Software-Entwicklung
Embedded-Linux-Systeme tracen – Teil 4
Im dritten Teil der Artikel-Reihe zeigten wir, wie man eine Linux-Anwendung mit maximaler Leistung konfiguriert. Im vierten Teil geht es darum, Tracealyzer für Linux zum Evaluieren der Userspace-Performance zu verwenden. Wollen Sie ebenfalls mehr Leistung für Ihre Anwendung herausholen?
In den vorangegangenen Teilen der Artikelserie ging es um das Analysieren eines Embedded-Systems durch das Tracen von Linux-Kernel-Ereignissen. Im dritten Teil zeigten wir beispielsweise wie Sie das Maximum aus einer Linux-Anwendung herausholen. Zweifellos ist es wichtig, zu gewährleisten, dass individuelle Abwandlungen des Linux-Kernels einschließlich der Gerätetreiber korrekt ausgeführt und performant sind. Einen noch höheren Stellenwert dürfte es für Anwender jedoch haben, ihre eigenen, im Userspace angesiedelten Anwendungen zu validieren und deren Leistungsfähigkeit zu gewährleisten.
Die weitaus meisten Entwickler von Embedded-Linux-Software schreiben fachspezifische Userspace-Applikationen, die nahezu immer recht komplex sind. Sie benötigen deshalb einen einfachen Mechanismus, um die Funktion ihrer Anwendungen zu validieren und deren Performance zu messen. Nachfolgend wird demonstriert, wie sich »LTTng-Tracepoints« setzen lassen und wie man mit Tracealyzer für Linux bestimmte Kennzahlen auf Basis der Tracepoints erfasst. Hierbei liegt der Fokus auf C/C++ – ähnliche Aspekte in Python sind Thema eines weiteren Beitrags.
Tracepoints sind Instrumentierungspunkte, die von der »LTTng Userspace Tracing Library« (LTTng-UST) bereitgestellt werden und dazu dienen, anwenderspezifische Daten als Ereignisse zu erfassen. Setzen lassen sich Tracepoints auf zweierlei Weise. Die erste Variante – »tracef« – bietet eine sehr einfache Möglichkeit zur Ausgabe aller Daten als ein einziges Ereignis, während die zweite Variante das Erfassen individueller Ereignisse ermöglicht. Letzteres erfordert deutlich mehr Code, bietet jedoch gleichzeitig maximale Flexibilität, um Daten zu sammeln und in Tracealyzer zu visualisieren.
In diesem Beitrag soll es um die tracef-Technik gehen, während die individuellen Ereignisse einem späteren Artikel vorbehalten sind. Wie schon erwähnt, ist tracef recht unkompliziert. So zeigt der folgende Codeausschnitt, wie man das Tracing in einem einfachen »Hello World«-Beispiel nutzt:
#include <lttng/tracef.h>
int main(void)
int i;
for (i = 0; i < 25; i++)
{
tracef("Hello World: %d", i);
}
return 0;
Die fett dargestellten Zeilen sind das einzige, was man für ein LTTng-Userspace-Ereignis benötigt, also das Einbinden der jeweiligen Header-Datei und das Aufrufen von tracef zur Ausgabe eines Userspace-Ereignisses, ganz ähnlich wie bei der klassischen »printf()-Funktion«.
Ist LTTng installiert?
Als erstes sollte man sich vergewissern, dass LTTng auf der Zielplattform installiert ist. Wie das geht, wurde im ersten Teil der Artikelserie beschrieben. Nach dem Übersetzen des obigen Codeabschnitts werden auf der Zielplattform die folgenden Anweisungen ausgeführt, um die Tracedaten für die Darstellung mit Tracealyzer zu erfassen:
lttng create
lttng enable-event -k sched_*
lttng add-context -k -t pid
lttng add-context -k -t ppid
lttng enable-event -u ‘lttng_ust_tracef:*’
lttng add-context -u -t vtid
lttng start
<run the userspace application>
lttng stop
lttng destroy
Die fett dargestellten Elemente sind am wichtigsten, da sie das Erfassen von Userspace-Daten freigeben und die Applikation ausführen.
Interessant an den obigen Befehlen ist, dass ebenfalls Kernel-Traces erfasst werden. Das geschieht aus zwei Gründen: Erstens lässt sich mit der Hinzunahme von Kernel-Tracedaten oftmals der zeitliche Ablauf der Userspace-Ereignisse verdeutlichen. Wenn zum Beispiel eine lange Zeitspanne zwischen zwei Ereignissen in der Applikation liegt, dürfte sich mit den Kernel-Ereignissen die Ursache dafür ermitteln lassen. Zweitens benötigt Tracealyzer in der Version 4.4.4 noch einige Daten aus dem Kernel-Trace, um UST-Ereignisse korrekt darstellen zu können (auch wenn nicht unbedingt der komplette Kernel-Trace erforderlich ist). Das Percepio-Team ist sich der Problematik bewusst und arbeitet an einer Lösung für ein künftiges Release.
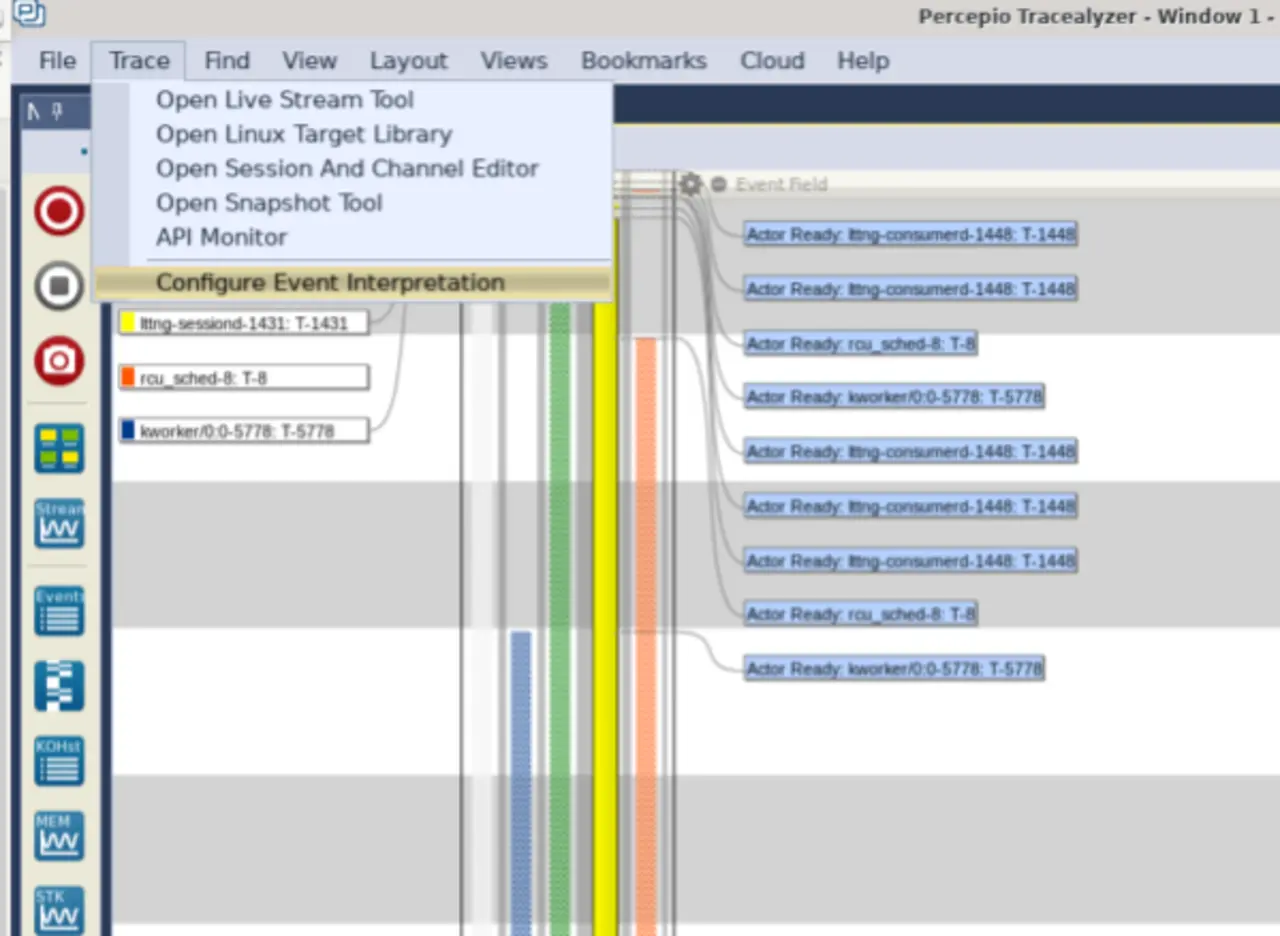
Wurde ein Datensatz generiert, wird er im nächsten Schritt in Tracealyzer für Linux geöffnet. Nach dem Öffnen des Trace ist Tracealyzer als erstes anzuweisen, wie die Userspace-Ereignisse zu parsen und zu visualisieren sind. Zu dem Zweck wählt man in der oberen Leiste den Menüpunkt »Trace« und klickt anschließend auf »Configure Event Interpretation« (Bild 1).
In dem sich daraufhin öffnenden Fenster wird in der Spalte »Channel Name« der Eintrag »lttng_ust_tracef:event« markiert und die Schaltfläche »Change« angeklickt. In dem folgenden Fenster ist ein Klick auf die Optionsschaltfläche »User Event Mapping« erforderlich, damit nach einem Klick auf »Next« der in Bild 2 abgebildete Konfigurations-Bildschirm erscheint.
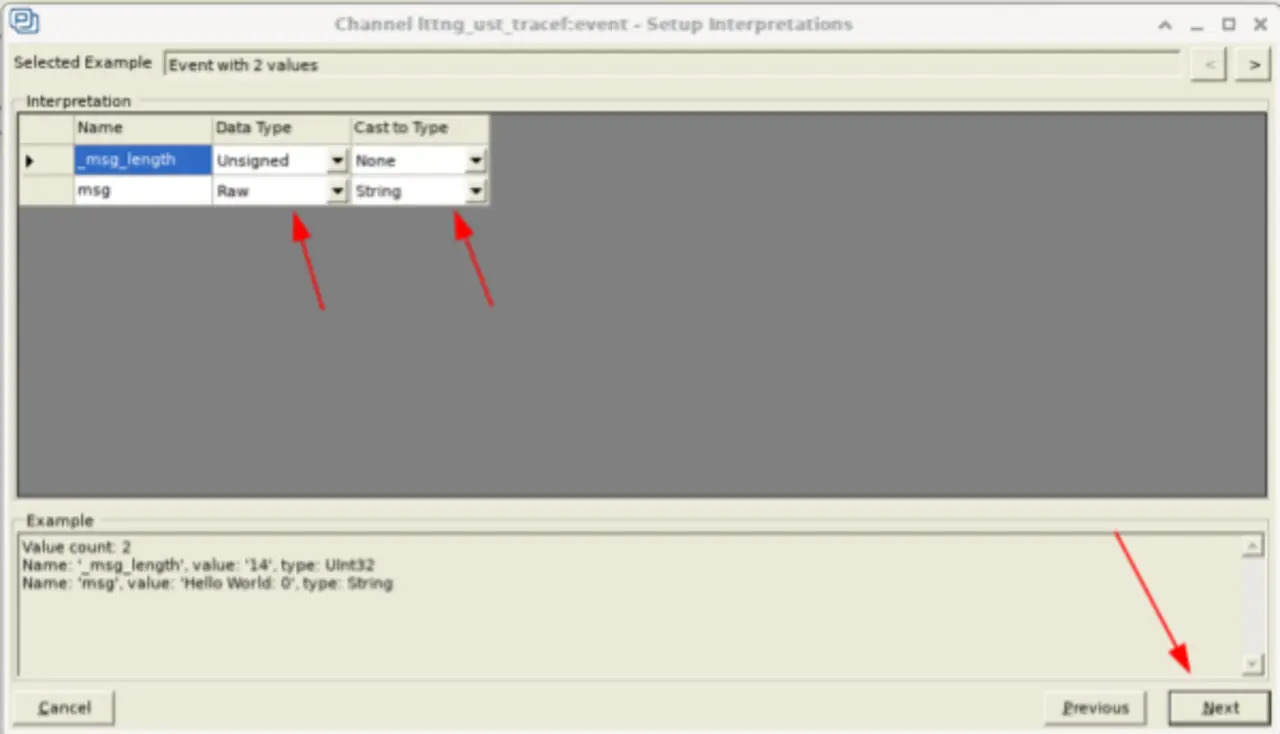
Die zweite Spalte (Data Type) ist der Datentyp eines jeden Feldes, wie von LTTng ausgegeben, die dritte Spalte trägt die Bezeichnung »Cast to Type« und dient dem bedarfsweisen Ändern des Datentyps. Wenn beispielsweise ein Userspace-Tracepoint einen numerischen Wert als String aufzeichnet, kann der String mithilfe der Spalte Cast to Type in einen Integer-Wert (Ganzzahl) verwandelt werden. Dieser Integer-Wert lässt sich daraufhin in Tracealyzer-Ansichten verwenden, etwa im »User Event Signal Plot«. Allerdings setzt das Casting einen rein numerischen String voraus, sodass seine Verwendung in dem Fall ausscheidet. Somit bleibt das Mapping unverändert und man lässt Tracealyzer die Länge der Nachricht ausgeben, um die Funktion zu demonstrieren. Tatsächlich gibt es bessere Möglichkeiten zum Aufzeichnen numerischer Werte mit LTTng-UST, wie in einem späteren Beitrag erläutert.
Lässt man die Spalten unverändert und klickt in diesem sowie im nächsten Fenster auf »Next«, im letzten Fenster dann auf »Finish«, so gelangt man wieder zum Hauptfenster »Event Interpretation«, in dem auf die Schaltfläche »Apply and Reload Trace« geklickt werden muss. Sobald Tracealyzer den Trace erneut geladen hat, kann es an die eigentliche Arbeit gehen. Mit Anklicken der Schaltfläche »User Events« in der linken Icon-Liste gelangt man zu der Ansicht »User Event Signal Plot«.
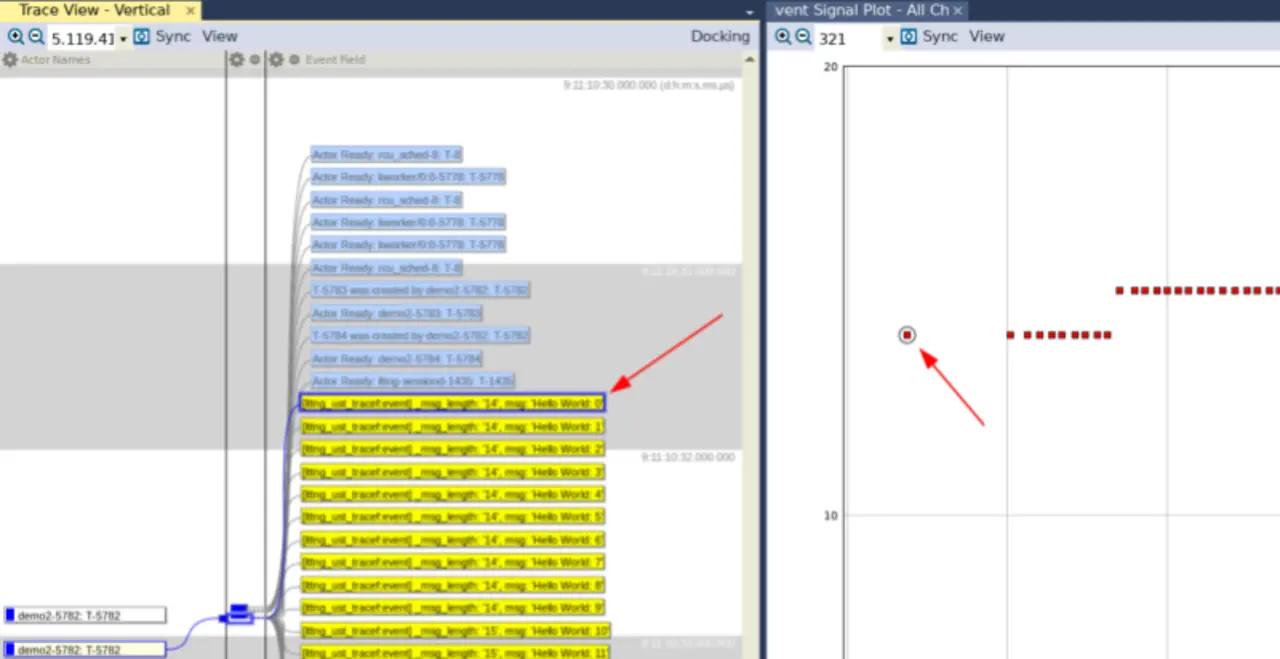
Messen der Performance
Im User Event Signal Plot scheint es lediglich zwei Datenpunkte zu geben, obwohl tracef in Wirklichkeit 25-mal aufgerufen wurde. Erhöht man den Zoomfaktor, erkennt man jedoch mehrere Punkte, bei noch näherem Heranzoomen werden alle 25 Aufrufe der tracef-Funktion sichtbar. Wie man sieht, erhöht sich der Wert (Y-Achse) nach zehn Aufrufen, da dann die String-Länge um ein Zeichen wächst. Klickt man einen Punkt an (rechts im folgenden Bild), markiert Tracealyzer außerdem den zugehörigen Aufruf in der linken Trace-Ansicht (Bild 3).
Als nächstes soll versucht werden, mit Tracealyzer die Leistungsfähigkeit einer Userspace-Anwendung zu messen. In diesem Beispiel wird dazu mit der »usleep«-Funktion von Linux eine Funktion imitiert, deren Ausführung eine bestimmte Zeitspanne in Anspruch nimmt. Zu dem Zweck wird vor und nach dem Funktionsaufruf je ein Tracepoint eingefügt, damit der Anwender die Zeit, die die Funktion zum Ausführen benötigt, messen kann:
#include <stdlib.h>
#include <unistd.h>
#include <lttng/tracef.h>
int main(void)
int i;
for (i = 0; i < 25; i++)
{
tracef("Start: %d", i);
usleep(25000);
tracef("Stop: %d", i);
}
return 0;
In einem realen Anwendungsfall würde man die tracef-Aufrufe an jenen Stellen einer Applikation einfügen, an denen die Verarbeitungszeit zu messen ist. Zum Beispiel kann es sein, dass es für eine bestimmte Funktion verschiedene Implementierungs-Varianten gibt und man den schnellsten Algorithmus herausfinden möchte. Ebenso kann es darum gehen, das Verarbeiten einer komplexen Funktion zu charakterisieren.
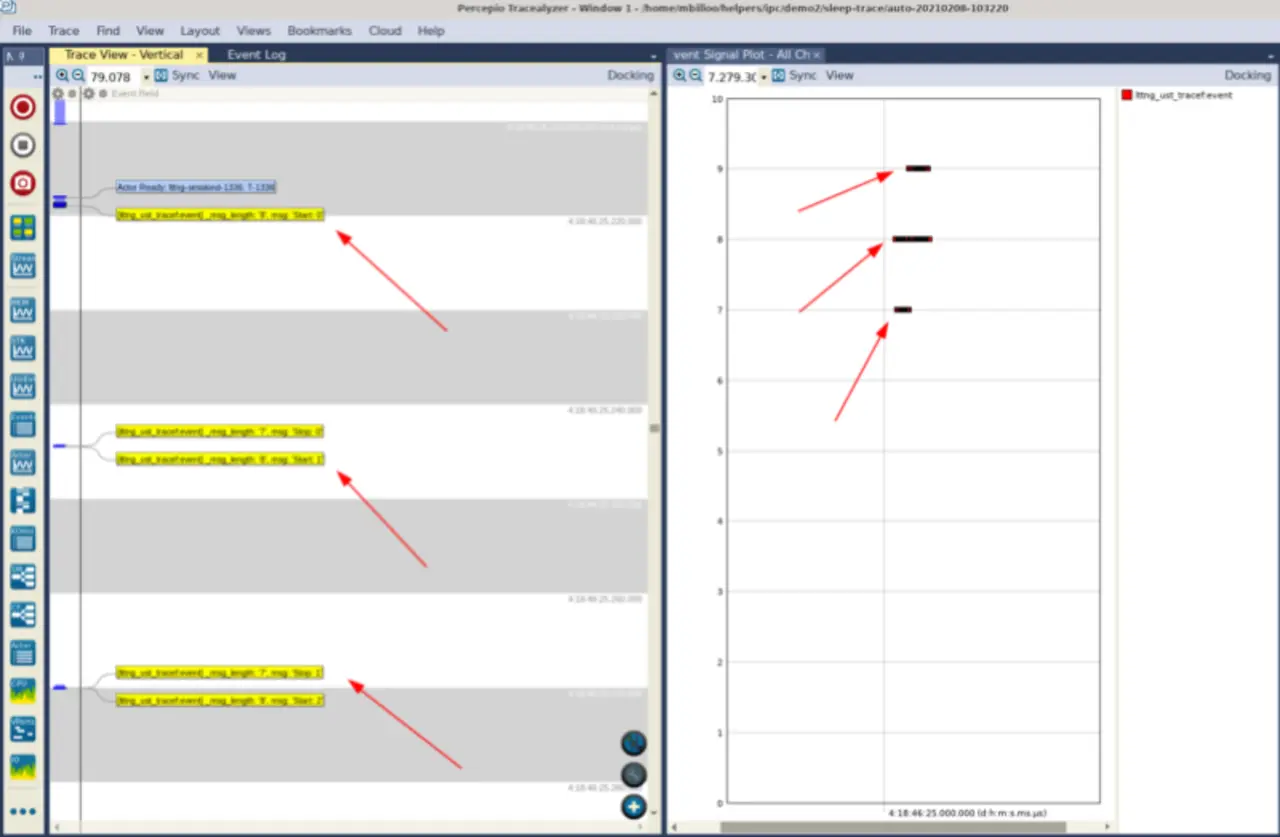
Ist die obige Applikation kompiliert, ist auf dem Zielsystem eine LTTng-Session zu starten, um die resultierenden Trace-Daten zu erfassen und herunterzuladen. Anschließend lassen sich die Trace-Daten in Tracealyzer öffnen. Stellt man den Filter so ein, dass lediglich Ereignisse aus der gewünschten Applikation gezeigt werden (demo2-sleep), und zoomt die Trace-Ansicht heran, so erkennt man das vertraute Trace-Ereignis (Bild 4).
Jetzt soll die Verarbeitungszeit der usleep-Funktionsaufrufe gemessen werden, die sich in diesem Fall als die Zeitspanne zwischen den einzelnen Start- und Stop-Ereignissen definieren lässt. In Tracealyzer lässt sich das am besten bewerkstelligen, indem man »Intervals« für die User Events erstellt. Hierzu wird im Menü »Views« der Menüpunkt »Intervals« and »State Machines« gewählt. In dem sich daraufhin öffnenden Fenster gelangt man durch einen Klick auf »Custom Intervals« zum Konfigurationsfenster hierfür. Hierin kann der Anwender einen neuen Datensatz definieren, der aus Intervallen zwischen ausgewählten Ereignissen besteht. Auf die Weise ist es möglich, Timing-Informationen von wichtigen Punkten der Applikation zu beziehen.
Jobangebote+ passend zum Thema
- Embedded-Linux-Systeme tracen – Teil 4
- Definieren eines individuellen Intervalls