Software-Entwicklung
Embedded-Linux-Systeme tracen – Teil 3
Im Oktober 2020 starteten wir mit unserer Artikel-Reihe über das Tracen von Embedded-Linux-Systemen mit Tracealyzer 4.4. Im dritten Teil zeigen wir, wie man eine Linux-Anwendung mit maximaler Leistung konfiguriert. Hierzu sind verschiedene Messungen nötig.
Im dritten Teil zeigen wir nun, warum es beim Entwickeln einer Anwendung für ein Linux-basiertes System darauf ankommt, das System für eine maximale Leistung zu konfigurieren. Andernfalls kann die Leistung der Anwendung aufgrund der fehlerhaften Konfiguration leiden. Am Beispiel einer Anwendung zum Empfang und dem Aufbereiten von Daten aus einer Software Defined Radio (SDR)-Einheit soll das verdeutlicht werden.
Die SDR-Einheit gab die Daten mit einer sehr hohen Rate aus und dementsprechend wichtig war es, die Paketverluste auf ein Minimum zu reduzieren. Leider traten nach dem ersten Hochfahren des Linux-Systems erhebliche Paketverluste auf, deren Ursache zu ermitteln waren. Anfänglich wurde vermutet, die sogenannte CPU-Affinität der Anwendung war möglicherweise nicht korrekt eingestellt. Zwar war für das Team zum damaligen Zeitpunkt noch kein Tracealyzer für Linux verfügbar, dennoch erwies sich die Vermutung damals als falsch.
Versuchsaufbau nötig
Ungeachtet dessen ist es jedoch interessant, nachträglich mithilfe von Tracealyzer zu ergründen, weshalb falsch vermutet wurde. Da jedoch weder das ursprüngliche System noch die Anwendung oder die SDR-Einheit noch verfügbar sind, ist ein Ersatz nötig. Als Linux-System kommt dabei ein Jetson Nano zum Einsatz, »iperf« dient als Userspace-Anwendung und ein weiteres Linux-System übernimmt die Rolle des SDR. Bei iperf handelt es sich um eine Umgebung, die Entwickler häufig zum Testen der Leistung von Netzwerkverbindungen zwischen zwei Linux-Systemen verwenden. Bild 1 zeigt die Versuchsanordnung.
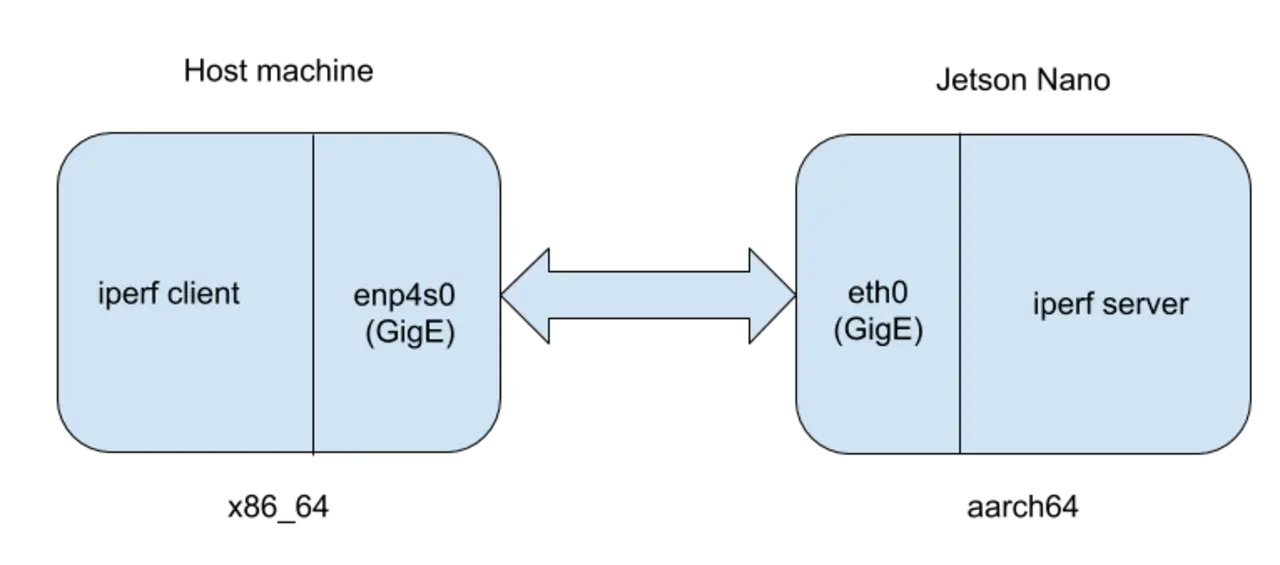
Rechts ist der Jetson Nano (mit 64-Bit Arm-Architektur) zu sehen, auf dem iperf im Server-Modus läuft. Auf dem links dargestellten Host-System (mit x86 64-Architektur) läuft iperf dagegen im Client-Modus. Die CPU-Affinität des iperf-Servers auf dem Jetson Nano lässt sich anschließend verändern, um festzustellen, wie der Parameter den Gesamtdurchsatz zwischen Client und Server beeinflusst.
CPU-Affinität bestimmen
Der Begriff »CPU-Affinität« bezeichnet den Umstand, dass ein Verarbeitungskontext an einen speziellen CPU-Core gebunden ist. Meist ist das anhand der Anwendung vorgegeben. Man sollte vermuten, dass die Paketverluste minimiert werden, wenn die CPU-Affinität des Interrupts und des zugehörigen Handlers mit der CPU-Affinität des Prozesses übereinstimmt, der die Pakete empfängt. In dem Fall verschenkt der Anwender keine Zeit mit dem Hin- und Herübertragen von Daten zwischen den Cores.
Um dem Sachverhalt auf den Grund zu gehen, ist zunächst die Affinität des »eth0«-Interface des Jetson Nano zu bestimmen, um zu erfahren, welcher Prozessorkern die Interrupts von eth0 bearbeitet. Hierzu ist der folgende Befehl auf dem Jetson Nano auszuführen:
$> cat /proc/interrupts/ | grep eth0
407: 1881331 0 0 0 Tegra PCIe MSI 0 Edge eth0
Wie zu sehen ist, verarbeitet der erste Core (CPU0) die Interrupts. Als nächstes wird iperf im Server-Modus auf dem Jetson Nano ausgeführt:
$> iperf -s -B 192.168.2.247 -p 5001
Nach wie vor auf dem Jetson Nano, werden anschließend die folgenden Befehle verarbeitet, um die standardmäßig vorgegebene CPU-Affinität zu ermitteln:
$> ps ax | grep iperf
12910 pts/0 Sl+ 1:25 iperf -s -B 192.168.2.247 -p 5001
$> taskset -p --cpu-list 12910
pid 20977's current affinity list: 0-3
Der erste Befehl ruft die Prozess-ID (PID) des iperf-Befehls ab. Die PID ist im taskset-Befehl zusammen mit dem Flag-cpu-list zu verwenden, um zu ergründen, welche Prozessorkerne zum Verarbeiten von iperf berechtigt sind. Hierbei zeigt sich, dass zunächst alle Cores iperf verarbeiten können.
Als nächstes wird iperf im Client-Modus mit der folgenden Anweisung vom Hostsystem verarbeitet. Hierbei versucht der Nutzer, Daten mit 1 GBit/s an den Server zu übertragen und wie zu sehen ist, kommt er dem Grenzwert tatsächlich sehr nah:
$> iperf -b1G -c 192.168.2.247 -p5001
[ 3] 0.0-10.0 sec 1.10 GBytes 851 Mbits/sec
Was wäre wohl passiert, wenn man Linux nicht die Erlaubnis gegeben hätte, den optimalen Prozessorkern zu wählen, sondern stattdessen das Verarbeiten des iperf-Servers fest an einen bestimmten Core gebunden hätte? Um die Folgen der Maßnahme auf den Datendurchsatz zu ermitteln, ist der Versuchsaufbau entsprechend abzuändern und der iperf-Server fest an CPU3 zu binden (wie erwähnt, ist CPU0 für das Bearbeiten von Interrupts des eth0-Interface zuständig). Hierzu ist der folgende Befehl in den Jetson Nano einzugeben:
$> taskset -p --cpu-list 3 12910
pid 20977's current affinity list: 0-3
pid 20977's new affinity list: 3
Bei einer erneuten Verarbeitung von iperf ergibt sich derselbe mittlere Durchsatz von 851 MBit/s. Eigentlich wäre zu vermuten, dass das Senden von Daten von CPU0 nach CPU3 zusätzliche Zeit beansprucht, was den Durchsatz entsprechend hätte verringern müssen. Mit Tracealyzer lässt sich feststellen, weshalb das nicht der Fall ist.
Hierfür ist zunächst ein lttng-Capture auf dem Jetson Nano zu starten:
$> lttng create
$> lttng enable-event -k -a
$> lttng enable-event -u --all
$> lttng add-context -k -t pid
$> lttng add-context -k -t ppid
$> lttng start
Daraufhin ist ein iperf-Test vom Hostsystem auszuführen, danach lttng zu stoppen und abschließend die lttng-Session per »destroy« zu löschen, um das Entstehen umfangreicher Traces mit unerheblichen Ereignissen zu vermeiden.
$> lttng stop
$> lttng destroy
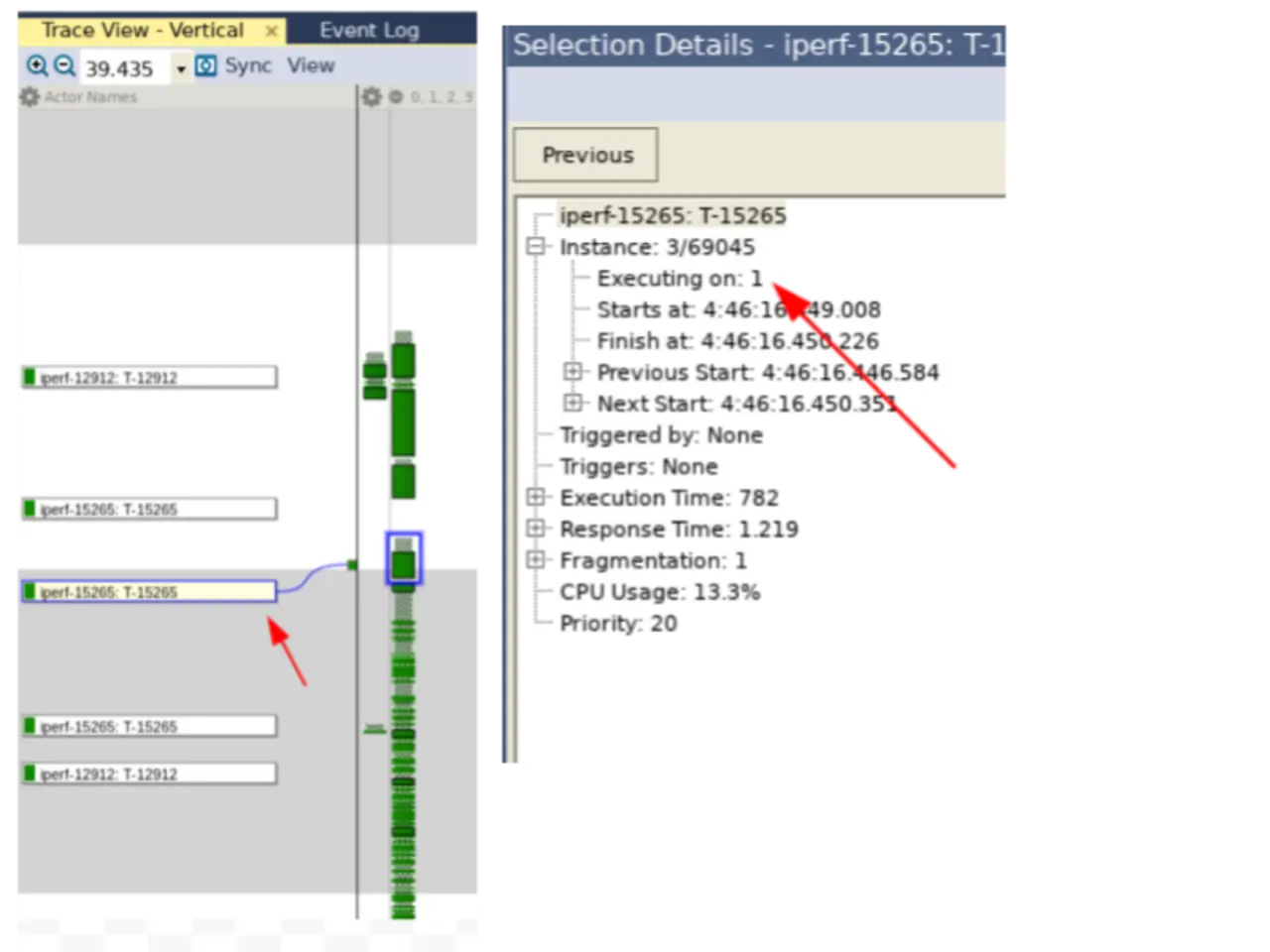
Zu sehen ist ferner (Bild 3), dass es trotz der Vorgabe, iperf an CPU3 zu binden, weitere Instanzen von iperf gab, die von anderen CPU-Kernen verarbeitet wurden.
Jobangebote+ passend zum Thema
- Embedded-Linux-Systeme tracen – Teil 3
- Belastung der CPU messen