Sicherere Embedded-Systeme - Teil 1
Bessere Codequalität für sichere Systeme
Softwareentwickler für Embedded-Systeme treffen Entscheidungen, die enorme Auswirkungen auf die Codequalität haben. Mit ein paar praktischen Regeln zur Komplexität und der Wiederverwendbarkeit von Code lässt sich Software leichter pflegen und qualitativ hochwertiger auslegen – für sicherere Systeme.
Die Entwicklung einer Embedded-Software beginnt oft mit der Entscheidung, ob ein Betriebssystem verwendet werden soll oder nicht, und ob sie Echtzeitverhalten unterstützen soll. Bereits hier treffen Softwareentwickler Entscheidungen, die sich auf die Betriebs- und Datensicherheit (Safety & Security) des Produkts auswirken können, da solche Eigenschaften die Wahl des Echtzeitbetriebssystems beeinflussen. Diese Eigenschaften sollten zu den wichtigsten Anforderungen bei der Wahl des Betriebssystems gehören, auch wenn sie nicht Teil der bekannten Anforderungen sind. Berücksichtigen Entwickler die Sicherheitsmerkmale auch ohne die formalen Anforderungen für die Zertifizierung, können Embedded-Systeme allein durch diese Wahl sicherer werden. Es gibt einen Grund dafür, dass Linux-basierte Betriebssysteme viele Schwachstellen aufweisen, sicherheitsorientierte Betriebssysteme dagegen, wie Integrity von Green Hills Software, weisen nur sehr wenige oder gar keine Schwachstellen auf.
Hinzu kommt, dass ein Betriebssystem die Laufzeitumgebungen der gewünschten Programmiersprache unterstützen kann oder auch nicht, wobei einige Sprachen für sicherheitsrelevante Anwendungen besser geeignet sind als andere. Die Diskussion, welche Programmiersprache besser ist als die andere, kann ein langwieriges Thema sein und ist nicht Bestandteil dieses Beitrags.
Hinzu kommt, dass ein Betriebssystem die Laufzeitumgebungen der gewünschten Programmiersprache unterstützen kann oder auch nicht, wobei einige Sprachen für sicherheitsrelevante Anwendungen besser geeignet sind als andere. Die Diskussion, welche Programmiersprache besser ist als die andere, kann ein langwieriges Thema sein und ist nicht Bestandteil dieses Beitrags.
Traditionell wurden Embedded-Systeme hauptsächlich in C geschrieben, wobei C++ und verschiedene neuere Dialekte wie C++11 und C++14 immer häufiger zum Einsatz kommen. Basierend auf dem Betriebssystem, das unterschiedliche Laufzeitumgebungen unterstützt, gewinnen sogar höhere Sprachen wie Java, C#, Python oder Rust in Embedded-Systemen an Bedeutung und können eine gute Wahl für das Erstellen hochqualitativen Codes sein. In Bezug auf Sicherheit und Schutz gilt jedoch: Je komplexer der Software-Stack, desto höher das Risiko, unbekannte Faktoren einzuführen, welche die Robustheit dieser Systeme stark beeinträchtigen. Ist dies also der richtige Ansatz?
Moderne Embedded-Systeme können heute auch eine große Anzahl von Open-Source-Softwarebibliotheken wie Boost, TensorFlow, Eigen oder das gesamte Portfolio von Python-Bibliotheken verwenden. Dies basiert wiederum auf den Entscheidungen von Softwareentwicklern und dem Management, die eine Wiederverwendung von Software und kürzere Entwicklungszeiten anstreben, dabei aber das Risiko der Komplexität beim Erstellen sichererer Embedded-Systeme nicht berücksichtigen.
Was wäre, wenn man von diesen traditionellen Entscheidungen absehen und betrachten würde, wie man den Anwendungscode selbst erstellen – unabhängig davon, ob das System sicherheitszertifiziert sein soll oder nicht? Ließen sich zumindest solche eigenen Embedded-Anwendungen so gestalten, dass sie sicherer sind?
Die zyklomatische Komplexität
Der Nachteil bei der Auswahl von Programmier-Frameworks oder Betriebssystemen auf höherer Ebene besteht darin, dass die Komplexität der Systeme exponentiell zunimmt. So kann ein modernes Auto Hunderte von Millionen Codezeilen enthalten, die über viele verschiedene Embedded-Steuergeräte verteilt sind.
Daher ist das Minimieren der Komplexität in der Gesamtarchitektur ein wichtiger Faktor, der berücksichtigt werden muss – aber in diesem Bemühen muss auch der eigentliche Anwendungscode selbst minimiert und reduziert werden. Dieses Konzept wurde bereits 1976 von Thomas McCabe konzipiert, der das Konzept der zyklomatischen Komplexität als eine Softwaremetrik definierte, welche die Komplexität eines Programms oder Codeabschnitts angibt [1]. Sie ist definiert als die Anzahl linear unabhängiger Ausführungsmöglichkeiten innerhalb einer Funktion oder eines Codeblocks
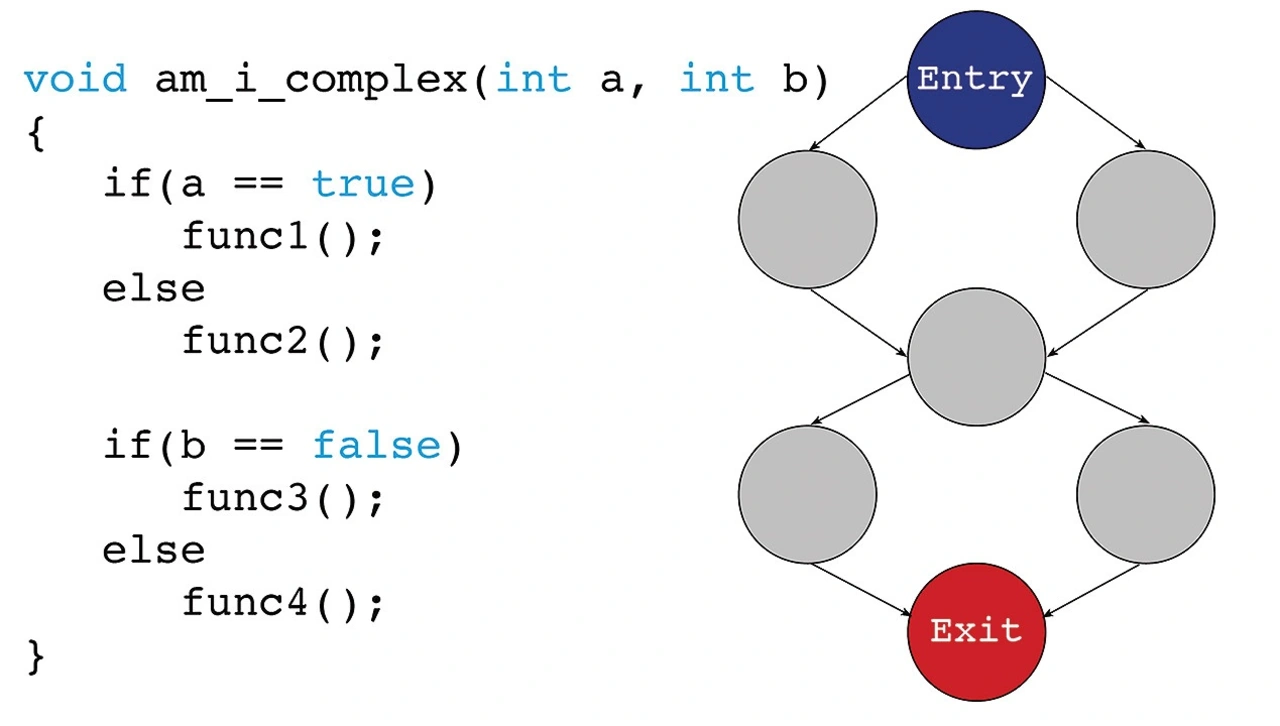
Zyklomatische Komplexität lässt sich leicht durch Graphen darstellen und damit interpretieren. Außerdem gibt es Analysetools, die diese Diagramme erstellen. Eine einfache Darstellung der zyklomatischen Komplexität einer bestimmten Funktion ist in Bild 1 dargestellt, die ein zyklomatisches Komplexitätsmaß von zwei aufweist.
Um geringere Softwarekomplexität als Anforderung festzulegen, wird entweder in der Spezifikation oder sogar in den Coding Guidelines eine Obergrenze für die zyklomatische Komplexität definiert, die von Fall zu Fall festgelegt wird. Entwickler sind bestrebt, die Codekomplexität zu minimieren und teilen dabei den Code in kleinere Funktionen oder Komponenten auf, um die gemessene zyklomatische Komplexität zu reduzieren. Das traditionelle Konzept besteht immer noch darin, alle diese Komponenten am Ende in dieselbe Anwendung zu bringen – aber das bedeutet auch, dass die Komponenten im selben Adressraum ausgeführt werden.
Architektur der Komponenten
Auch wenn die Codekomplexität verringert wurde, ist die Anwendungskomplexität nicht gesunken, da sie von mehreren Komponenten im selben Prozess oder Adressraum abhängt. Hier wird die Trennung von Komponenten interessant, wenn die Sicherheit zu berücksichtigen ist.
Sind Komponenten klar in separate Adressräume getrennt, haben sie eine geringere Wahrscheinlichkeit, dass sie sich gegenseitig negativ beeinflussen. Die Verwendung von Adressraumtrennung und -schutz, auch als Prozesstrennung bekannt, ist für die Komponentenisolierung von entscheidender Bedeutung. Der Kompromiss kann ein Kontextwechsel zwischen den ausgeführten Komponenten oder eine Ausführungszeit für die Datenübertragung sein – aber dies sind Überlegungen, die zum Erstellen daten- und betriebssicherer Codekomponenten mit geringerer Komplexität erforderlich sind.
Diese Grundlage kann auch die Basis für eine alternative Softwarearchitektur sein, die besser für robuste Embedded-Systeme geeignet ist. Sie wird bereits heute in MILS-Anwendungen (Multiple Independent Levels of Safety and Security) verwendet, um eine für Hochsicherheitssysteme geeignete Sicherheitsarchitektur bereitzustellen. Um den Trennungsschutz weiter zu unterstützen, können Betriebssysteme in Betracht gezogen werden, die eine absolute Prozesstrennung bereitstellen, z.B. Kernel mit echter Trennung.
Das PHASE-Konzept
Eine andere Sicht auf die Codekomplexität lässt sich aus dem PHASE-Konzept (Principles of High Assurance Software Engineering) von David und Mike Kleidermacher ableiten [2]. Sie behaupten, dass es nicht ausreicht, funktionale Anforderungen zu erfüllen, um die Sicherheit zu erreichen, die für kritische Embedded-Systeme erforderlich ist. Um die Sicherheit zu erhöhen, sollte eine fünfstufige Methodik befolgt werden, sodass die Sicherheit erhöht, Schwachstellen beseitigt und somit ein System mit höherer Zuverlässigkeit und Sicherheit geschaffen werden können.
Diese fünf Schritte zielen darauf ab, die Implementierung zu minimieren und eine komponentenbasierte Architektur zu erstellen, bei der für jede Komponente der Zugriff auf Ressourcen gemäß dem Prinzip der minimalen Rechtevergabe beschränkt ist. Sie zielen auch auf einen strengen Entwicklungsprozess ab, der durch externe Validierung erzwungen wird. Hier ist das Bestreben, Softwareanwendungen in Komponenten zu zerlegen, um die Komplexität zu verringern, eindeutig ein Faktor für die Schaffung von Softwaresystemen mit hoher Robustheit.
Das PHASE-Konzept geht auch bei der Komponententrennung noch einen Schritt weiter, indem es nur für ausgewählte Komponenten eine Stufe des Ressourcenschutzes hinzufügt. Anders gesagt: eine Komponente, die eine bestimmte Ressource benötigt, wie z.B. den Zugriff auf ein Netzwerk, sollte klar von einer Komponente getrennt werden, die Zugriff auf eine andere Ressource benötigt, z.B. ein Dateisystem.
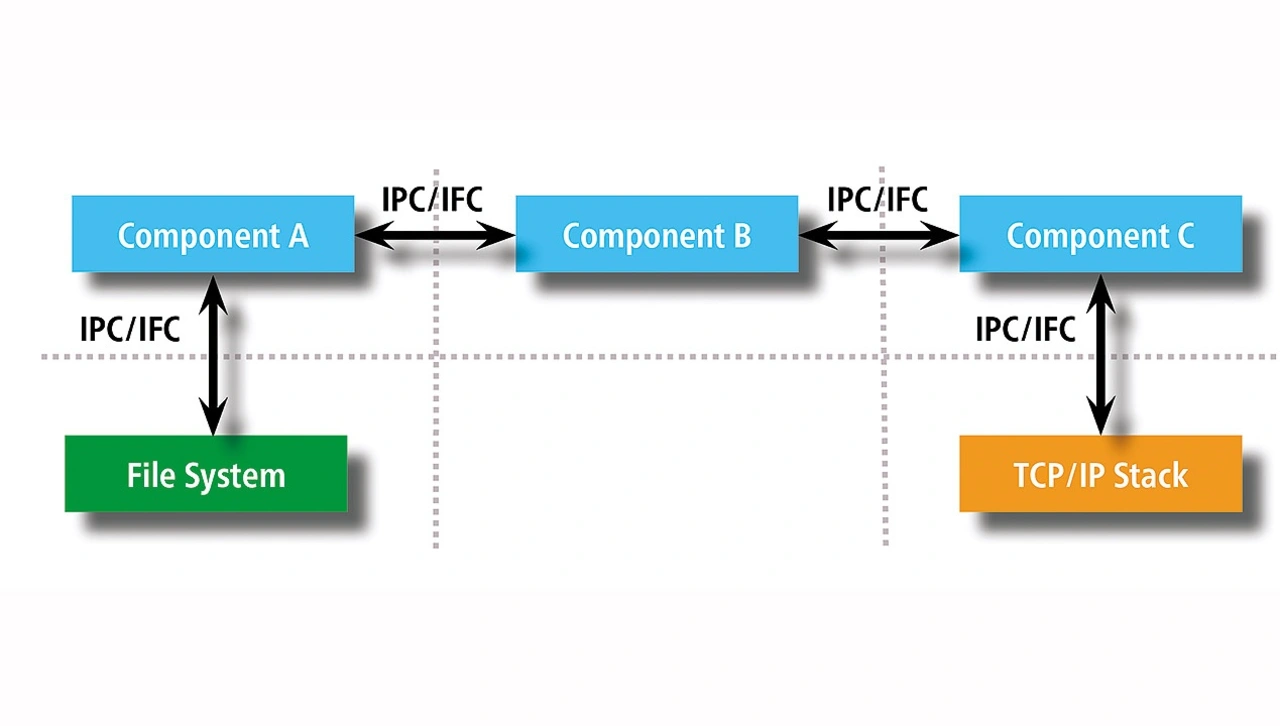
Natürlich würde das gesamte System aus mehreren Komponenten bestehen, die auf Kommunikationsmechanismen zwischen ihnen angewiesen sind, aber trotzdem wirken sich die Trennungs- und Ressourcenschutzmechanismen positiv auf die Sicherheit der Anwendung aus. Bild 2 beschreibt dazu klare Prozesstrennungsgrenzen und dedizierte Schnittstellen zwischen mehreren Komponenten, die eine vollständige Anwendung bilden.
Daher sollten Softwareentwickler eine minimale Implementierung einer auf mehreren Komponenten basierenden Softwarearchitektur mit definierten Schnittstellen anstreben, um sicherere Embedded-Systeme zu erstellen. Außerdem wären kleinere komponentenbasierte Implementierungen leichter zu warten und von weniger Entwicklern zu kontrollieren, sodass sogar ein einzelner Entwickler jeden Teil einer von ihm verwalteten Komponente kennen und verstehen kann.
Jobangebote+ passend zum Thema
- Bessere Codequalität für sichere Systeme
- Wiederverwendung von Komponenten