KI für den Maschinenservice
FINDIQ: »Das Expertenwissen muss aus den Köpfen in die KI«
Das KI-Startup FINDIQ ist vor zwei Jahren angetreten mit dem Ziel, mit leicht anwendbarer KI das Maschinenservice-Wissen langjähriger Mitarbeiter zu bündeln und nachhaltig verfügbar zu halten. Sina Volkmann, CEO und Co-Founder, erläutert das technische Prinzip und die unternehmerischen Hintergründe.
Markt&Technik: Vor welchem persönlichen Hintergrund haben Sie sich dazu entschlossen, die FINDIQ GmbH zu gründen?
Sina Volkmann: Ich habe vor zwei Jahren FINDIQ ins Leben gerufen, als Nicht-Technikerin in einem technischen Umfeld. Das habe ich getan, weil mein betriebswirtschaftlicher Hintergrund und meine jahrelangen Erfahrungen im Projektmanagement in der Industrie mir eines gelehrt haben: Technische Berufsfelder wie der Maschinen- und Anlagenbau und der Maschinenservice haben eines genug - technische Expertise. Was ihnen fehlt, sind Menschen und Lösungen, die den Fokus nicht auf die Expertise selbst legen, sondern darauf, diese Expertise integrativ und nachhaltig zu nutzen. Was so leicht klingt, scheitert häufig schon daran, dass die Experten hinter der Expertise bislang nicht für mehr angestellt waren als dazu, mit ihrem Wissen Maschinen zu bauen und zu servicen. Das Teilen ihres Wissens gehörte bislang nicht zum Jobprofil. Erst aber das Zusammenarbeiten über mehrere Disziplinen hinweg sorgt beispielsweise für den Wissensfluss von der Konstruktion zum Servicetechniker im Feld und zurück. Oder erst die saubere und verständliche Dokumentation von Serviceeinsätzen ermöglicht, Service nicht personenabhängig, sondern standardmäßig erfolgreich zu leisten.
Genau dieses Aufschreiben, Digitalisieren und Teilen von Wissen, besonders vor dem Ausscheiden so vieler erfahrener Serviceexperten, das in den nächsten Jahren passiert, haben wir zu FINDIQs Aufgabe gemacht. Mittlerweile sind wir damit schon zweieinhalb Jahre erfolgreich und voller Leidenschaft dabei.
Als CEO und Co-Founderin von FINDIQ bin ich dankbar, meine zehn Jahre Erfahrung in der Beratung für die Einführung digitaler Lösungen im Produktionsumfeld hier jeden Tag einfließen lassen zu können.
FINDIQ arbeitet mit einer KI im Hintergrund - was für KI-Anwendungen gibt es momentan schon in der industriellen Automatisierung?
Als wir FINDIQ im Jahr 2022 gegründet und uns dem Thema Wissenstransfer im Maschinenservice gewidmet haben, gab es natürlich schon KI-Systeme. Damals wie heute gilt das Verständnis, dass jeder, der etwas mit KI machen will, im Hintergrund mit Wahrscheinlichkeiten arbeitet. Am Beispiel FINDIQ: Bei uns geht es darum, das Wissen von Serviceexperten zu Maschinen und ihren Fehlern digital abzubilden. Dabei ist es entscheidend, wie und wie oft bestimmte Fehlerbilder an der Maschine auftreten und wie sich diese Wahrscheinlichkeiten im Laufe der Zeit verändern. Diese Veränderung hilft dabei, solche Systeme - bei uns die Wissensbasis - dauerhaft zu optimieren, neue Zusammenhänge zu erkennen oder alte anzupassen.
Im Laufe unserer Existenz ist KI populär geworden, und mit dem Aufkommen von Sprachmodellen wie ChatGPT wurden diese Modelle plötzlich mit dem allgemeinen KI-Begriff gleichgesetzt. Weil Sprachmodelle über kommerzielle Anbieter leicht verfügbar sind, werden sie mittlerweile auch in der Industrie beispielsweise dafür eingesetzt, Dokumente semantisch zu durchsuchen. Wie gut die Ergebnisse dabei allerdings sind, hängt stark von der Struktur und der Qualität der Dokumentenbasis ab. Und diese sind Produktionsumfeld eine ganz andere, verglichen mit den Daten »aus dem Internet«.
Neben diesen sogenannten Daten-getriebenen Sprachmodellen existieren aber auch andere KI-Bereiche weiter, die einfach weniger mediale und gesellschaftliche Aufmerksamkeit erhalten haben. Diese sogenannten Modell-basierten Ansätze kommen mit deutlich weniger Daten aus und sind zudem auch keine »Black Box«, ihre Ergebnisse lassen sich also einfacher nachvollziehen. Genau in diesem KI-Bereich bewegt sich FINDIQ, mit dem Verständnis und der Überzeugung, dass wir mit der Entwicklung und Kombination von KI-Verfahren aus diesem Bereich die Use Cases der Industrie besser abbilden können.
Was ist eine Black Box in diesem Zusammenhang?
Bei einer Black Box ist für Endanwender nicht klar, auf welcher Grundlage die KI Entscheidungen trifft. Wenn also ein Fehler passiert, weiß der Anwender nicht, warum die KI sich so entschieden hat und dementsprechend auch nicht, ob der Fehler wieder passieren könnte. Das führt in kritischen Umgebungen wie der Produktion im schlimmsten Fall dazu, dass die KI unvorhersehbare Ergebnisse liefert und beispielsweise Vorschläge zur Fehlerdiagnose oder -behebung macht, die inhaltlich falsch sind.
Wo können Industrieunternehmen KI gewinnbringend oder effizienzsteigernd einsetzen?
Das Allerwichtigste ist, dass Unternehmen für sich im ersten Schritt erkennen, welche Prozesse momentan noch manuell erfolgen und somit viel von Personen und Doppelarbeit abhängen. Diese Prozesse können grundsätzlich standardisiert, also jeden Tag gleich gemacht, und dann automatisiert, also durch ein System erledigt werden. Wenn das geschehen ist, lässt sich KI einsetzen, um die automatisierten Tätigkeiten zusätzlich zu beschleunigen. Was also heute vielleicht einen Tag erfordert, nimmt in Zukunft nur noch einen halben Tag in Anspruch, weil über das System und dessen häufige Nutzung gelernt wird, welche Schritte schneller zum Ziel führen. Ein weiterer Vorteil der Integration von KI ist, dass kontinuierlich neue Sachverhalte aufgenommen und die Daten aktuell gehalten werden können. Aus Sicht der Industrie, konkreter des Maschinenservice gesprochen: wenn sich Maschinen und deren Zustand sowie Fertigungsprozesse und -produkte dauerhaft ändern, dann ändert sich fortwährend die Datengrundlage, auf deren Basis Maschinenbediener, Instandhalter oder Servicetechniker Entscheidungen treffen und agieren müssen. Wenn KI-basierte Lösungen dann in der Lage sind, die veränderten Zustände und Bedingungen dauerhaft korrekt in die Datenbasis aufzunehmen, entsteht Aktualisierung und Optimierung. Beide Attribute gelten für die rein »statische« Digitalisierung von Dokumenten, Inhalten und Tätigkeiten nicht.
Die Einsatzgebiete von KI in der Industrie sind dabei divers. Gerade im Umgang mit technischen und komplexen Sachverhalten, wie im Service von Maschinen und Anlagen, gilt aber immer, KI nicht ohne den Menschen und seine finale Beurteilung einzusetzen. Sprich: ein KI-basiertes Assistenzsystem, angewandt von einem Hotline-Mitarbeiter im Support, ist für den anrufenden Kunden mit einer Serviceanfrage immer noch attraktiver als direkt mit einem Chatbot zu sprechen. Auch der Einsatz von Assistenzsystemen zur Fehlerdiagnose direkt an der Maschine erübrigt maximal die »manuelle« Fehlereingrenzung, nicht aber den Einsatz der menschlichen Arbeitskraft zur anschließenden Reparatur.
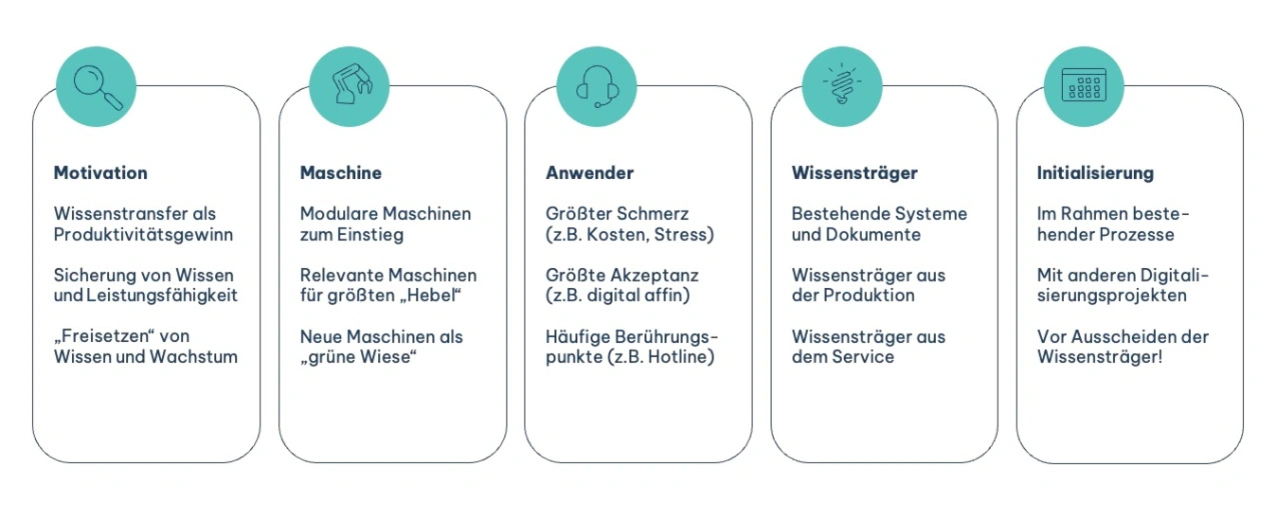
Wie sollten Industrieunternehmen vorgehen, wenn sie KI in ihrer Produktion einsetzen wollen? Wie sollten sie entsprechende Projekte aufsetzen, wie und womit sollten sie beginnen?
Bei der Einführung von KI lautet die erste Frage: Welches Ergebnis will ich erreichen, und was soll durch den Einsatz von KI verbessert werden? Die Antworten auf diese Fragen sollten im besten Fall von den späteren Anwendern kommen, also den operativen Mitarbeitern wie Servicetechnikern oder Maschinenbedienern, und nicht von »Use-Case-Unbeteiligten« aus der Management-Ebene. In den letzten Jahren wurden viele Innovationen, zuletzt auch Versuche und Piloten rund um KI, Top-Down priorisiert und dadurch nicht ausreichend differenziert bewertet. In der Folge wurden zu viel Zeit und Geld aufgewendet, mit der späten Erkenntnis ausbleibender Akzeptanz und Ergebnisse.
Um das im Vorfeld abzuwenden, sollten die Ideen für den Einsatz von KI in der Produktion von den Mitarbeitern selbst kommen. Sie können aus eigenem Erleben heraus beurteilen, wo am unproduktivsten gearbeitet wird und damit der größte Hebel für KI besteht. So haben wir damals zusammen mit dem Bedienpersonal vor der Anlage herausgefunden, dass einer der »unproduktivsten« Prozesse die Diagnose und Behebung von Maschinenfehlern ist. Wenn der initiale Impuls von den späteren Anwendern kommt, treiben diese die spätere Umsetzung der Lösung viel automatischer und intrinsisch motiviert voran. Parallel zu ausgewählten Pilotprojekten im Operativen sollten auf strategischer Ebene gewisse Leitplanken gesetzt werden. Diese lassen sich im Vorfeld definieren. Wenn sie aber schlicht noch nicht klar sind, weil das Thema KI neu und nicht im Detail verstanden ist, können Leitplanken auch erst auf Basis erster praktischer Erfahrungen abgeleitet werden. Zeit- und Ressourcenverschwendung wäre es jedenfalls, jetzt erst einmal über drei Jahre ein Konzept zum Thema »Management allen Wissens zu allen Bereichen unseres Unternehmens« zu schreiben, bevor die Anwendungsfälle und jeweiligen Ziele klar und »erfahrbar« sind. Was hingegen von der Management- oder strategischen Ebene erwartet werden darf, ist das klare Commitment zum Thema durch explizites Abstellen von Ressourcen und gutes Durchsteuern mit klaren Verantwortlichkeiten. Auch die Vorarbeit für das Pilotieren KI-basierter Lösungen sollte verantwortet und eingeplant werden. Meist besteht diese in der technischen Vorbereitung der Datengrundlage, ebenso wie dem Briefing und »Mitnehmen« der Organisation und ihrer Menschen. Beides erledigt, empfiehlt es sich, dann auf Basis der Impulse der Mitarbeiter mehrere Pilotprojekte parallel zu starten. Dies ermöglicht, mehrere Lösungen nebeneinander testen zu können, Schnittmengen oder Ergänzungen zu identifizieren und auch die Zusammenarbeit mit einem möglichen externen Dienstleister zu prüfen. Nicht zuletzt verlieren Unternehmen hierdurch weniger Zeit, als wenn sie zu früh eine »Entweder-Oder-Entscheidung« treffen und später nicht mehr umkehren können. Stehen nach einer etwa halbjährigen Testphase – länger sollte die Validierungsphase nicht dauern – drei Optionen zur Auswahl, gilt es, die Empfehlung der Testnutzer zu befolgen, nicht die von »bunten Powerpoint-Folien für das Management«.
Wie können Industrieunternehmen ermitteln, welchen Nutzen der Einsatz von KI in ihrer Produktion konkret bringt?
Je größer die Unternehmen sind, umso eher bewerten sie den Nutzen von Innovationen auf Basis von KPIs, quantitativ und monetär. Zur Bewertung des Mehrwerts digitaler oder KI-basierter Lösungen in der Produktion und im Service werden Kennzahlen wie etwa der reduzierte Maschinenstillstand, verringerte Stillstands- und Instandhaltungskosten oder Serviceproduktivität pro Mitarbeiter herangezogen. Dabei, so unsere Wahrnehmung, wird der Fokus stark auf kurzfristige Effekte, aber weniger auf den nachhaltigen Nutzen gelenkt. Genau diese nachhaltigen, mittlerweile auch immer fundamentaleren Entscheidungen gilt es aber zu treffen.
Die Einführung einer digitalen Lösung zum Wissenstransfer im Maschinenservice wird sich nicht in wenigen Monaten in einer messbar höheren Produktionsverfügbarkeit niederschlagen, wenn das Wissen der Mitarbeiter noch verfügbar ist. Wie verhält sich dies aber, wenn die Wissensträger schon in wenigen Jahren in den Ruhestand ausscheiden und ihr Wissen mitnehmen? Wir haben diese Ausmaße einmal für uns berechnet und mit Schrecken festgestellt, dass Stillstände und ihre Kosten um ein Achtfaches steigen. Das liegt daran, dass unerfahrene Mitarbeiter Stillstände ohne Hilfe deutlich langsamer beheben. Vor allem aber werden sie künftig mehrere Produktionsschichten oder mehrere Tage warten müssen, bis einer der kaum noch verfügbaren Experten anreist. Dass also ab irgendeinem Zeitpunkt der Return-on-Invest solcher Innovationen auch in Euro abbildbar ist, ist nur eine Frage der Zeit. Die Entscheidung zum Start dieses Themas bis dahin zu vertagen, ist allerdings keine gute. Aus zwei Gründen: Zum einen macht sich der Nutzen KI-basierter Lösungen meist erst ab einem bestimmten Durchsatz bemerkbar, also einer Grundabdeckung des Maschinenparks und -portfolios. Zum anderen braucht eben diese Durchdringung die notwendige Akzeptanz einer Softwarelösung unter den Mitarbeitern. Ein immer noch deutlich unterschätzter Nutzen liegt damit schon in der operativen Anwendung verborgen. Nach einigen Jahren auch vieler »Irrfahrten« bei der Einführung digitaler Lösungen in der Produktion ist jeder gewonnene Nutzer, jede Softwarenutzung heute mehr als gestern ein Erfolg.
Kontinuierlich auch über gute Schulungen und Begleitung forciert, kann die schrittweise Steigerung der Nutzerakzeptanz den »Return« potenzieren und beschleunigen. Stellen Sie sich nur einmal vor, um wie viel schneller sich der Invest in eine neue Lösung auszahlt, wenn nur ein zufriedener Mitarbeiter der Nachtschicht einem anderen in der Frühschicht die neue Software empfiehlt. Und der Mitarbeiter der Frühschicht an einem deutschen Standort selbiges mit einem Mitarbeiter in einem Standort in China tut.
Zusammenfassend ist es sicherlich die Kombination aus kurzfristigen, altbekannten KPIs und neuen, sich auch teilweise noch ergebenden operativen Erfahrungswerten, die eine gute Bewertungsgrundlage bildet.
Was müssen industrielle Anwender von KI-Algorithmen in puncto Safety und Security beachten? Welche Safety- und Security-Probleme wirft der Einsatz von KI-Algorithmen auf, und wie lässt sich ihnen begegnen?
Wenn KI in der Produktion eingesetzt wird, etwa um Assistenz zu leisten und Handlungsempfehlungen auszusprechen, wird nicht aktiv in den Produktionsprozess eingegriffen. Denn die Entscheidung, ob sich nach der Empfehlung gerichtet wird, trifft immer noch ein Mensch.
Natürlich kann beim Einsatz KI-basierter Assistenzsysteme, etwa in einem Hinweisfenster, darauf aufmerksam gemacht werden, dass es sich nur um Empfehlungen handelt. Hier sind (KI-basierte) Assistenzsysteme aber auch nicht anders zu handhaben als klassische Betriebsanleitungen. Gerade Letztere bringen rechtliche Absicherung, und ein Assistenzsystem kann sogar zusätzlich noch auf den Blick in die Anleitung hinweisen.
Was das Thema Data Security anbelangt, ist zum einen der Softwareanbieter selbst zu beurteilen und dessen Umgang mit kundenindividuellen Daten. Eine erste Frage kann sein, ob die in eine Software eingespeisten Daten mit großer Wahrscheinlichkeit bei einem deutschen, europäischen oder amerikanischen Anbieter landen. Wenn vermieden werden kann, dass über die Nutzung einer Software wertvolle Produkt- oder Produktionsdaten an Dritte gelangen, sollte dies getan werden. Zudem lässt sich verhindern, dass ein Softwareanbieter Eigentum an den Kundendaten erhält oder diese gar unternehmensübergreifend verwerten darf. Viele der datenbasierten KI-Lösungen brauchen natürlich eine Menge an Daten, um überhaupt zu funktionieren. Das beste Beispiel ist ChatGPT, was ohne die Datenmengen des Internets, der ganzen Welt, nicht funktionieren würde. Sollten also andersherum unternehmensindividuelle und -kritische Daten über die Nutzung von ChatGPT auch an die ganze Welt zurückgegeben werden? Weil die Antwort vieler Unternehmen darauf »Nein« lautet, haben sich unternehmensinterne »ChatGPT-Lösungen« etabliert.
KI-basierte Lösungen hingegen, die erst gar nicht so große Datenmengen benötigen, etwa unsere FINDIQ-Lösung, können von vornherein garantieren, dass die Daten weder ihnen gehören noch übergreifend geteilt werden müssen.
Wenn solche externen Software-Lösungen dann noch vorweisen können, dass sie Serverinfrastrukturen im europäischen oder gar deutschen Raum nutzen, ist der Großteil der klassischen etablierten Industrieunternehmen hier zufrieden. Zum Glück hat sich diesbezüglich auch das Mindset zu Cloud- und Lizenz-basierten Software-Lösungen verändert. Viele Unternehmen sind mittlerweile dankbar, den Betrieb und die Updates ihrer Systeme auf zuverlässige Partner und Experten mit sicherer Infrastruktur auslagern zu können. Denn ihre eigenen IT-Abteilungen und Server-Landschaften waren eben nicht kompetenter oder gar sicherer als die nach deutschen oder europäischen Sicherheitsstandards geprüften Infrastrukturanbieter. Im Gegenteil: Maschinenbauer oder Industriebetriebe verstehen immer mehr, dass sie das unbedingte Bestreben, Softwareentwicklung und -betrieb »auch selbst machen zu wollen«, von ihrer Kernkompetenz ablenkt.
Eher sollten sie sich die Zeit nehmen, in Europa und gerade auch in Deutschland, einfach einmal ausgiebiger zu recherchieren, ob es Alternativen abseits von Eigenkreationen oder den »amerikanischen Giganten« gibt.
Welche Rolle können Large Language Models (LLMs) wie ChatGPT in der Automatisierung spielen?
LLMs sind Sprachmodelle, die auf Basis von Machine Learning Informationen in Form von Sprache wiedergeben. Typischerweise sind sie in kreativen Bereichen gut eingesetzt - da, wo immer noch die Zeit besteht, die Ergebnisse der LLMs zu korrigieren. So beruht die Antwort auf eine Abfrage bei Sprachmodellen auf bekannten Texten, auf deren Basis eine ähnliche - passend klingende - Information zurückgegeben wird. Einsatzgebiete liegen demnach häufig in Bereichen wie der Content-Erstellung, also klar im »White-Collar-Bereich«.
Sprachmodelle dagegen funktionieren dort nicht, wo die Menge an Daten nicht ausreicht, um das Modell anzulernen, wo die Daten sehr heterogen sind oder wo sie einen sehr komplexen Sachverhalt widerspiegeln sollen, also logisch schlussfolgern müssen. Denn ein Sprachmodell wie ChatGPT stellt keine eigenen Berechnungen an, sondern bezieht sich auf ähnliche Daten und imitiert diese Muster und Textbausteine. Damit muss das Ergebnis nicht immer inhaltlich richtig sein. Bei komplexen Sachverhalten wie etwa Maschinen oder Maschinenstillständen und ihrer Fehlerdiagnose bietet es sich daher an, andere KI-Verfahren in Betracht zu ziehen, die mit weniger Daten auskommen und nicht nach sprachlicher Ähnlichkeit entscheiden. Hier haben sich traditionellere KI-Verfahren bewährt, die auch auf Basis weniger Daten robuste Entscheidungen treffen können.
Was ist generative KI, und welche Rolle kann sie in der Automatisierung spielen?
Generative KI wird als Oberbegriff benutzt für alle KI-Verfahren, die neue Inhalte erschaffen. Die bekanntesten davon, etwa ChatGPT für Texte oder Midjourney für Bilder, beruhen üblicherweise auf künstlichen neuronalen Netzwerken (KNN). Diese benötigen riesige Datenmengen, aus denen die KI dann selbst Muster erkennt und anschließend die neuen Inhalte anhand dieser Muster generiert. Sind diese großen Datenmengen vorhanden, lässt sich generative KI erfolg- und ergebnisreich einsetzen. Weil aber in der Praxis häufig die Menge an Bildern fehlerhaft produzierter Teile fehlt, um darauf eine automatische Fehlererkennung aufzusetzen, oder die Menge an Maschinendaten nicht ausreicht, um Fehlervorhersagen zu treffen, hat generative KI in der Industrie ihre Grenzen. Wenn wenig Daten vorhanden sind, funktioniert ein Modell-basierter Ansatz oft besser, weil eine Struktur mitgegeben werden kann.
Das heißt, KNNs werden mit so vielen Information wie möglich gefüttert, um Muster zu erkennen, und modelbasierte KIs bekommen einen strukturierten Inhalt, damit sie wissen, wovon sie reden?
Genau, die beiden KI-Bereiche lassen sich grundsätzlich trennen. Datengetriebene KI-Verfahren, wie künstliche neuronale Netze, brauchen weniger technische Vorgaben, weil sie diese selbst aus dem Muster der Daten herauslesen. Dafür benötigen sie aber massive Mengen an guten und homogenen Daten. Und selbst wenn diese vorliegen, ist dann von außen nicht unbedingt ersichtlich, mit welchem Muster genau die Ergebnisse erzielt werden. Modellbasierte Ansätze erfordern vor der eigentlichen Beschaffung von Daten zunächst einen Spezialisten, der technische Vorgaben erstellt. Auf deren Basis können diese Ansätze dann auch robuster gegenüber kleinen und inhomogenen Datenmengen arbeiten.

Mit welchen Methoden werden KI-Algorithmen in der industriellen Produktion trainiert?
Das kommt immer auf den Use Case an. In den letzten Jahren wurde viel in Richtung Predictive Maintenance entwickelt und probiert. Hier nutzen Maschinen Sensordaten, um Muster zu erkennen. Wenn sich die Muster gefestigt haben, lassen sich Anomalien feststellen, etwa Druckluftverlust oder Materialverschleiß, auf die schließlich im besten Fall reagiert werden kann, bevor der Fehler eintritt. Damit dies funktioniert, braucht es allerdings eine große Menge guter und homogener Daten zur Mustererkennung. Daher funktioniert Predictive Maintenance wirklich gut und flächendeckend nur bei Standardkomponenten in großen Volumina, selten im Sondermaschinenbau.
Häufig werden mittlerweile auch bereits fertige, vortrainierte KI-Systeme eingesetzt. Kommerzielle LLMs beispielsweise finden so Anwendung, um bestehende Texte zu bewerten und semantisch durchsuchbar zu machen. Das KI-Modell selbst verändert sich dabei nicht mehr. Entscheidend für die Ergebnisqualität ist vielmehr, dass die Inputdaten schon sehr gut aufbereitet sind.
Bei unserem Ansatz, der KI einsetzt, um Expertenwissen als Assistenz im Servicefall zur Verfügung zu stellen, wird eine initiale Wissensbasis bereitgestellt und auf Basis erfolgreich durchgeführter Fehlerdiagnosen im Betrieb erweitert und optimiert. Es werden Diagnosedaten gesammelt, zuerst als konsistent oder sinnvoll bewertet und anschließend zur Verbesserung des Assistenzsystems genutzt. Wichtig dabei ist, dass solch eine Software dann auch rege Nutzung erfährt, um ausreichend Feedback und Trainingsdaten zu erlangen und Fehlerdiagnosen immer besser zu machen. Die Menge an Trainingsdaten hat dabei aber einen ganz anderen Umfang als bei generativen KI-Verfahren. Es sind nur wenige Nutzungen im zweistelligen Bereich notwendig und nicht mehrere tausend, was auch eher der erwartbaren Anzahl an Servicefällen pro Monat oder Jahr entspricht.
Welche technischen Entwicklungen erwarten Sie in absehbarer Zukunft bei für die Automatisierung geeigneter KI?
Bei dem Thema KI ist es so wie bei jedem Hype. Zu Beginn wird erst einmal viel ausprobiert. Das heißt, eine Technologie wird zugänglich gemacht, demokratisiert, viele Abteilungen, viele Lebensbereiche versuchen ihren Nutzen daraus zu ziehen oder ihre Use Cases zu finden. Die Realität zeigt dann, was möglich ist und was nicht.
Aktuell werden mit KI oft Mustererkennungen in großen Datenmengen durchgeführt, während wir bei FINDIQ KI zur Entscheidungsunterstützung durch menschliches Expertenwissen nutzen. In Sachen Entscheidungsunterstützung wird in der Industrie tatsächlich noch wenig gemacht, sodass ich hier großes Potential sehe. Auch in der Verbindung beider Verfahren gibt es viele Anwendungsgebiete, die bisher völlig unerschlossen sind.
Die schon bestehenden Modelle werden sich natürlich auch weiterentwickeln und verbessern. Denn je mehr Daten die Modelle erhalten, je mehr Input und Kontrollen zum Lernen entstehen, umso besser werden die Ergebnisse. Auch dort, wo aktuell noch Ungenauigkeit dominiert.
Schließlich bleibt es aber glücklicherweise immer noch in der Entscheidung des Menschen, bis wohin wir diese KI-Entwicklungen zulassen und wo wir bewusst sagen, »das ist jetzt ein Prozess, bei dem soll der Mensch noch mitdenken, da sollen der Mensch und die Empathie, die er mitbringt, eine Rolle spielen«.
Inwieweit stehen KI-Anwendungen bestimmte Limitierungen entgegen? Seien es technische, im Sinne der Software – oder auch im Bewusstsein der Anwender?
Wenn es Limitierungen gibt, dann sind sie häufig grundsätzlich technischer, industriell bedingter oder organisatorischer Natur. Es wird sich in den nächsten Jahren nichts daran ändern, dass Produktionsstätten einen sehr heterogenen Maschinenpark aufweisen. Dementsprechend bleibt die Skalierbarkeit dahingehend beschränkt, dass ein für eine bestimmte Maschine trainiertes Modell nicht automatisch für die nächste Maschine funktioniert. Auch wenn es dieselbe Technologie ist und wenn die Maschine im Grunde dasselbe tut, wenn nur eine Komponente anders oder eine Maschine ein Jahr älter ist als die andere, kann die Maschine wieder ganz anders funktionieren. Somit besteht einfach dauerhaft die Schwierigkeit, datenbasierte KI-Verfahren zu adaptieren. Und deswegen ist es ja so wichtig, KI-Verfahren differenziert zu betrachten und solche zu wählen, die mit wenig Daten auskommen, wenn bei jeder weiteren Maschine ein Datenmodell »von Null« aufgesetzt werden muss.
Das ist die Realität. Realität ist zudem, dass dort, wo noch keine Daten existieren, auch keine datenbasierte KI einen Nutzen bringen kann. Im Maschinenbau und -betrieb finden aktuell umfassende Umbauten und Retrofitting in Richtung regenerativer und nachhaltiger Produktionsverfahren statt. Das heißt, dass Maschinen neu aufgebaut werden und noch keine Datenbasis aufweisen. KI-Modelle müssen somit offen sein, im Laufe der Installation und des anlaufenden Betriebs neue Daten und neues Wissen zu generieren und clever aufzunehmen. Auch hier herrscht die Limitierung, mit wenig Anfangsdaten auskommen und trotzdem unsere neuen Wasserstoffanlagen, Energiespeicher oder Wärmepumpen intelligent betreiben und servicen zu müssen.
Eine weitere Grenze liegt in uns als Menschen, die sich die Frage stellen (sollten), inwieweit wir KI überhaupt zulassen wollen. Der Maschinenservice ist ganz klar dem technischen Umfeld zuzuordnen, bei dem sich nicht unbedingt vermuten lässt, dass es eine Rolle spielt, ob der Mensch mir im Servicefall zur Seite steht. Genauso ist es aber. Der bevorzugte Weg beim Maschinenstillstand ist immer noch der Griff zum Hörer, um mit einem Menschen zu sprechen und eine Lösung zu finden, vor allem aber auch Druck loszuwerden. Wenn es irgendwann die Personalnot erfordert, können KI-basierte Assistenzsysteme selektive »Servicehilfen« sein, aber nicht die direkte Alternative zum Menschen.
Eine dritte Limitation bilden sicherlich die organisatorischen Gegebenheiten der Unternehmen. Wenn über Jahre hinweg der Dokumentation von Wissen, zumindest dem »Glattziehen« von Stammdaten, keine Bedeutung beigemessen wurde, kann auch keine KI diese Versäumnisse aufholen. In diesem Fall müssen wir dann leider einen »Frühjahrsputz« vorschieben, bevor wir FINDIQ implementieren. Auch die Akzeptanz und der richtige Umgang mit neuen, digitalen, gar intelligenten Lösungen wollen gelernt sein. Oder anders: Ein falsch ausgewähltes KI-Verfahren auf Basis einer falsch vorbereiteten Entscheidungsgrundlage, eingesetzt auf einer falschen Datenbasis und genutzt von den falschen Personen – das ist die wirkliche Limitierung.

FINDIQ ist als Hersteller einer Software auf KI-Basis und als Anbieter zugehöriger Dienstleistungen tätig. Welches KI-Konzept verfolgt Ihr Unternehmen im Rahmen seiner Software und gegenüber seinen Kunden?
Mit FINDIQ haben wir eine Software mit umliegendem Konzept entwickelt, das wertvolles Kopf- und Erfahrungswissen von Serviceexperten nachhaltig nutzbar macht. Mit unserem Slogan »FINDIQ – Maschinenservice auf Expertenniveau« kommunizieren wir folgende Werteversprechen: Wir verarbeiten Expertenwissen, keine Daten. Denn Wissen ist etwas anderes als Daten. Um das zu veranschaulichen: Wenn die Maschine einen Temperaturwert meldet, ist das erst einmal ein Datum. Wenn das Datum in einen Kontext gesetzt wird, wird es zu einer Information, wie »kalt« oder »warm«. Erst mit dem Erfahrungsschatz langjähriger Serviceexperten wird diese Information zu Wissen und eine kalte oder warme Temperatur entweder als Normalzustand oder Fehler eines Produktionsschritts interpretiert. Das ist Wissen. Und dieses Wissen ist meist implizit, also in den Köpfen der Experten verankert. Was insofern die Herausforderung birgt, als dass es dort »herausgeholt« und explizit gemacht werden muss, bevor diese Menschen massenweise in den Ruhestand gehen.
Daher haben wir als erstes Alleinstellungsmerkmal einen Ansatz etabliert, der aus implizitem Expertenwissen eine explizite, strukturierte Datenbasis macht. Diese »Wissensbasis« ist dann unsere Alternative zu einem abgelegten Dokument wie einem Bedienungshandbuch (meistens zu ungenau) oder einer Sammlung historischer Daten (meistens zu unstrukturiert). Unser zweites »Steckenpferd« liegt in der Verarbeitung und vor allem der wirklich nachhaltigen Nutzbarmachung der Wissensbasis. Wir wollen nicht nur für einen einzelnen Use Case oder eine einzelne Maschine funktionieren und nicht nur im Rahmen von Pilotprojekten erfolgreich sein, sondern für ein ganzes Maschinenportfolio, alle Produktionsstandorte eines Unternehmens. Und hierzu muss es nicht nur unsere Aufgabe sein, das Wissen der letzten Servicegeneration abzulegen, sondern dieses auch für die nächste abrufbar zu machen. Erst dann ist Wissenstransfer erfolgt, vorher ist es nur Wissensmanagement.
Um den Wissenstransfer nicht nur einmalig oder kurzfristig, sondern langfristig gut und richtig zu leisten, kommt KI ins Spiel. Was dabei das konkrete richtige KI-Verfahren ist, bestimmt der Use Case.
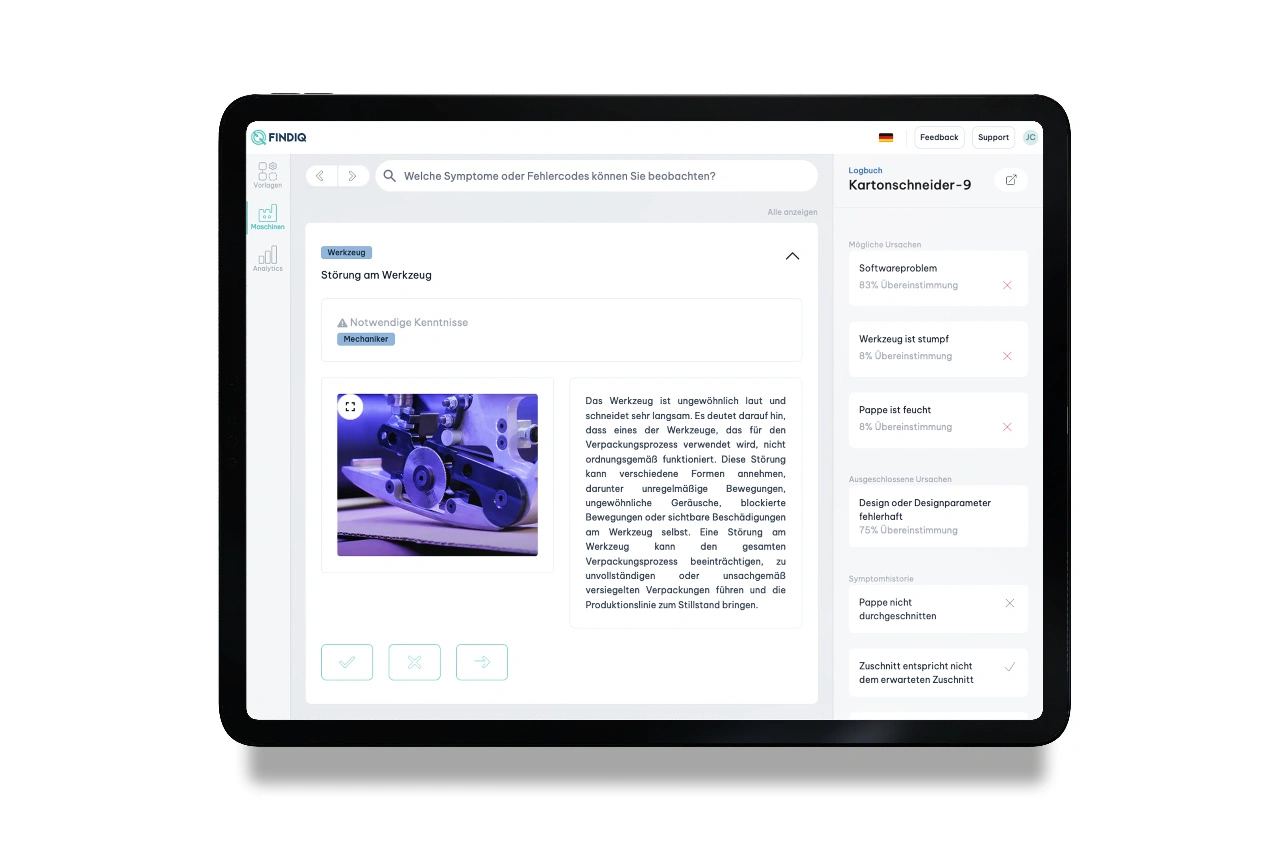
In unserem Fall bedingt das Thema »Wissenstransfer im Service«, dass die Experten, von denen wir das Wissen brauchen, oft nur ein bis zwei Stunden Zeit und Lust haben, ihr Wissen zu dokumentieren. Das bedeutet, dass diese »Eingabe-Arbeit« schnell, strukturiert und vor allem zielgerichtet erfolgen muss. Und nicht nur vorab, sondern später auch im Betrieb. Dementsprechend haben wir uns bei der Entwicklung unseres KI-Verfahrens dazu entschieden, mit wenig Daten zu lernen und eine Struktur und Richtung mitzugeben, in der gelernt wird. Unser Verfahren wird zuerst einmal für den Use Case der Fehlerdiagnose und -behebung angewandt, einem der kritischsten Prozesse im Service. Unser Algorithmus ist daher mathematisch insofern neu konzipiert, als er versucht, eben diese Fehlerzusammenhänge zu erschließen.
Fehlerwissen baut sich häufig aus Symptomen und Ursachen auf. Sprich: ein Fehler zeigt sich in Symptomen und hat eine Ursache. Über eine eigens entwickelte Kombination aus mehreren KI-Verfahren bilden wir genau diese Zusammenhänge ab. Durch die Verknüpfung von Symptomen und Ursachen über Wahrscheinlichkeiten machen wir die Wissensbasis erweiter- und optimierbar. Diese Selbstoptimierung übernimmt ein weiterer Feedback-Algorithmus, also ein weiteres KI-Verfahren. Das Verfahren dahinter wird als Reinforcement Learning bezeichnet und lässt einen Menschen beurteilen, ob ein Ergebnis gut ist und als Lerngrundlage genutzt werden soll. Damit machen wir unsere Lösung zum einen skalierbar, weil adaptierbar auch auf einen heterogenen Maschinenpark. Zum anderen erfolgt die Selbstoptimierung nicht in einer Black Box, wie bei den populären Sprachmodellen, sondern auf nachvollziehbare Art und Weise.
Welche Roadmap verfolgt das Unternehmen für die absehbare Zeit?
Mit FINDIQ haben wir uns vor zweieinhalb Jahren selbstständig gemacht, konnten aber davor jeweils etwa zehn Jahre beobachten und verstehen, warum unterschiedliche digitale Lösungen rund um den Maschinenbetrieb und -service sich nicht flächendeckend durchgesetzt haben. Zum Beispiel hat Predictive Maintenance (die Vorhersage von Produktionsfehlern und -stillständen) bei den meisten Industrieunternehmen oft nicht mehr als einen Pilotstatus erreicht, weil die Menge an notwendigen Daten in der tatsächlichen industriellen Realität zu gering ist und die Kosten zur Modellierung der Analysen und Vorhersagen viel zu hoch sind. Auch Augmented-Reality-Brillen, bei denen auf das reale Sichtfeld, etwa den Blick auf eine Maschinenkomponente, noch virtuelle Details wie Montageanleitungen eingespielt werden, finden kaum Anwendung. Die Technologie ist hilfreich, das Medium Brille ist allerdings schlicht störend in der Praxis.
Allein diese beiden Beispiele haben uns gezeigt, dass viele Hypes und Innovationsgelder nicht im Sinne der wirklichen Bedürfnisse der Menschen vor der Maschine ausgefallen sind. Ihnen fehlten keine visuellen Aufbereitungen von Maschinendaten, gar projiziert auf einer Brille. Ihnen fehlten grundlegende Sprach- und Fachkenntnisse zum täglichen Betrieb und schnellen Service der Maschinen. Und weil sich dies mit der zunehmenden Dezentralisierung von Produktion und Service, gepaart mit dem demografischen Wandel und Generationenwechsel in der Industrie, weiter verstärken wird, war der Entschluss gefasst: Wir entwickeln eine Software für den Transfer von Wissen im Maschinenservice, zunächst für die Unterstützung zur schnellen Fehlerdiagnose und -behebung.
Hierauf haben wir uns deshalb zuerst fokussiert, weil diese »Service-Tätigkeit« wenig standardisiert, sehr komplex und damit am meisten vom Wissen erfahrener Serviceexperten abhängig ist. Gleichzeitig ist sie auch besonders kritisch für die Produktivität, weil sie zu hohen ungeplanten Stillstandskosten führen kann, wenn sie schlecht oder zu langsam ausgeführt ist. Und durch das Ausscheiden der wenigen wissenden Experten passiert genau das: ein ungeahnter Anstieg an Stillständen, Umsatzverlusten und Ausschussraten. Das wollen wir abwenden.
Wenn wir unsere Produkt-Roadmap anschauen, entwickelt sie sich entsprechend dem Problem des Fachkräfteabgangs in Deutschland (und auch in den USA): Über die nächsten drei bis fünf Jahre flächendeckend. Das heißt, dass wir uns darauf einstellen, sämtliches ausscheidendes Expertenwissen über den Maschinenlebenszyklus digital abbilden zu müssen. Dazu schauen wir uns weitere Aktivitäten und Use Cases rund um den Betrieb und den Service von Maschinen und Anlagen an und bewerten, welche von ihnen ebenfalls produktivitätskritisch sind und besonders viel Expertenwissen fordern.
Um ein Beispiel zu geben: Eine Neumaschine wird installiert und in den Produktivbetrieb genommen. Sie erlebt erstmals das Umfeld des Kunden: die Temperatur ist anders, sie muss plötzlich kundenspezifische Materialien verarbeiten, und wird eingebettet in einen individuellen Produktionsablauf. Diese Inbetriebnahmephase bindet oft die erfahrensten Serviceexperten, die über Monate hinweg unerfahrene Servicetechniker des Maschinenherstellers begleiten und die Maschinenbediener auf Kundenseite anlernen. Sie erklären notwendige Routinearbeiten und dokumentieren Fehlverhalten, bislang allerdings wenig strukturiert und nachhaltig, sondern eher so, »wie es ihnen durch den Kopf geht«. Und genau diese Gedankengänge wollen wir strukturell erfassen und mit dem richtigen KI-Verfahren digital nachhaltig nutzbar machen, für den Fall, dass der Experte bei der nächsten Inbetriebnahme im Ruhestand ist.
Von diesen Use Cases, wir nennen sie auch »Wissensfelder«, haben wir entlang des Lebenszyklus einer Maschine etwa fünf bis sechs identifiziert, zu denen wir bis Ende 2025 Produkterweiterungen auf den Markt bringen wollen.
Parallel dazu werden wir auch besser darin, die Kunden bei der organisatorischen und prozessualen Integration unserer Software zu unterstützen. Wir haben früh damit begonnen, die Einführung unserer Software durch gutes Projektmanagement und Changemanagement zu unterstützen. Das haben wir auch deshalb getan, weil wir aus eigener Erfahrung heraus die Erfolgsfaktoren für eine nachhaltige Nutzung hierin sehen und nicht in kleinen Modifikationen der Software selbst. Unser Ziel ist immer, einen Kunden erst dann alleinzulassen, wenn die Software tatsächlich operativ und gern genutzt wird, und das ist bei allen unseren Kunden der Fall. Während dieser intensiven Betreuungsphase befähigen wir unsere Kunden dann immer stärker darin, unsere Wissenstransfer-Lösung selbst weiter zu »verbreiten«. Dazu bilden wir sogenannte Wissens-Agenten aus, die neuen Abteilungen, anderen Standorten oder gar externen Servicepartnern die Software und unseren Ansatz so erklären, dass sie global nutzbar wird.
In der Kombination bedeutet das, dass am Ende der Roadmap für unsere nächsten zwei bis drei Jahre wohl steht: Wir sind der digitale Service-Experte in der Hosentasche, mit all dem Service-Wissen rund um den Maschinenlebenszyklus.
Die Fragen stellte Andreas Knoll.
