Physik »inside«
Modelltransformation und automatische Codegenerierung
Der steinige Weg vom abstrakten Simulationsmodell zum Embedded-Code wurde im Forschungsprojekt »FMI for embedded systems« zur Schnellstraße ausgebaut. Mit dem neuen eFMI-Standard, der Modelltransformationen und Techniken zur Codegenerierung nutzt, lässt sich Software mit weniger Aufwand entwickeln.
Der Innovationsdruck, für moderne Fahrzeuge effiziente Betriebsstrategien zu entwickeln, ist ungebrochen. In konventionellen Antrieben sind es die steigenden Anforderungen hinsichtlich Emissionsreduktionen, für moderne Elektrofahrzeuge sind es die Kundenerwartungen hinsichtlich maximaler Reichweite bei uneingeschränktem Klimakomfort sowie minimalen Ladezeiten bei uneingeschränkter Lebensdauer der Batterie, die große Anstrengungen erfordern.
Fortschrittliche Regelstrategien und Diagnosefunktionen, unter Ausnutzung des Wissens über das physikalische Verhalten in Form von mathematischen Modellen, bieten Lösungsansätze, um über die Software ungenutztes Potenzial zu heben, wo Hardwarekomponenten in ihrer Leistungsfähigkeit bereits weitgehend ausgeschöpft sind – wie z. B. im Absatz »Anwendungsfall Volvo« betrachtet.
Zudem eröffnen sich neue Möglichkeiten für die Zusammenarbeit von Simulationsexperten aus der Systementwicklung mit Softwareentwicklern in der Funktionsentwicklung in Richtung von Modell-, Software- und Hardware-in-the-Loop- (MiL, SiL und HiL)-Simulationen bis zur Embedded-Software auf Basis eines durchgängigen Modells – wie z. B. im Absatz »Anwendungsfall Mercedes-Benz« erläutert. Bei alledem stellt sich die Frage, wie gut die generierten Lösungen im Vergleich zum Stand der Technik abschneiden und welche Kosteneinsparungen zu erwarten sind. Soviel vorweg: Erste Performance Assessments mit Werkzeugen des neuen eFMI-Standards liefern sehr ermutigende Ergebnisse, doch dazu mehr im Abschnitt »Studie Bosch«.
Vom Modell zum Code – die Herausforderungen
Ein mathematisches Modell bestehend aus Differenzialgleichungen und algebraischen Gleichungen auf einem Steuergerät zu lösen, ist nach dem Stand der Technik kein grundsätzliches Problem. Allerdings gilt es eine Vielzahl an Randbedingungen zu beachten, die zwingend einzuhalten sind. Dies gilt insbesondere, wenn es sich um Funktionen für sicherheitskritische Anwendungen handelt.
Wird ein mathematisches Modell eines physikalischen Systems in einem Simulationswerkzeug entwickelt, ist dieses typischerweise auf die Analyse des dynamischen Verhaltens ausgerichtet. Entsprechend stehen leistungsfähige numerische Lösungsverfahren zur Verfügung, die es erlauben, auf einem leistungsstarken PC ohne Echtzeiteinschränkungen – Stichwort Offline-Simulation – eine robuste Lösung zu berechnen. Ist man nun bestrebt, ein derartiges Simulationsmodell in Echtzeitanwendungen wie auf Hardware-in-the-Loop (HiL)-Prüfständen oder als Bestandteil einer Embedded-Software einzusetzen, besteht keine Möglichkeit, dies in automatisierter Weise zu tun.
Eine Reimplementierung als Embedded-Code, typischerweise als reiner C-Code, ist unausweichlich. Dies erfordert ein umfassendes Expertenwissen, das weit über das physikalische Verständnis und die mathematische Modellierung hinaus geht. Vielmehr bedarf es umfassender Kenntnisse in den Bereichen Numerik und Programmierstandards für Embedded-Software, z. B. MISRA C:2012, um schließlich zu einer Implementierung zu kommen, die den hohen Qualitätsanforderungen, wie z. B. im Automobilbereich, genügt, und auf den vergleichsweise leichtgewichtigen Embedded-Prozessoren robust und zuverlässig läuft. Handelt es sich dabei um nicht-triviale physikalische Sachverhalte, so ist zudem oftmals die notwendige Transformation in eine algorithmische Lösung aufwendig, wenn nicht sogar das Maß des praktisch Handhabbaren übersteigend – was im Umkehrschluss bedeutet: Reduktion des physikalischen Modells und seiner Qualität oder komplett anderer Entwurf.
Typische Anforderungen eingebetteter, sicherheitskritischer Software sind:
- Minimale Beanspruchung von Speicher für Daten und Code.
- Minimale Beanspruchung der CPU.
- Beschränkung auf Datentypen mit nur 32 bit statt 64 bit Gleitkommazahl-Genauigkeit (Floating-Point Precision).
- Beschränkung auf statische Speicherallokation.
- Garantiert ausnahme- und fehlerfreie Ausführung.
- Garantie, dass die Laufzeit im ungünstigsten Fall innerhalb der verfügbaren Grenzen liegt.
- Robuste numerische Lösung bei fester Abtastrate (Sampling Rate).
- Zuverlässige Behandlung von Operationen mit »Not-a-Number-« (NaN)-Rückgabewerten (IEEE 2019-07), teilweise undefinierten mathematischen Funktionen oder mehrdeutigen Lösungen.
- Garantierte Beschränkung von Signalen auf ihren Gültigkeitsbereich
Code, wie er von Simulationswerkzeugen für ausführbare Modelle oder für den Modellaustausch, z. B. FMI [1], generiert wird, genügt diesen Anforderungen bei Weitem nicht.
Die Technik des eFMI-Standards
Im Rahmen des europäischen öffentlich geförderten Projekts »EMPHYSIS – Embedded Systems with Physical Models in the Production Code Software« [2] (ITEA, Nr. 15016) wurde mit »eFMI – FMI for Embedded Systems« [3] ein neuer offener Standard entwickelt, der komplementär zum etablierten FMI-Standard (Functional Mock-up Interface, [1]) ist (Bild 1).

Ermöglicht FMI den Austausch und die Integration von Simulationsmodellen zwischen mehr als 150 Simulationswerkzeugen, so bietet eFMI eine flexible Container-Architektur, um auf Basis eines Target-unabhängigen Zwischenformats optimierten Code für unterschiedliche Zielplattformen und Softwarearchitekturen zur Verfügung zu stellen.
Für die Repräsentation von mathematischen Modellen als zyklisch aufrufbarer Algorithmus, wurde die neue Sprache GALEC (Guarded Algorithmic Language for Embedded Control) als Bestandteil des eFMI-Standards entwickelt. GALEC ist so konzipiert, dass ein in dieser Sprache formuliertes Berechnungsverfahren auf jeden Fall einen wesentlichen Teil der oben genannten Anforderungen erfüllt.
So wird z. B. die statische Allokation von Speicher dadurch ermöglicht, dass in der Deklaration von Vektoren und Matrizen die Dimension nur durch zur Compilierzeit berechenbare statische Ausdrücke definiert sein darf. Indizierungen in multidimensionale arithmetische Ausdrücke und ihre Größen sind statisch auswertbar und prüfbar. Laufvariablen von Schleifen müssen ebenfalls statisch begrenzt sein und eine Rekursion ist ausgeschlossen, sodass Laufzeitschranken garantiert werden können. Implizite Typumwandlung zwischen Integer- und Real-Variablen ist ausgeschlossen und einfache Namensräume ohne Überladung und Polymorphismus forcieren die Einhaltung entsprechender MISRA-C:2012-Regeln.
Des Weiteren bietet GALEC ein konsistentes Fehlerbehandlungskonzept mit garantierter NaN-Propagation und kontrollflussintegrierter Fehlerbehandlung; diese erlaubt die verzögerte Behandlung möglicher Fehler, ohne dass solche »verloren« gehen können. Auf diese Weise kann sichergestellt werden, dass ein mathematisches Modell, das in einem ersten Schritt in GALEC-Code transformiert wurde, in einem zweiten Schritt in Embedded-System-tauglichen und MISRA-konformen C-Code übersetzt werden kann. Für die beiden Schritte sind normalerweise zwei verschiedene Codegeneratoren zuständig, die jeweils auf »ihren« Schritt spezialisiert sind.
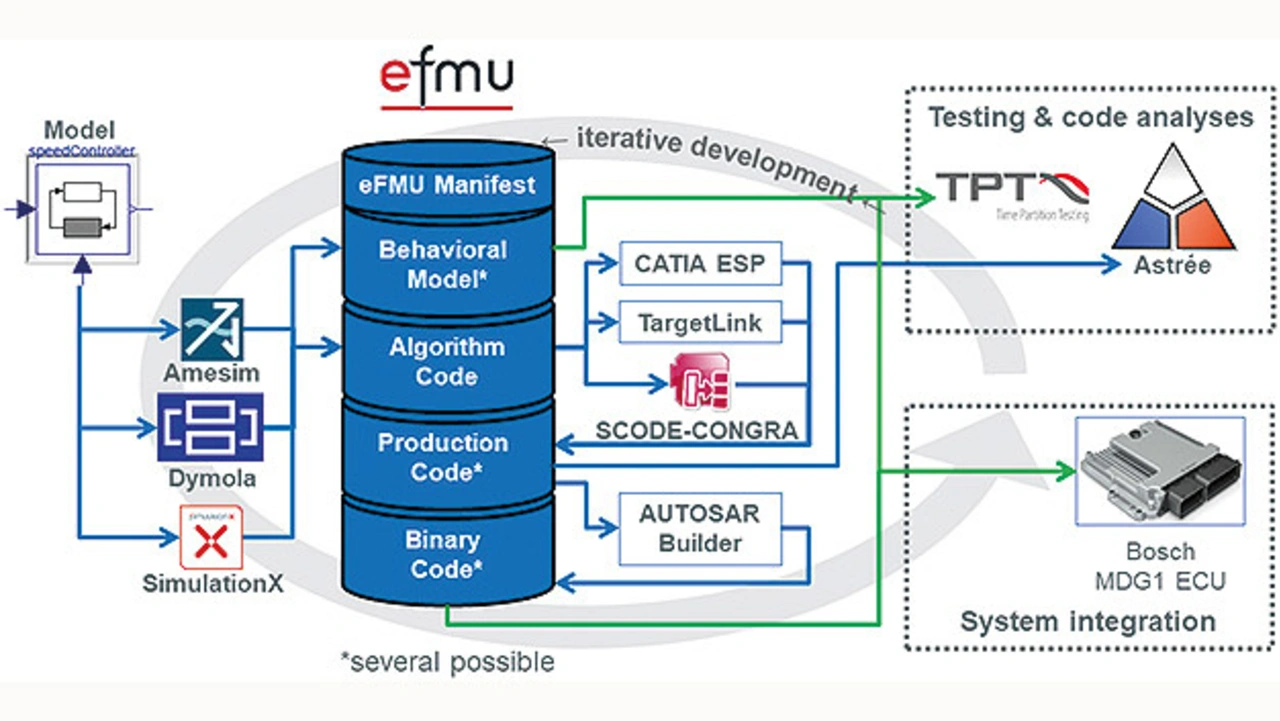
Eine Besonderheit des zweiten Codegenerierungsschritts von eFMI-GALEC nach Produktionscode ist die Möglichkeit, optimierten Code für unterschiedliche Architekturen bzw. unterschiedliche Prozessoren zu generieren. Diese unterschiedlichen Codevarianten können in mehreren, alternativen Production Code Containern innerhalb derselben eFMU (Functional Mock-up Unit for Embedded Systems) abgelegt werden, ohne die Verknüpfung zum selben Ausgangsmodell zu verlieren (siehe Bild 2). Sogenannte Manifestdateien in jedem eFMI-Container liefern die dazu erforderlichen Meta-Informationen.
Diese ermöglichen dem Productioncode-importierenden Werkzeug – ohne den Code syntaktisch oder semantisch analysieren zu müssen – allein aus den in XML geschriebenen Manifestdateien herauszulesen, welche Funktionsnamen, Funktionssignaturen, Datentypen und Servicefunktionen verwendet werden, um die passende Variante zu identifizieren und in das Embedded-Softwareprojekt zu integrieren. Die XML-Manifeste der verschiedenen eFMU-Container bieten zudem Meta-Informationen bezüglich ihrer Abhängigkeiten sowie Checksummen generierter Artefakte, sodass Rückverfolgbarkeit und automatisches Erkennen veralteter Softwareartefakte möglich sind.
Diese Mechanismen erlauben die Rückverfolgung des C-Codes bis zum Ausgangsmodell sowie die Verifikation des Verhaltens durch Testläufe – durch ebenfalls in der eFMU mitgelieferte Behavioral Model Container, die Re- ferenzszenarien zum automatischen Testen definieren.
Jobangebote+ passend zum Thema
- Modelltransformation und automatische Codegenerierung
- Der eFMI-Prozessablauf