Edge-Learning-Tools auf KI-Basis
Cognex arbeitet mit KI-basierter OCR in Verpackungslinien
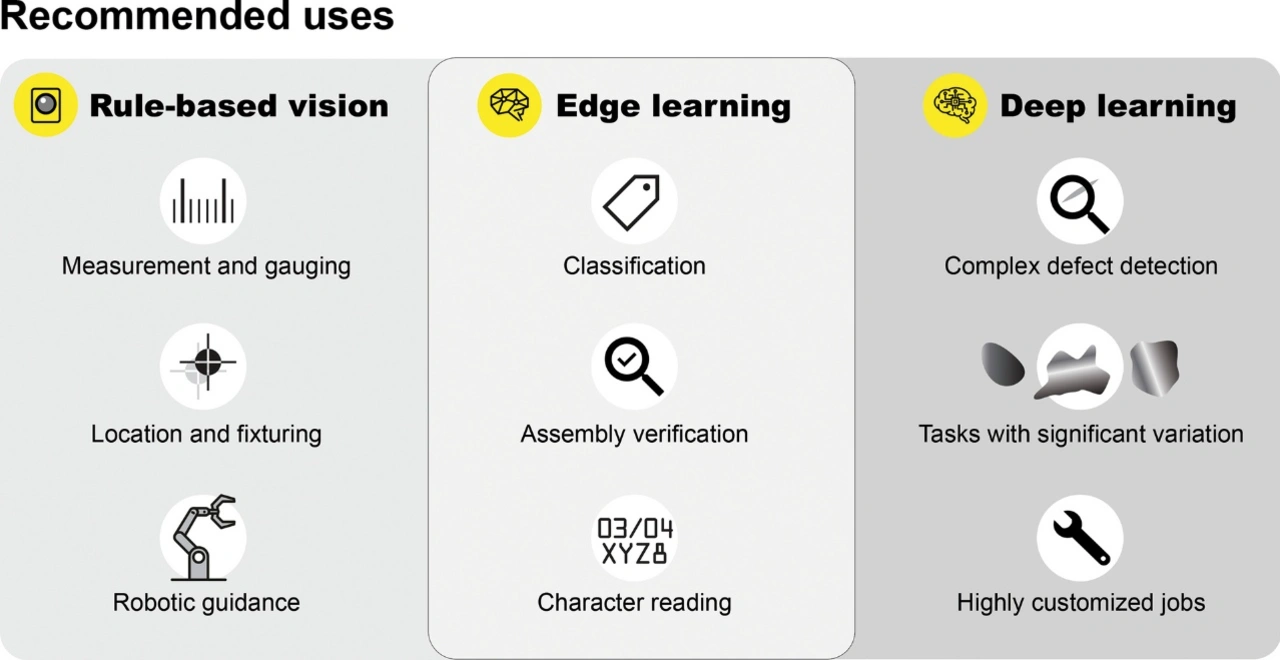
Edge-Learning, eine nutzerfreundliche Form der KI, eröffnet eine schnelle und zuverlässige Möglichkeit, Lieferketten mithilfe optischer Zeichenerkennung zu automatisieren. Edge-Learning ist der regelbasierten OCR überlegen und leichter zu konfigurieren als Systeme auf Deep-Learning-Basis.
Viele Branchen sehen sich mit zunehmenden Compliance-Anforderungen, der Nachfrage der Verbraucher nach detaillierten Verpackungsinformationen auf Losebene und dem Wettbewerbsdruck in puncto Geschwindigkeit und Effizienz der Lieferkette konfrontiert. Wegen strenger Vorschriften zur Rückverfolgbarkeit und zum Schutz vor Fälschungen hat die Pharmaindustrie eine Vorreiterrolle bei der Nutzung der optischen Zeichenerkennung (Optical Character-Recognition, OCR) für mehr Sicherheit über die gesamte Lieferkette hinweg übernommen. Dies erforderte erhebliche Investitionen, den Aufbau von Fachwissen und einen langen Lernprozess.
Angesichts unterschiedlicher Schriftarten und Trägermaterialien sowie der komplexen visuellen Umgebung von Fertigungs- und Logistiklinien war die Automatisierung von OCR-Applikationen schon immer eine Herausforderung, die nur mit geschulten Automatisierungsingenieuren, hohem Zeiteinsatz und beträchtlichem finanziellem Engagement zu lösen war. Auch bei bester Leistung konnten herkömmliche OCR-Systeme in puncto Genauigkeit allerdings nie annähernd 100 Prozent erreichen, was manuelle Eingriffe erforderte und den Durchsatz einschränkte. Die Anforderungen an Geschwindigkeit und Genauigkeit von Hochgeschwindigkeits-Lieferketten zeigen nun die Grenzen der herkömmlichen OCR auf.
Edge-Learning, eine nutzerfreundliche Form der künstlichen Intelligenz, bietet dagegen eine schnelle und zuverlässige Möglichkeit zur Automatisierung von Lieferketten mit OCR.
OCR-Anwendungsfälle und -Herausforderungen
OCR kommt schon seit langer Zeit in verschiedensten Anwendungen zum Einsatz. Dabei haben sich vier wesentliche Einsatzfelder herauskristallisiert:
- das Auffinden und Verifizieren alphanumerischer Zeichen,
- die Umwandlung von Codes in eine digitale Form, mit der sich jedes Teil oder Produkt in der Lieferkette verfolgen lässt,
- die Bestätigung, dass der gedruckte Code mit dem Teil oder Produkt und dem Barcode übereinstimmt,
- die Überprüfung, ob der entsprechende Code korrekt gedruckt wurde.
Trotz aller Praxistauglichkeit bringen herkömmliche OCR-Systeme gewisse Herausforderungen bei ihrer Nutzung mit sich. So erfordern sie eine präzise Beleuchtung und müssen mit unterschiedlich reflektierenden Materialien, einer großen Designvarianz von Verpackungen sowie teilweise unsauberen Drucken zurechtkommen. Wird auch nur eine dieser Bedingungen nicht optimal erfüllt, so erhöht sich die Fehlerquote.

Edge-Learning hat das Thema OCR verändert, indem es sowohl die Geschwindigkeit als auch die Genauigkeit erhöht und eine einfachere Anwendung in einer größeren Anzahl von Branchen und Situationen ermöglicht.
Intelligentere KI für einfachere OCR
Mithilfe von Edge-Learning lassen sich hochentwickelte KI-Algorithmen auf die spezifischen Anforderungen von Hochgeschwindigkeits-Lieferketten ausrichten, sodass OCR schnell und präzise arbeitet sowie einfach einzusetzen und schnell zu trainieren ist.
Herkömmliche regelbasierte OCR kann unter idealen Bedingungen eine Genauigkeitsrate von bis zu 98 Prozent erreichen. Bei den Mengen, die in modernen Lieferketten gehandhabt werden, führt diese Rate immer noch zu vielen Ausschussteilen, was den Gesamtdurchsatz verringert.
Vortrainierte Edge-Learning-Algorithmen übertreffen diese Genauigkeitsrate, denn sie sind auf die Herausforderungen beim Lesen von Text unter den Bedingungen von Fertigungs-, Prüf- und Logistiklinien zugeschnitten, die mit hoher Geschwindigkeit arbeiten. Die Edge-Learning-Verarbeitung wird dabei im Gerät selbst durchgeführt, direkt an der Fertigungs- oder Logistiklinie, ohne dass eine Kommunikation mit einem anderen Prozessor erforderlich ist. Dies führt zu Geschwindigkeitsvorteilen gegenüber herkömmlichen OCR-Systemen.
Komplexere Deep-Learning-Algorithmen auf KI-Basis sind ebenfalls in der Lage, OCR durchzuführen. Sie erreichen unter optimalen Bedingungen eine Genauigkeit von fast 100 Prozent und können jede Art von Text lesen lernen. Ihr Nachteil: Sie sind zu langsam für den unmittelbaren Einsatz an Fertigungs- oder Logistiklinien, erfordern hochentwickelte Prozessoren sowie umfangreiches Fachwissen bei der Implementierung. Für die jeweilige Anwendung vorab trainierte Edge-Learning-Tools erreichen jedoch aufgrund ihrer Spezifität die Genauigkeit generalisierter Deep-Learning-Systeme und sind dabei in der Lage, die von der Industrie geforderten Geschwindigkeiten zu erzielen.
Die hohe Geschwindigkeit und Genauigkeit von Edge-Learning-Tools lässt sich dabei durch Bildverarbeitungs-Hardware wie das Vision-System »In-Sight 3800« von Cognex sicherstellen. Die Smart Camera bietet einen CMOS-Bildsensor mit Global Shutter, eine integrierte Beleuchtung, ein Autofokus-Flüssiglinsen-Objektiv für schnelle Fokussierung und hohe Geschwindigkeiten sowie einen integrierten Prozessor. Ihre HDR+-Funktion ermöglicht verkürzte Belichtungszeiten, sodass sich Anwendungen mit schnelleren Liniengeschwindigkeiten realisieren lassen, und ihr kompaktes Gehäuse ist unempfindlich gegen Vibrationen. In-Sight 3800 ist einfach zu platzieren, mit Strom zu versorgen und mit einer Fertigungs- oder Logistiklinie zu verbinden, um Bilder zu erzeugen, die sich für die Edge-Learning-OCR eignen.
Trainingsaufwand reduziert
Herkömmliche regelbasierte OCR-Bildverarbeitungssysteme erfordern einen hohen Programmieraufwand bei der Einrichtung sowie Zeit, Fachwissen und eine Neuprogrammierung, wenn sich die Anforderungen ändern. Im Gegensatz dazu werden Systeme auf Deep-Learning-Basis trainiert, indem man ihnen spezifische, mit Tags versehene Bilder der entscheidenden Merkmale vorlegt. Deep Learning kann erstaunliche Fähigkeiten entwickeln, um feine Unterscheidungen zu treffen und Texte unter einer Vielzahl schwieriger Bedingungen exakt zu lesen. Um diese Genauigkeit zu erreichen, können jedoch Hunderte oder sogar Tausende von markierten Bildern für das Training erforderlich sein.
Für die vortrainierte Edge-Learning-OCR reicht dagegen schon eine kleine Zahl von Bildern zum spezifischen Anwendungsfall aus, um die Fähigkeit zu entwickeln, die gewünschten Schriften zu lesen. Für dieses spezifische Training der OCR ist kein spezielles Wissen über Bildverarbeitung oder KI-Algorithmen nötig, sondern lediglich die Kenntnis der erforderlichen OCR-Aufgabe.

Einfache Implementierung
Auch bezüglich der Implementierung bieten OCR-Systeme auf Edge-Learning-Basis Vorteile gegenüber regelbasierten oder Deep-Learning-Bildverarbeitungssystemen. So sind damit weder unterschiedliche Schriftenbibliotheken noch detaillierte Analysen der möglichen Fehllesung verschiedener Symbole nötig.
Herkömmliche OCR-Programme verwenden eine Reihe spezifischer Techniken, um die Gefahr der Fehllesung eines Symbols zu verringern, etwa spezielle Schriftenbibliotheken oder eine Feldeinteilung, die eine sorgfältige Definition jeder möglichen Stelle in einem Code und die Festlegung des Typs erfordert, sodass beispielsweise die Ziffer »8« in einem definierten numerischen Feld nicht fälschlicherweise als ein »B« gelesen werden kann.
Wenn die Edge-Learning-OCR einen Fehler macht, lernt sie, ähnliche Fehler in Zukunft zu vermeiden, indem der Bediener eine einfache Korrektur durchführt. Sie lernt von selbst, welche Merkmale für Genauigkeit sorgen – ohne spezielle Programmierung, Feldeinteilung oder andere zeitaufwendige Verfahren.
KI-Optionen integriert
Mit dem Bildverarbeitungssystem In-Sight 3800 lassen sich schnelle, präzise Prüfanwendungen auf KI-Basis realisieren. Das für Hochgeschwindigkeits-Produktionslinien konzipierte System stellt ein umfangreiches Vision-Toolset, leistungsstarke Bildverarbeitungsfunktionen und eine flexible Software bereit, um vollständig integrierte Systeme für eine breite Palette von Prüfanwendungen zu liefern. Ein wesentliches Element des In-Sight 3800 ist der umfangreiche Satz von Bildverarbeitungs-Tools, die sowohl die Edge-Learning-Technologie auf KI-Basis als auch traditionelle regelbasierte Algorithmen umfassen.
Mithilfe von In-Sight 3800 lassen sich somit zahlreiche Anwendungen zum Lesen von Klarschrift und zur Fehlererkennung an Codes in unterschiedlichen Branchen wie etwa Automotive, Lebensmittelproduktion und Logistik verwirklichen. Anwendern eröffnet sich die Chance, die Rückverfolgbarkeit von Produkten entlang der Lieferketten mit OCR zu erhöhen.
