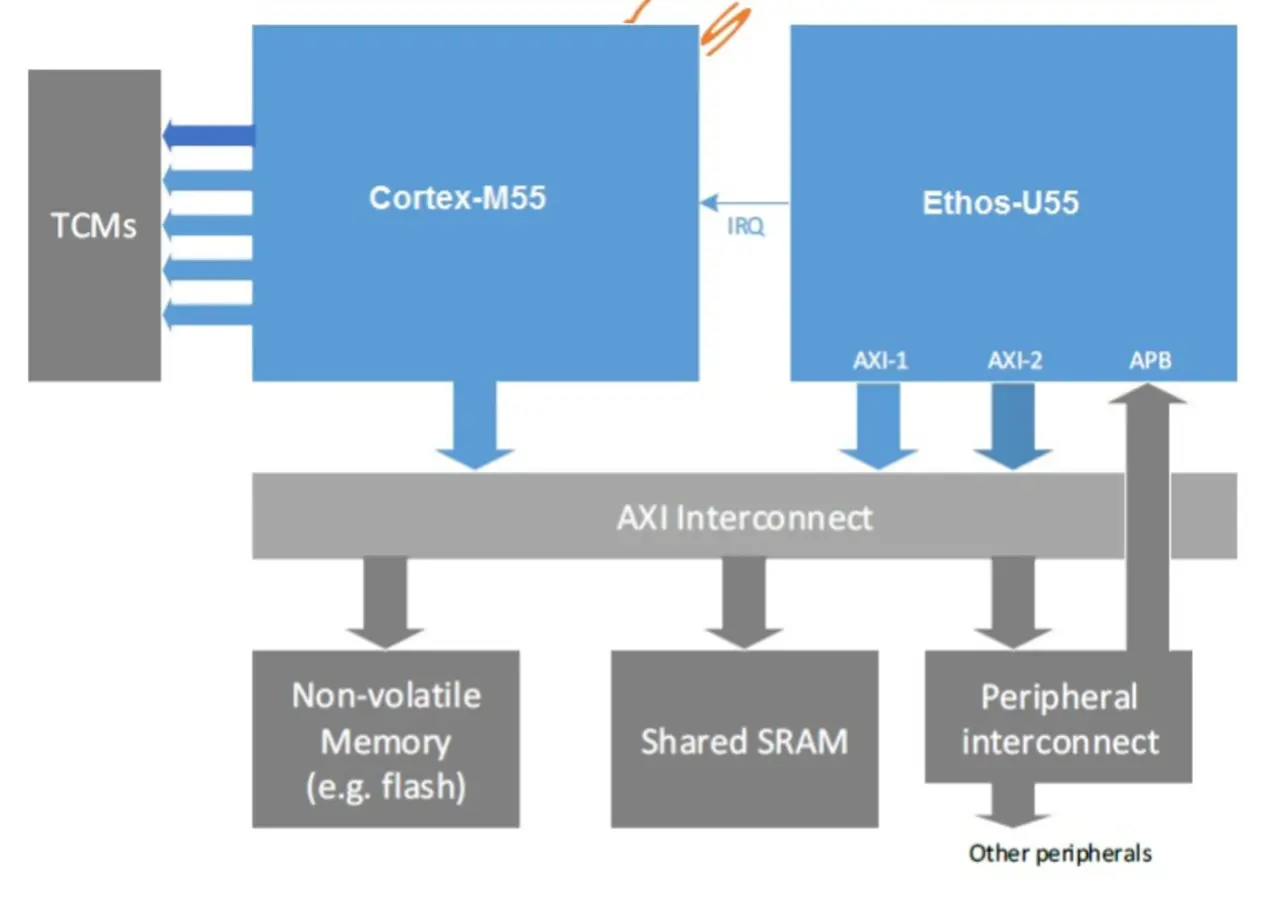
Blickt man über das GPU- und FPGA-Thema hinweg zu Mikrocontrollern beziehungsweise Mikroprozessoren, ist das Thema der spezifischen KI/ML-Beschleuniger als integriertes Zusatzelement auf dem Halbleiter-Die eines der relevantesten. Von Arm wurden beispielsweise Architekturen wie die Arm-Cortex-M55 mit Ethos-U55-KI-Beschleunigereinheit vorgestellt. Sie bekam mit dem Cortex-M85 sogar einen großen Bruder.
Die Halbleiterhersteller und IP-Lieferanten selbst haben ebenfalls proprietäre Beschleuniger im Angebot. Dennoch ist der U55 ein gutes Beispiel für einen tiefen Einblick: Eine Neural Processing Unit (NPU) zeichnet sich innerhalb der Gesamtarchitektur über ihre Eigenständigkeit mit gleichzeitig sehr umfangreichem und speichernahem Zugriff aus. Hierbei ist das Ziel der Einheit, das schnelle Verarbeiten spezifischer Funktionen, also meist MAC-Operationen. Sie haben oft eine andere Taktrate sowie eine verkürzte Verarbeitungs-Pipeline.
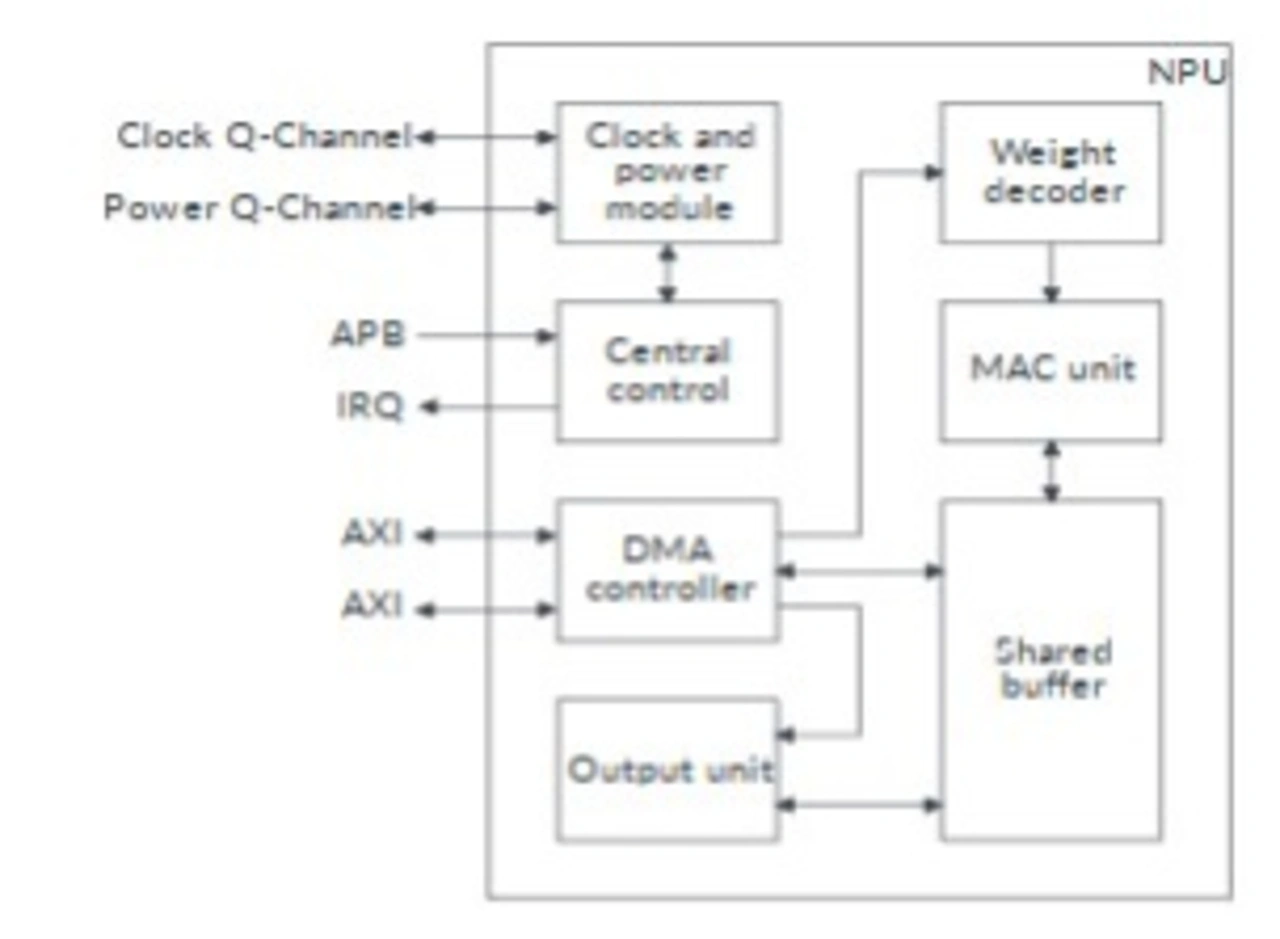
Wie am konkreten Beispiel im Bild 4 zu sehen, hat die NPU die zuvor beschriebene Koexistenz neben dem M55-Kern und den Zugriff auf die Datenbusmatrix und Peripheriebusse. Bild 5 zeigt den internen Aufbau der NPU: Man erkennt sofort eine eigene DMA fürs schnelle Daten-Streaming, das Clock-Modul sowie die Verarbeitungseinheiten auf der linken Seite.
Die NPU hat eigene Daten- und Gewichts-Buffer, um die Daten schon im Voraus richtig zu laden sowie mit der schnellen MAC-Einheit dazwischen pausenlos zu verarbeiten.
Außer in MACs/TOPS-Angaben der jeweiligen Halbleitersysteme ist zudem der Einsatz von bestimmten Frameworks messbar. Bei CMSIS-NN erreicht ein Entwickler am Ende beispielsweise häufiger einen fünffachen Durchsatz in der Runtime-Inferenz als ohne. Die umfassenden Optimierungen und Beschleunigungen auf allen Ebenen sind also für die lokale KI-Technologie maßgeblich.
Wohin geht die Reise?
Trotz der zunehmenden, jedoch oft zu einfach ausgestalteten Versuche einer Plattform ist für Entwickler gerade im Forschungs- oder Whitepaper-Bereich eine gewisse Marktsegregation zu spüren. Zum Beispiel aufgrund unterschiedlicher Lösungsansätze, zu spezifischen oder bereinigten Datenbasen oder fehlenden Kompatibilitätsmöglichkeiten. Für die nächsten Jahre ist das für die Branche herausfordernd, gerade wenn es um KI-Zertifizierung, -Dokumentation und ähnliche Sekundärthemen geht. Zu einem Teil der Themen sind bereits entsprechende Gremien, auch in Deutschland, tätig.
Eines ist zudem – ausgehend von der Hardware – aktuell stark zu beobachten: Nach den in den vergangenen vier Jahren immer mehr im Kleinleistungsbereich gelaunchten, generell KI-optimierten Halbleiter, spezialisieren sich die Architekturen respektive die dazugehörigen Frameworks auf bestimmte Anwendungsfälle.
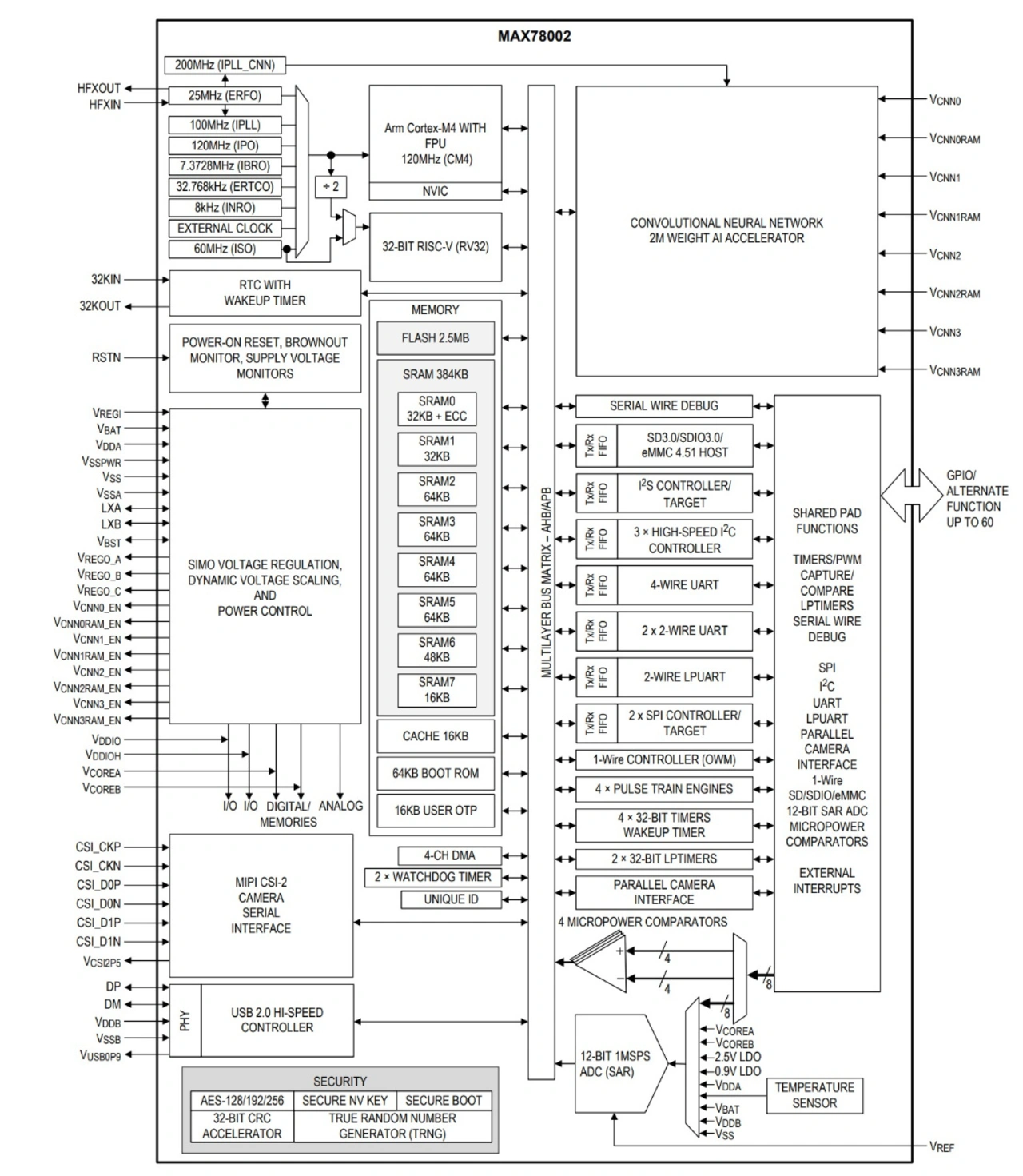
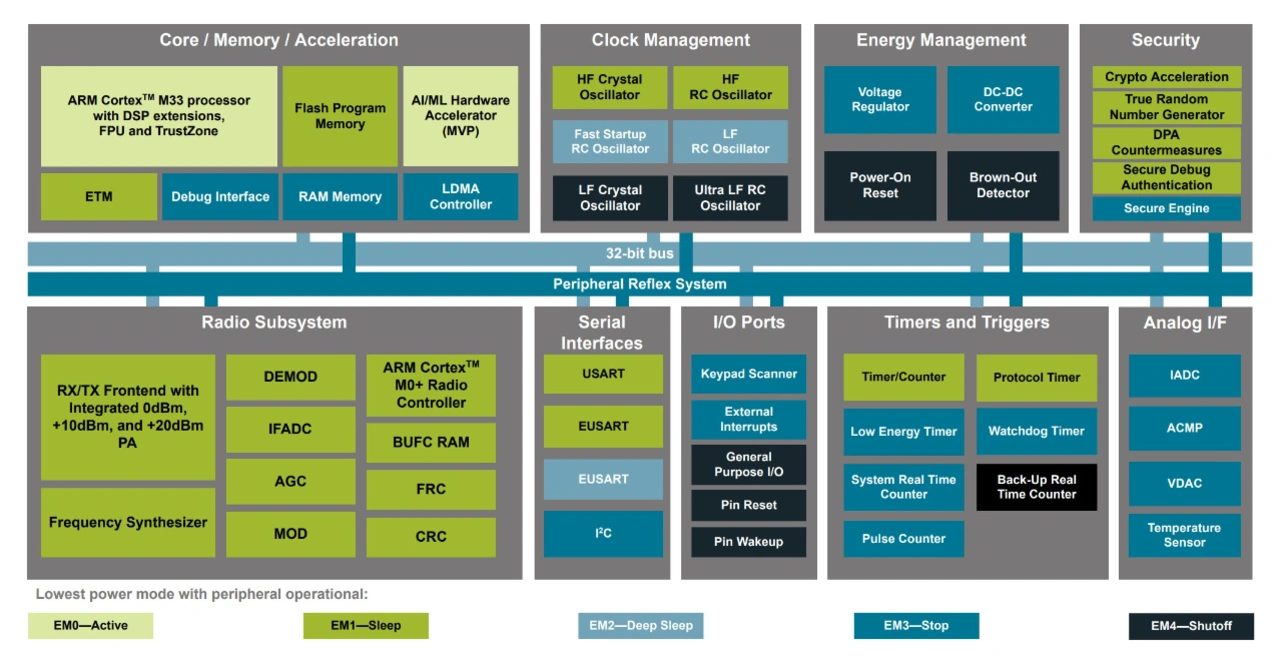
Beispielsweise war die »MAX78000«-Serie von Analog Devices mit Heterogenous Multicore Processing (HMP) mitsamt einem RISC-V-Kern und einem ML-Beschleuniger sehr erfolgreich bei Applikationen für das Erkennen von Sprache. Wobei sein Nachfolger, der »MAX78002« in den Videobereich hineinragt – nicht zuletzt aufgrund 2048 x 2048-Bild-Inputfähigkeit und 2 MB internem NPU-Speicher (Bild 6). Ebenso bemerkenswert ist beispielsweise Silicon Labs mit den »MG24/BG24«-SoCs mit einem eigenen ML-Beschleuniger. Er ist auf Low-Power- und Wireless-Applikationen spezialisiert (Bild 7). Man beachte der Vollständigkeit halber ebenfalls die Sensoren, die immer mehr ML-(Vor)-Verarbeitung übernehmen. Ein gutes Beispiel ist der »LSM6DSO32X« als ein performanter Vertreter der »iNemo«-Sensorserie von STMicroelectronics. Er kann mit seiner Multi-Level-Cell(MLC)-Unit unter anderem einen Entscheidungsbaum mit bis zu 256 Knoten abbilden.
Als Trend über allem zeigen sich Themen wie Memristor-Arrays oder Verarbeitungseinheiten für die der Natur ähnlicheren Spiking Neural Networks (SNNs). Sie beziehen den Zeitkontext bereits in den tiefen Strukturen ein. Hierbei ist die typische Technologie-Adoptionskurve zu beachten – zunächst ist die Technologie segmentweise teuer zu haben, später volumenbedingt allgegenwärtig günstig.
Dennoch ist abschließend zu sagen: Das Varianzproblem ist gerade bei Embedded-Systemen eine der größten Herausforderungen, gerade wenn es sich um verschiedene Baureihen, Umgebungen und Nutzerverhalten beim gleichem Systemtyp handelt. Bisher sind die trainierten und auf das Embedded-Zielsystem portierten Modelle im Feld meist nicht im Wirkzyklus anpassbar. Höchstens über ausgewählte Vorverarbeitungs- oder Auswerteparameter. Das kann bei einer einfachen Schwellen-Trigger-Einstellung von Wahrscheinlichkeiten beginnen und beliebigkompliziert ausarten. Ab einer gewissen,
für viele Applikationen jedoch zu kostenintensiven Größe und Systemauslegung kann ein Entwickler für die maximale Flexibilität ein neues Modell per allumfänglichem Update überspielen.
Gerade diesbezüglich ist jedoch das adaptive Training auf einem eingebetteten System ein spannendes und schrittweise zur Praxis hin konvergierendes Forschungsfeld. Hier ist ein Nachtrainieren oder Anpassen des Modells während der Laufzeit im
System gemeint. Der Grad der Herausforderung unterscheidet sich hierbei entsprechend von Decision Trees bis hin zu KNNs. Wesentlich ist jedoch: Für das (Nach-)Training bei ML ist fast immer eine andere Operationenabfolge nötig als für die Inferenz. Wenn dieses »Training-on-Chip« marktreif in kleinen Halbleitern implementiert ist, kommt die Embedded-KI noch auf weit höhere Touren.
Literatur
[1] CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs. L.Lai et al. 2018. https://arxiv.org/abs/1801.06601. aufgerufen am 01.02.2023, 16:08
[2] Arm Ethos-U55 NPU Technical Reference Manual. Arm 2023.
https://developer.arm.com/documentation/102420/0200. aufgerufen am 01.02.2023, 16:08
[3] Arm Cortex-M55-CPU und Ethos-U55-NPU pushen KI. Elektroniknet.de. 2020. https://www.elektroniknet.de/halbleiter/mikrocontroller/arm-cortex-m55-cpu-und-ethos-u55-npu-pushen-ki.173092.html. aufgerufen am 01.02.2023, 16:10
[4] MAX78002 Website. Analog Devices. 2023. https://www.analog.com/en/products/max78002.html#product-overview. aufgerufen am 01.02.2023, 16:10
[5] ML-Website. Silicon Labs.2023. https://www.silabs.com/applications/artificial-
intelligence-machine-learning. aufgerufen am 01.02.2023, 16:11
[6] LSM6DSO32X Website. STMicroelectronics. 2023. https://www.st.com/en/mems-and-sensors/lsm6dso32x.html. aufgerufen am 01.02.2023, 16:11
Der Autor

Viacheslav Gromov ist Gründer und Geschäftsführer von AITAD. Das Unternehmen entwickelt elektronikbezogene künstliche Intelligenz (Embedded-KI), die in Geräten und Maschinen lokal und in Echtzeit definierte Aufgaben übernimmt. Er ist Verfasser zahlreicher Beiträge sowie diverser Lehrbücher im Halbleiterbereich. Gromov ist als Experte in verschiedenen KI- und Digitalisierungsgremien tätig, unter anderem von DIN und DKE sowie der Bundesregierung (DIT, BMBF). Jüngst erhielt AITAD sogar den Top100-Innovationspreis für mittelständische Unternehmen. Der Artikel beruht auf seiner Vorlesung an der Hochschule Offenburg. v.gromov@aitad.de