Von der Datenablage zur Wissensquelle
Technische Kurztexte in der Automobilentwicklung
Die Auswertung und Verwendung technischer Kurztexte, wie sie in der Automobilentwicklung zuhauf auftreten, ist bislang kaum beherrschbar. Das Projekt AIdentify will das ändern. So sollen sich Inkonsistenzen in der Fahrzeugentwicklung und Trends in der Automobilindustrie leichter erkennen lassen.
Die Anzahl der Dokumente auf der Welt nimmt stetig zu. Es ist heute schon kaum noch möglich, dieser Flut an Dokumenten Herr zu werden. Natural Language Processing (NLP) kann dabei helfen, die Texte automatisiert auszuwerten und zu verarbeiten. Allerdings handelt es sich bei den Dokumenten häufig nicht nur um gut analysierbare Prosa, sondern in den meisten Fällen um Kurztexte wie Einsatzberichte von Servicetechnikern oder Reklamationen in einem Datenbank-basierten Ticketsystem.
Solche Texte fallen bei jedem Automobilhersteller an. Der Unterschied zu Prosa ist, dass die Texte von etlichen Autoren mit unterschiedlichem Hintergrundwissen erstellt wurden. Sie weisen oft Rechtschreibfehler, Codes, Abkürzungen, Mehrsprachigkeit und Umgangssprache auf. Damit stoßen die gängigen Natural Language Ansätze an ihre Grenzen. Genau an diesem Punkt setzt das Forschungsprojekt AIdentify an. Das Forschungsprojekt wurde vom Freistaat Bayern im Zuge des FuE-Programms »Informations- und Kommunikationstechnik« gefördert und war eine Zusammenarbeit zwischen der EDAG Group und der Firma denkbares.
Ein Automobilhersteller speichert Reklamationen von Vorserien- und Serienfahrzeugen sowohl von seinen Kundinnen und Kunden als auch aus Prüfstandstests in einem Ticketsystem ab. Diese Daten dienten der EDAG Group als Datenbasis. Die Tickets entsprechen exakt den problematischen Kurztexten: tausende unterschiedliche Autoren, viele Rechtschreibfehler, Codierungen und oft keine Grammatik. Viele der Tickets wurden bereits bearbeitet und sind zusammen mit ihren Lösungen in einer Datenbank gespeichert.
Aktuell wird diese Datenbank jedoch lediglich als Ablage und nicht als Wissensquelle verwendet. Das soll sich nun ändern. Das angestrebte Ziel ist die Ausgabe semantisch ähnlicher Texte auf Basis eines Eingangstextes. Es werden die Ansätze evaluiert und Empfehlungen für den Umgang mit technischen Kurztexten abgeleitet. Hierdurch erhalten die Mitarbeiterinnen und Mitarbeiter Zugriff auf Lösungen von ähnlichen Problemen. Sie können bei ihrer Arbeit mit technischen Kurztexten somit sinnvoll unterstützt werden und durch die Nutzung von vorhandenem Wissen effizienter und zielgerichteter agieren.
Modulare Pipeline
Es ist jedoch jeder Datensatz anders. Deshalb wurde eine modulare Implementierung verfolgt. Jedes Modul für sich ist konfigurierbar, ausführbar und auf die entsprechenden Daten anwendbar. Dadurch wird eine möglichst schnelle Domänenanpassung garantiert. Der schematische Aufbau der modularen Pipeline ist in Bild 1 dargestellt.
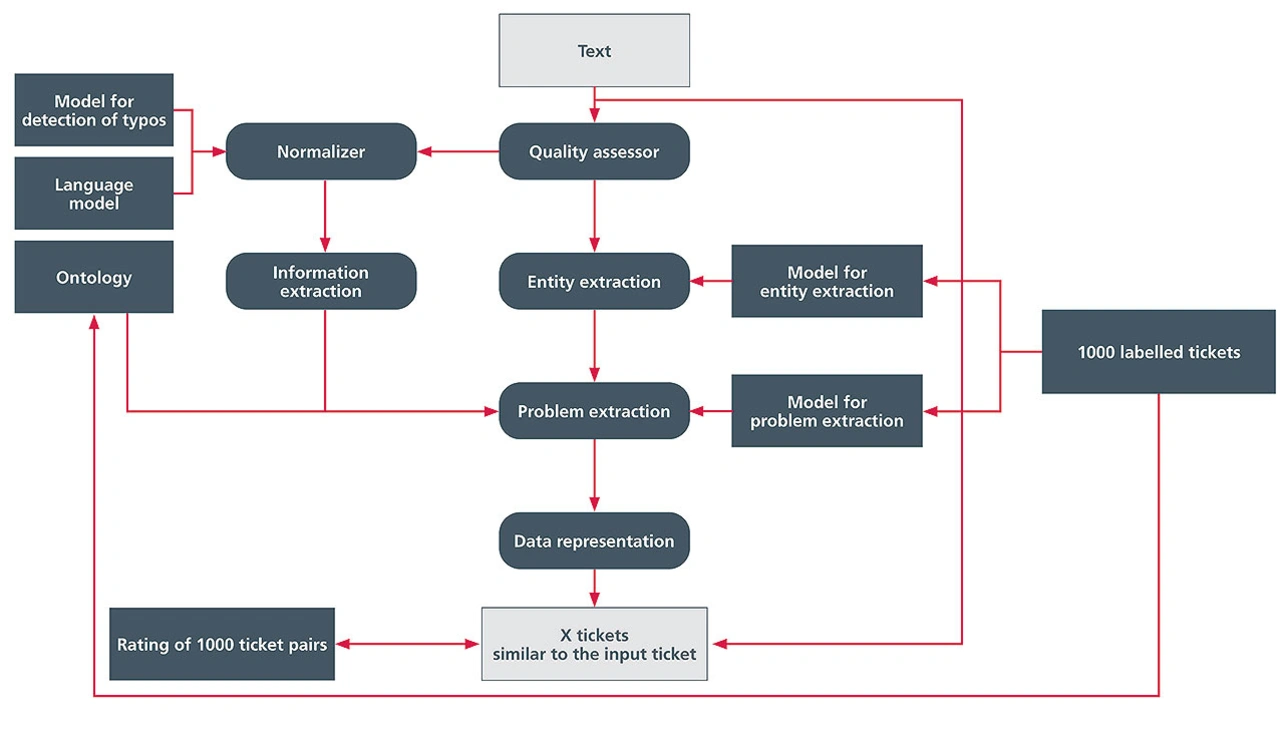
Die Textvorverarbeitung besteht aus dem »Normalizer« und dem »Quality Assessor«. Der Normalizer beinhaltet viele Funktionalitäten, die den Eingangstext vorverarbeiten. Mithilfe dieses Moduls werden beispielsweise Abkürzungen in ihre Langform überführt, Sonderzeichen verarbeitet oder auch Rechtschreibfehler korrigiert. Auf diese Weise werden die Texte einer Datenbasis vereinheitlicht dargestellt. Der Quality Assessor hat zwei Aufgaben: Zum einen überprüft er, ob ein Text von der Pipeline verarbeitet werden kann – dies berücksichtigt beispielsweise die unterstützte Sprache. Zum anderen wird überprüft, ob der Text überhaupt verwertbare Informationen enthält.
Zur Wissensextraktion gehören die Module »Information extraction«, »Entity extraction« und »Problem extraction«. Es wurden zwei Ansätze verfolgt, der Deep-Learning-Ansatz und der linguistische Ansatz. Beide Ansätze haben ihre Vor- und Nachteile. Für den Deep-Learning-Ansatz wurden zwei neuronale Netze trainiert. Das erste Netz extrahiert sinntragende Entitäten der Klassen »Fehlerart«, »Fehlerort« und »Fehlerbedingung«. Das andere Netz klassifiziert das Ticket in eine von 33 Fehlerklassen wie beispielsweise »Korrosion« oder »Montageproblem«. Im linguistischen Ansatz wird mit einer Ontologie gearbeitet. In dieser sind verschiedene Informationen wie zum Beispiel mögliche Fehlerarten, Fehlerorte oder verwendete Bauteile gespeichert. Anhand der Ontologie werden, wie auch im Deep-Learning-Ansatz die Entitäten extrahiert und die Fehlerklasse des Tickets bestimmt.
Um ähnliche Tickets zu finden, müssen die Tickets zueinander in Relation gesetzt werden. Dies passiert im Modul der Datenrepräsentation. Hierbei werden die Texte auf Basis der extrahierten Informationen in einem Vektorraum dargestellt. Sobald das Eingabeticket in den Vektorraum integriert wurde, ist es möglich, über die Abstände zueinander ähnliche Tickets zu bestimmen.
Deep-Learning- versus linguistischer Ansatz
Neuronale Netze haben den Nachteil, dass sie noch nicht vollkommen erklärbar sind. Das bedeutet, dass es teilweise nicht nachvollziehbar ist, wie sie zu einer Ausgabe kommen und sie zusätzlich eine gewisse Unsicherheit mit sich bringen. Durch Verfolgen des Deep-Learning-Ansatzes wird diese Unsicherheit in die Pipeline integriert. Es ist demnach möglich, dass beispielsweise ein Bauteil oder ein Name fälschlicherweise als Fehlerart ausgegeben wird.
Der Vorteil von neuronalen Netzen ist jedoch, dass sie auch Entitäten erkennen können, die ihnen nicht antrainiert wurden. Es ist daher nicht notwendig, alle relevanten Fehlerarten, -orte und -bedingungen in allen erdenklichen Schreibweisen im Trainingsdatensatz abzubilden. Genau das ist der Nachteil einer Ontologie: Eine Ontologie beinhaltet Konzepte und ihre Relationen zueinander. Die Konzepte entsprechen in diesem Fall den Entitäten. Ein Beispiel für die Relation ist »ein Türgriff ist ein Teil der Tür, die Tür ist ein Teil der Karosserie, die Karosserie ist ein Teil des Fahrzeugs«. Es können Synonyme, Abkürzungen, Kurzformen und viele weitere Darstellungsformen eines Wortes angegeben werden. Allerdings werden aus einem Text unter Zuhilfenahme einer Ontologie lediglich exakt die Entitäten extrahiert, die auch in der Ontologie benannt sind. Unterscheidet sich auch nur ein Buchstabe, so wird die Entität nicht extrahiert. Der Vorteil allerdings ist, dass die Ontologie vollständig nachvollziehbar und damit auch gezielt erweiterbar ist. Zusätzlich ist es hierbei möglich, Relationen und weitere Eigenschaften eines Konzeptes darzustellen. Diese können bei der Extraktion von Wissen hilfreich sein.
Belastende Evaluation
Es ist generell schwierig, die Güte der vorgeschlagenen Tickets hinsichtlich ihrer Ähnlichkeit zu quantifizieren. Eine gängige Ähnlichkeitsmetrik zu verwenden ist nicht zielführend, da auf diese Weise die Pipeline hin zur gewählten Metrik optimiert werden würde. Stattdessen sollte eine Ähnlichkeitsbewertung der Tickets durch die Benutzer als Maßstab verwendet werden. Diese Bewertungen sind jedoch mit Unsicherheiten behaftet, da sie zum einen keine Objektivität garantieren und zum anderen tagesabhängig sind.
Für die Evaluation wurden folglich drei Benutzer gebeten, 100 Testtickets hinsichtlich ihrer Relationen zu zehn weiteren zufälligen Tickets zu labeln. Insgesamt wurden dadurch 1.000 gelabelte Ticketpaare generiert. Da hierbei mehrere Benutzer labeln, wird die Subjektivität verringert. Zusätzlich wurde dieser Prozess auf mehrere Tage verteilt. Hierdurch wurde ebenfalls die Tagesabhängigkeit gemildert. Die Entwicklerinnen und Entwickler haben sich anschließend die Bewertungen angeschaut und unklare Fälle mit den Benutzern durchgesprochen. Durch diesen Vorgang wurde ein realitätsnaher Datensatz erzeugt. Es ist jedoch wichtig zu erwähnen, dass die Anzahl der bewerteten Ticketpaare für eine belastende Evaluation noch sehr gering ist. Insgesamt liegt ein Datensatz mit 1.000 Tickets vor. Die Anzahl der möglichen Ticketpaare lässt sich über den Binomialkoeffizienten
bestimmen. Es gibt demnach 499.500 mögliche Paare. Werden nun zu einem Eingangsticket die 100 ähnlichsten Tickets aus einer vorhandenen Datenbank ausgegeben, werden nicht alle Tickets im Testdatensatz vorhanden sein, sondern nur eine viel geringere Anzahl. Dies erschwert die Evaluation erheblich.
Die AIdentify Pipeline wurde entwickelt, um den Benutzerinnen und Benutzern ähnliche Tickets, die bereits gelöst wurden, anzuzeigen. Mithilfe dieses vorhandenen Wissens sollte die anwendende Person schneller zu einer Lösung des Eingabetickets gelangen. Wie viele ähnliche Tickets von der Pipeline zu einem jeweiligen Eingangsticket ausgegeben werden, wird vorher von der anwenden Person definiert.
Folgendes ist für die Evaluation wichtig:
➔ Möglichst viele Ticketpaare, die laut Bewertung eine hohe Ähnlichkeit zum Eingangsticket aufweisen, sollen in den ähnlichsten Tickets vorkommen
➔ Möglichst keine Ticketpaare, die laut Bewertung eine sehr geringe Ähnlichkeit zum Eingangsticket aufweisen, sollen in den ähnlichsten Tickets vorkommen
Das bedeutet, die Evaluierung konzentriert sich hauptsächlich auf die ähnlichsten Tickets.
Die zu betrachtenden Gütemaße sind Precision und Recall. Die Precision gibt an, wieviel Prozent der ausgegebenen Ticketpaare laut den Benutzern eine Ähnlichkeit aufweisen. Der Recall hingegen gibt an, wie viel Prozent der Ticketpaare, die von den Benutzern mit einer hohen Ähnlichkeit bewertet wurden, von der Pipeline tatsächlich ausgegeben werden.
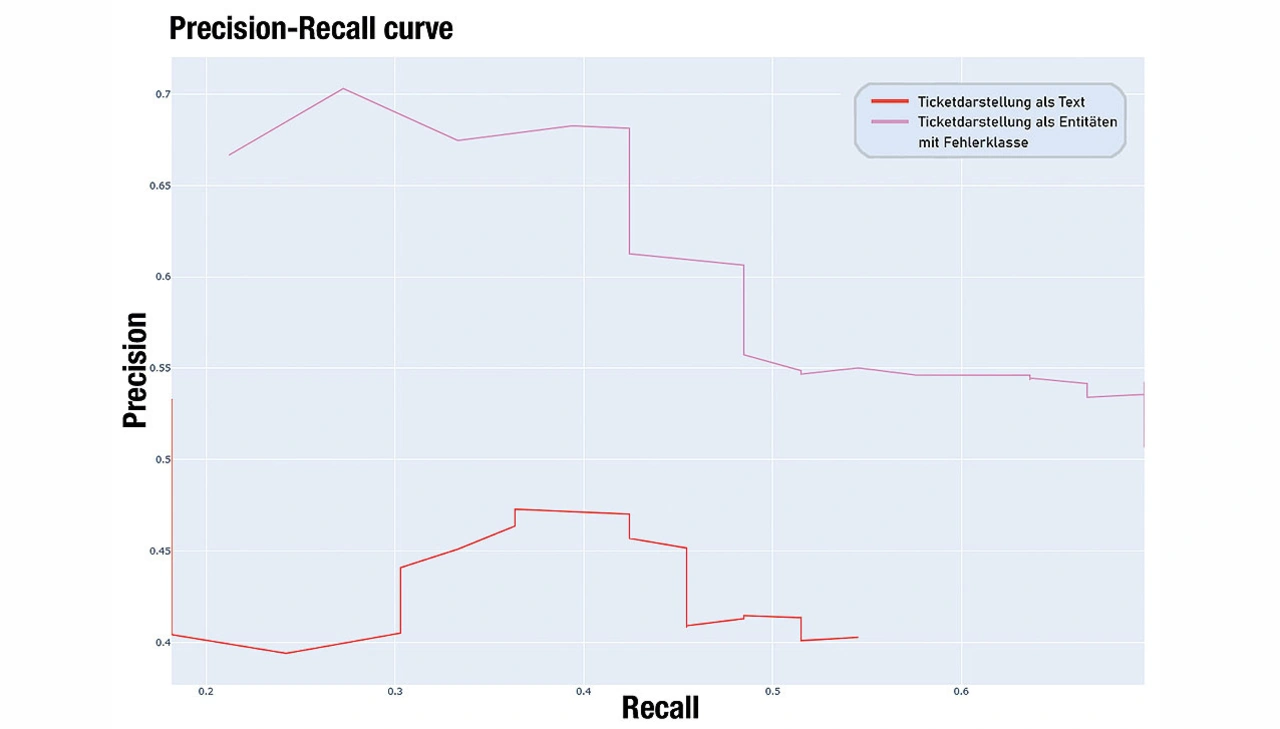
Auswirkung der Wissensextraktion
Markant sind die Auswirkungen der Wissensextraktion auf die Performance der Pipeline. Bild 2 zeigt die Performance von AIdentify unter Verwendung verschiedener Ticketdarstellungen. Die rote Linie verwendet das Ticket als reinen Text. In Rosa wird die Performance unter Verwendung der extrahierten Entitäten und Fehlerklasse dargestellt. Es ist ersichtlich, dass die Konzentration auf die sinngebenden Einheiten des Tickets zu einer deutlichen Verbesserung der Ergebnisse führt.
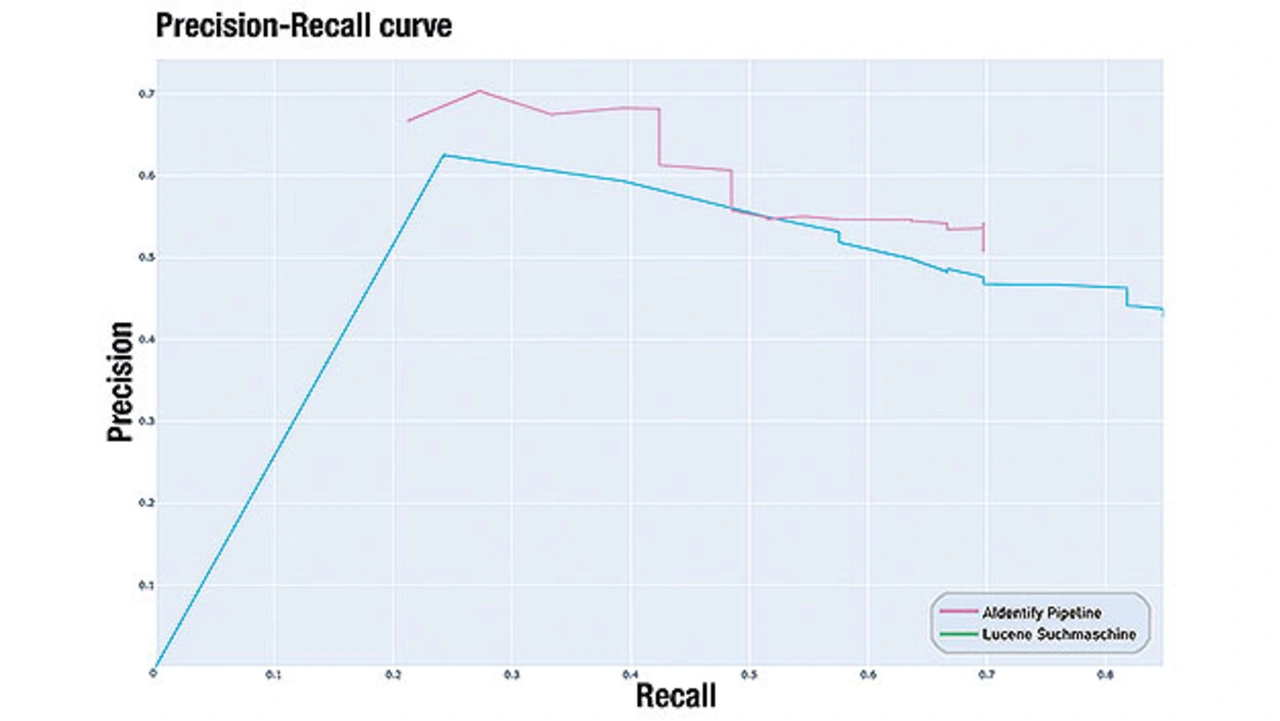
Vergleich AIdentify mit Baseline Lucene
Die entwickelte Pipeline wurde gegen eine Baseline evaluiert. Als Baseline wurde die Suchmaschine Lucene gewählt. In Bild 3 ist die Performance der beiden Ansätze dargestellt. Die Eingabe in Lucene und in die AIdentify Pipeline ist dieselbe. Es zeigt sich, dass die entwickelte Pipeline (rosa) nach zwei Jahren Entwicklungsarbeit bereits eine bessere Performance wie die Suchmaschine Lucene (grün) aufweist. Dieses Ergebnis verdeutlicht die Mächtigkeit des gewählten Ansatzes.
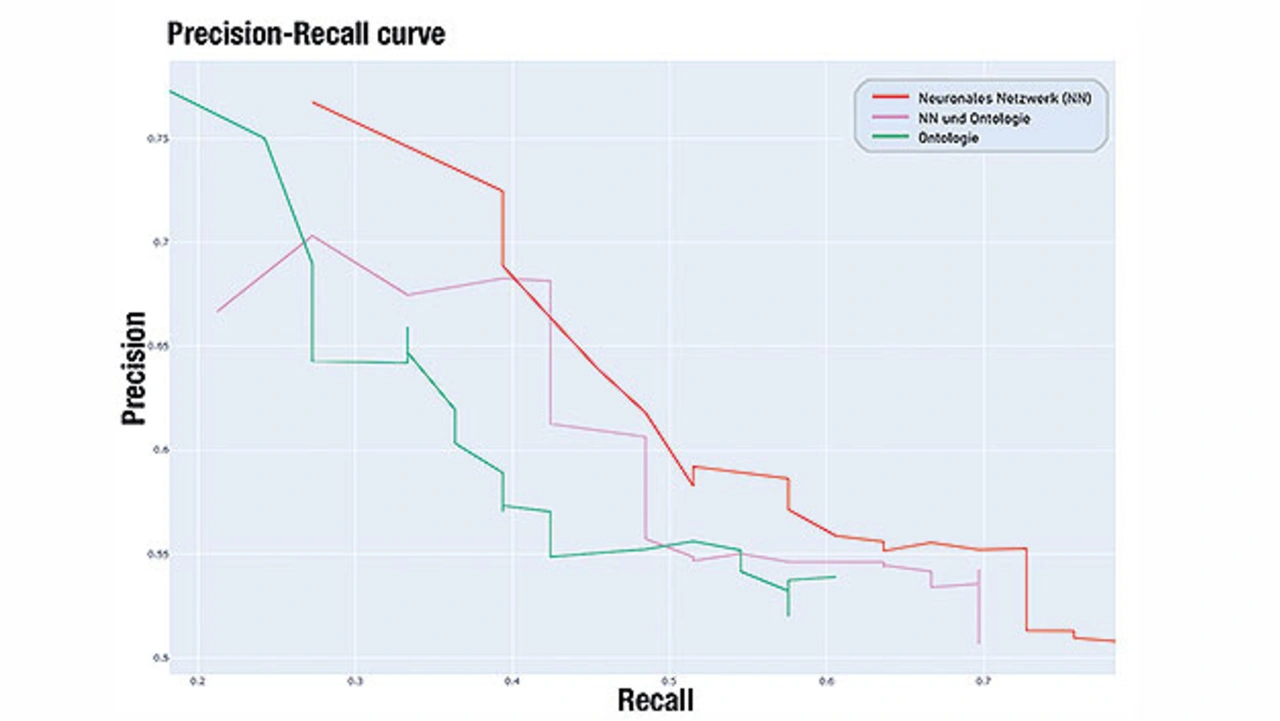
Vergleich von Deep-Learning-Ansatz und linguistischem Ansatz
Im weiteren Verlauf der Evaluation wurde der Deep Learning Ansatz gegen den linguistischen Ansatz evaluiert. Bild 4 zeigt drei unterschiedliche Konfigurationen der Pipeline. Die rote Linie stellt eine Pipeline dar, die sich ausschließlich auf den Deep-Learning-Ansatz stützt, die grüne Linie stützt sich ausschließlich auf den linguistischen Ansatz und in Rosa wird eine Kombination der beiden Ansätze dargestellt. In der aktuellen Evaluationsphase zeigt die Auswertung, dass der Deep Learning Ansatz dem linguistischen Ansatz überlegen ist.
Des Weiteren befindet sich die Performance der Kombination beider Ansätze zwischen den Performances der einzelnen Ansätze. Dieses Ergebnis ist überraschend. Es wurde erwartet, dass mehr Informationen auch zu einem besseren Ergebnis führen. Eine mögliche Erklärung hierfür ist die Wahl der Datenrepräsentationsmethode. Aktuell basiert die Erzeugung des Gesamtvektors für ein Ticket noch auf nicht auf der Domäne angepassten (das heißt feingetunten) Word Embeddings. Das bedeutet, dass die in der Wissensextraktion extrahierten Informationen nicht nach Worttyp oder Relevanz, sondern nur nach Häufigkeit im Dokumentenkorpus gewichtet werden.
Domänenadaption
Da jeder Datensatz andere Eigenheiten aufweist, ist es nicht möglich, solch eine Pipeline eins zu eins auf einen anderen Datensatz anzuwenden. Bei einer Domänenadaption müssen daher Änderungen an der Konfiguration vorgenommen werden. Hierbei zeigt sich der Vorteil des modularen Aufbaus. Es ist mit überschaubarem Aufwand möglich, einzelne Bauteile anzupassen oder gar auszutauschen. Für die Domänenadaption muss die Ontologie erweitert oder eventuell sogar neu erstellt werden.
Zusätzlich bedarf es auch einer Anpassung an den neuronalen Netzen. Diese sind speziell auf den vorliegenden Datensatz trainiert. Das bedeutet, dass sie bei Verwendung einer neuen Datenbasis leicht angepasst oder gar ganz neu trainiert werden müssen. Hierfür benötigt es eine gewisse Anzahl an klassifizierten Daten. Für eine schnelle und effiziente Anpassung können Hilfsprogramme entwickelt werden. Aktuell arbeitet die EDAG Group unter anderem an einer Methode zur semi-automatischen Ontologieerstellung.
Fortschritte durch AIdentify
Die von der EDAG Group entwickelte Pipeline AIdentify dient zur Extraktion ähnlicher Texte aus einer Datenbank. Diese ist nach zwei Jahren Forschungsarbeit bereits auf einem guten und funktionsfähigen Stand. Etliche Anwendungsfälle können mithilfe der Pipeline bearbeitet werden. Dazu zählen die Verbesserung der Textqualität, die Konsistenzprüfung in Tickets, die Wissensextraktion oder auch das Clustering. All das trägt dazu bei, Texte in einer Datenbank auszuwerten. Dadurch können beispielsweise ländertypische Fehler an Fahrzeugen, Trends in der Automobilindustrie oder Inkonsistenzen in der Entwicklung eines Fahrzeuges erkannt werden.
In naher Zukunft wird eine eingehende sechsmonatige Evaluation angestrebt, in der die Benutzerinnen und Benutzer die Pipeline in ihrem Arbeitsalltag anwenden und die ausgegebenen Tickets laufend bewerten. Dadurch wird ein besseres Bild der Güte der aktuellen Pipeline dargestellt. Die Pipeline wird anschließend weiter ausgebaut und optimiert. Ziel ist eine robuste und modulare Toolbox, die ohne viel Anpassungen auch auf weitere Anwendungsfälle und Datenbasen anwendbar ist. Das Forschungsprojekt »Künstliche Intelligenz zur semantischen Analyse technischer Kurztexte« (AIdentify) wird vom Bayerischen Staatsministerium für Wirtschaft, Landesentwicklung und Energie im Rahmen des Bayerischen Verbundforschungsprogramms (BayVFP) gefördert.
Der Autorin

Nathalie Klingler
belegte den Masterstudiengang Informatik (mit Schwerpunkt künstliche Intelligenz) an der Universität Ulm. Im Jahr 2019 startete sie ihre berufliche Karriere bei der EDAG Group in Lindau als Softwareentwicklerin. Sie ist hauptverantwortlich für die KI-Komponenten in diversen Projekten im Bereich Computer Vision und Natural Language Processing und arbeitet für die EDAG Group an dem Thema Explainable Artificial Intelligence.
