Nach dem »Adler« nun der »Reiher«
ARMs Cortex-R5 und -R7 für Echtzeitanwendungen
Fortsetzung des Artikels von Teil 1
ARMs Cortex-R5 und -R7 für Echtzeitanwendungen
Beide Cores bieten jeweils 0 bis 128 Kbyte TCM für Befehle und Daten. Bit-Fehler werden sowohl in den TCMs als auch L1-Caches als auch auf beiden AXI-Bussen erkannt und korrigiert (beim Einsatz von ECCs). Ein wesentlicher Unterschied zum Cortex-R5 besteht darin, dass das Fehler-Handling beim R5 vollständig in Hardware abgebildet ist und beim R7 wesentlich durch Software konfigurierbar ist. Die Snoop-Control-Einheit (SCU) stellt wie beim R5 Kohärenz auch bei DMA-Datentransfer sicher, beim R7 allerdings auch zwischen den Cores (Bild 2).
Der Cortex-R5 weist eine 11-stufige, der R5 eine 8-stufige Pipeline auf (Bild 3). Die dritte zusätzliche Stufe zum Holen der Befehle ist beim R7 der höheren Taktfrequenz geschuldet, um dem L1-Cache genug Antwortzeit zu geben. Durch die Sprungvorhersage zu einem frühen Zeitpunkt in der Pipeline werden die negativen Auswirkungen bei einer fehlerhaften Vorhersage minimiert. Die Sprungvorhersage des R7 ist der des R5 in folgender Weise überlegen: Der Return-Stack besitzt 8 statt 4 Einträge. Der Global-History-Puffer (GHB), der für die vergangenen n Verzweigungen die Entscheidung "Verzweigung Ja/Nein" enthält, umfasst beim Cortex-R7 16 statt nur 4 Einträge wie beim R5. Die Global-History-Tabelle (GHT) mit 4096 Einträgen, welche die Entscheidungen für Verzweigungen in einem spezifischen Kontext enthält, wurde beim Cortex-R7 derart verbessert, dass eine Hash-Funktion zwischen GHB und aktuellem Programmzähler gebildet wird.Beim R5 wird der Kontext ausschließlich aus dem GHB entnommen. Beim R7 gibt es jetzt auch einen sogenannten Sprungadressen-Puffer mit 512 Einträgen, der die Art der Verzweigung und die Zieladressen enthält. Als Ergebnis dieser Maßnahmen erklärte ARM, dass die Sprungvorhersage beim Cortex-R7 unabhängig vom Code oder Benchmark immer besser funktioniert als beim R5.
Jobangebote+ passend zum Thema
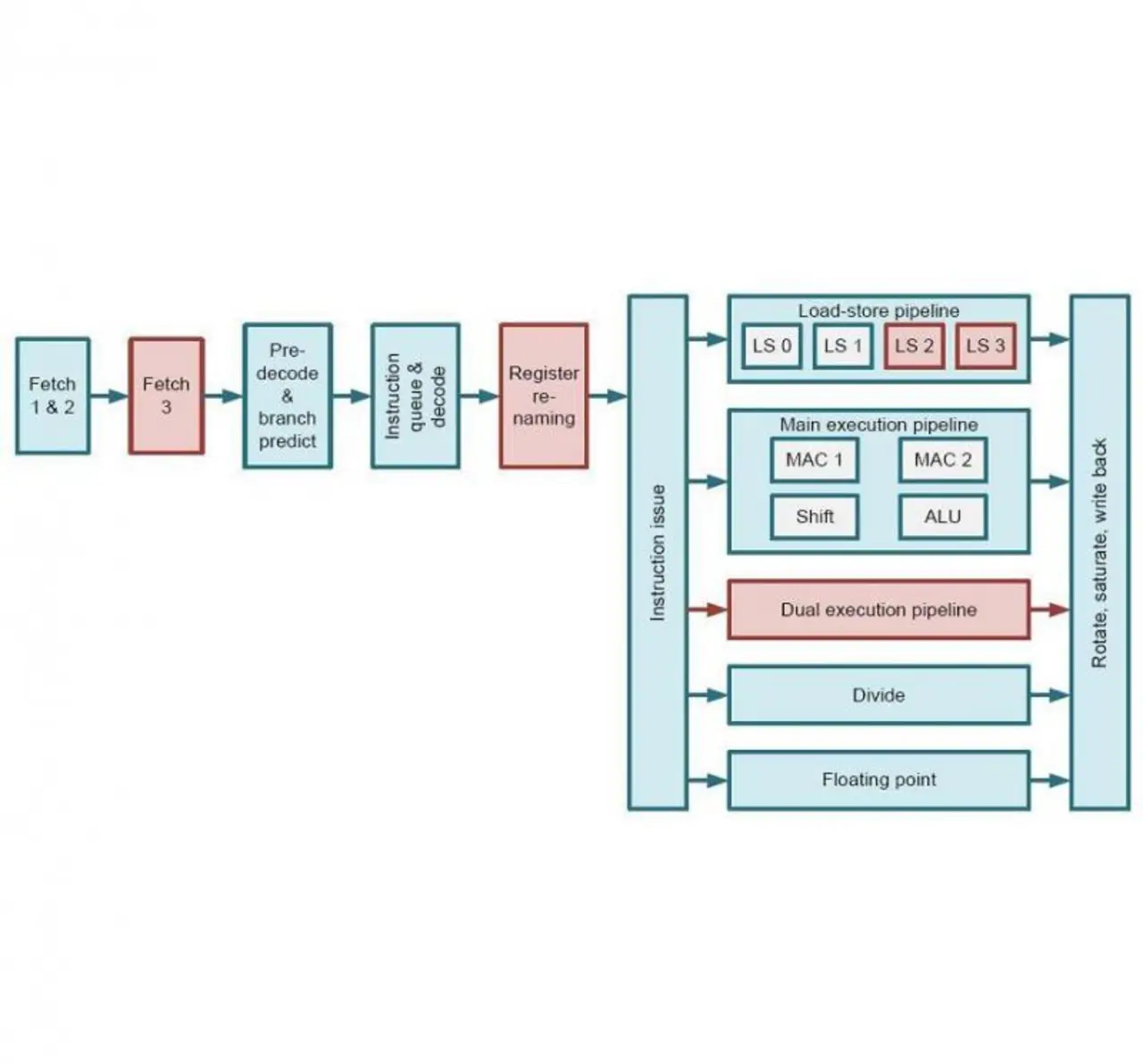
Der Cortex-R7 kann dank Out-of-Order-Befehlsausführung Befehle spekulativ umgeordnen und ausgeführen. Die Registerumbenennung ermöglicht aus Softwaresicht die Beibehaltung von 30 logischen Registern, während physikalisch 56 vorhanden sind. Mit bis zu 2 gleichzeitig abgearbeiteten Befehlen könnte die A7-Software theoretisch in einem Taktzyklus zweimal in dasselbe logische Register schreiben. Die Registerumbenennung ermöglicht es, dass die 2 Befehle bis zum Ende abgearbeitet werden (und die Hardware-Ressourcen für die nächste Instruktion frei gemacht werden) und ihre Ergebnisse gespeichert werden ohne sich gegenseitig zu überschreiben. Wenn einige dieser Befehle später verworfen werden, werden ihre Ergebnisse gelöscht, andernfalls werden diese den definierten Registern in der Reihenfolge des ursprünglichen Codes zugewiesen. Der Programmierer bekommt von alle dem nichts mit. Auch der Cortex-R5 kann ohne Out-of-Order zwei Befehle parallel ausführen. Wenn allerdings zwei Laden/Speichern-Befehle auftreten, können diese nicht parallel ausgeführt werden, da es nur eine Pipelline dafür gibt.
Wie in Bild 3 ersichtlich ist, gibt es eine Integer-Einheit für herkömmliche ARM-Anweisungen (R7: 2), eine für Gleitkomma-Anweisungen, eine für Lade/Speichern-Befehle und eine für Integer-Divisionen. Die Lade/Speichern-Pipeline arbeitet beim R7 auch nach dem Out-of-Order-Prinzip. Das Laden geschieht Out-of-Order, allerdings werden Daten nicht vor einem Speichern an derselben Adresse gelesen. Um die Datenintegrität sicherzustellen, erfolgen Schreibzugriffe in der Originalreihenfolge.
Interessant ist die Möglichkeit, einen Core auf Kosten der Rechenleistung für eine besonders schnelle Reaktion auf Interrupts zu konfigurieren. In einer Dual-Core-Konfiguration kann man das System sogar so einstellen, dass ein Core für eine maximale Rechenleistung „normal schnell“ auf Interrupts reagiert, während der andere besonders schnell reagiert.
Für die Zielanwendungen der neuen Cortex-R-Cores sind Mechanismen zur Abwendung von Fehlern besonders wichtig. Schon der Cortex-R5 erkennt und korrigiert Fehler von Daten, die fehlerkorrigierende Codes (ECC) enthalten, nicht nur in den L1-Speichern (Cache und TCM), sondern auch auf dem AMBA-AXI- und -AHB-Bus. In diesem Fall wird die Pipeline geleert, die Daten werden erneut geladen und die Ausführung wieder aufgenommen. Der R7 geht sogar noch weiter: Er legt erkannte Hard- oder Soft-Errors in einer Fehlerdatenbank ab, die für eine spätere Analyse ausgelesen werden kann.
Es wäre keine Überraschung, wenn ARM mit Cortex-R5/R7 weitere Marktanteile außerhalb des Handy-Geschäftes, das ja dank >90 % Marktanteil nur noch limitiertes Wachstumspotential bietet, gewinnen würde. Angeblich hat Texas Instruments bereits beide Cores lizensiert, um seine darauf basierenden Chips an Bosch zu verkaufen. Insbesondere der R7 bietet im Hinblick auf die verfügbare Rechenleistung noch soviel Luft nach oben, dass die Anforderungen der Industrie auch in 2-3 Jahren noch locker erfüllbar erscheinen.
| Leistungsmerkmal | Cortex-R5 | Cortex-R7 | Cortex-R5 Dual Core | Cortex-R7 Dual Core |
|---|---|---|---|---|
| Architektur | ARMv7 | ARMv7 | ARMv7 | ARMv7 |
| Max. Core-Taktfrequenz | 480 MHz | 600 MHz | 2 x 480 MHz | 2 x 600 MHz |
| bei IC-Prozess | 40 nm LP | 40 nm LP | 40 nm LP | 40 nm LP |
| Pipeline | 8 Stufen | 11 Stufen | 8 Stufen | 11 Stufen |
| Sprungvorhersage | Dynamisch | Dynamisch | Dynamisch | Dynamisch |
| Out-of-Order-Ausführung | Nein | Ja | Nein | Ja |
| Befehls-Länge | 32 bit | 32 bit | 32 bit | 32 bit |
| Kurz-Befehle | Thumb 2 | Thumb 2 | Thumb 2 | Thumb 2 |
| FPU | Ja SP/DP | Ja SP/DP | Ja SP/DP | Ja SP/DP |
| MPU (Regionen) | 12-16 | 12-16 | 12-16 | 12-16 |
| Befehls-Cache | 0-64 Kbyte | 0-64 Kbyte | 0-64 Kbyte | 0-64 Kbyte |
| Daten-Cache | 0-64 Kbyte | 0-64 Kbyte | 0-64 Kbyte | 0-64 Kbyte |
| TCM | 0-128 Kbyte (I/D) | 0-128 Kbyte (I/D) | 0.-128 Kbyte (I/D) | 0-128 Kbyte (I/D) |
| Bus-Schnittstelle | AMBA-3-AXI | 1 oder 2 AMBA-3 AXI | AMBA-3-AXI | 1 oder 2 AMBA-3-AXI |
| Siliziumfläche | 0,65 mm2* | 1,5 mm2** | 1,3 mm2* | 3 mm2** |
| Leistungsaufnahme | 0,15 mW/MHz | 0,23 mW/MHz | 0,3 mW/MHz | 0,46 mW/MHz |
| Dhrystone 2.1. | 1,66 DMIPS/MHz | 2,53 DMIPS/MHz | 3,32 DMIPS/MHz | 5,06 DMIPS/MHz |
| Erergieeffizienz | 11 DMIPS/mW | 11 DMIPS/mW | 11 DMIPS/mW | 11 DMIPS/mW |
| bei IC-Prozess | 40 nm LP | 40 nm LP | 40 nm LP | 40 nm LP |
| Einführung | Q1 2011 |
Q3 2011 |
Q1 2011 |
Q3 2011 |
Vergleich von Cortex-R5 und -R7. *: Konfiguration ohne FPU, 8 Kbyte L1-Cache, MPU, TCM-Ports, ACP LLPP. **: Konfiguration ohne FPU, 32 Kbyte L1-Cache, kein TCM, 64 Interrupts.
- ARMs Cortex-R5 und -R7 für Echtzeitanwendungen
- ARMs Cortex-R5 und -R7 für Echtzeitanwendungen
Lesen Sie mehr zum Thema
Das könnte Sie auch interessieren
