KI/ML-Prozessorarchitektur
Von 8 bis 1200 TOPS skalierbar
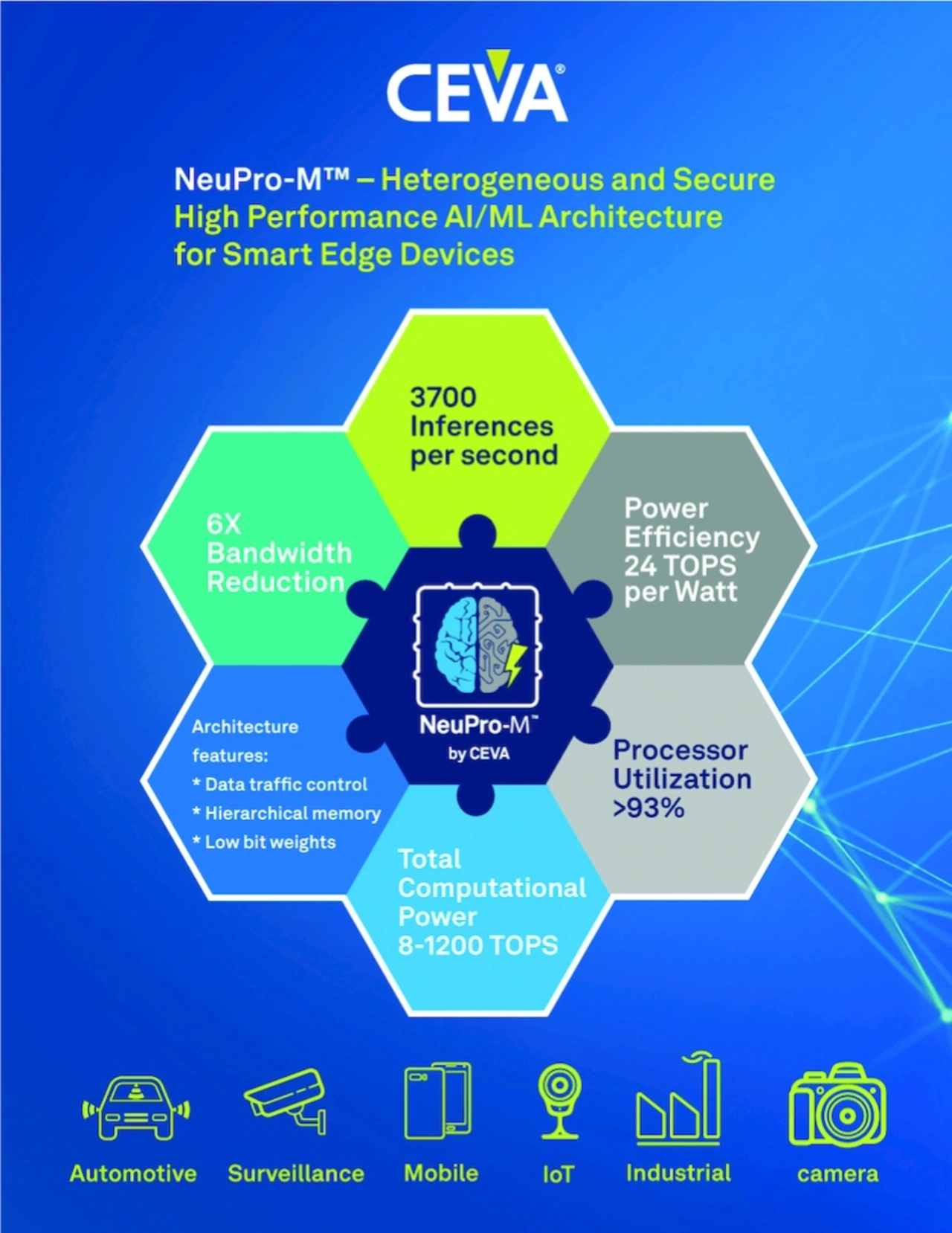
Mit »NeuPro-M« hat CEVA eine neue heterogene Prozessorarchitektur entwickelt, mit der das Unternehmen auf KI-/ML-Anwendungen im Edge abzielt. Damit sollen Anwendungen abgedeckt werden, die bis zu 1200 TOPS an Rechenleistung benötigen.
NeuPro-M ist die dritte Generation unserer NeuPro-AI-Architektur und zeichnet sich durch einen Leistungssprung gegenüber der Vorgängervariante, dem NeuPro-S aus dem Jahr 2019, aus«, erklärt Gil Abraham, Director of Business Development, AI & Computer Vision von Ceva. Und weiter: »Bei der Inferenzierung desselben neuronalen Netzes kommt NeuPro-M auf eine um den Faktor 10 höhere Leistung als unsere NeuPro-S-Cores, außerdem lassen sich die neuen IP-Cores über einen deutlich größeren Leistungsbereich skalieren, nämlich von 8 bis 1200 TOPS.« Denn die neue Prozessorarchitektur basiert auf verschiedenen Rechenkernen, die alle parallel arbeiten können. Darüber hinaus betont Abraham, dass NeuPro-M auch Security-Anforderungen genügt, denn der Zugriff auf Gewichte und Biases (Schwellwerte) ist geschützt.
Alle bisher bestehenden Limitierungen bei KI adressiert
Ceva hat NeuPro-M laut Abraham dahingehend optimiert, dass es die derzeit am häufigsten auftretenden Probleme von Entwicklern von KI-Anwendungen löst. Dazu zählt unter anderem der ständig steigende Bedarf an Rechenleistung, eine niedrige Leistungsaufnahme, minimale Latenzzeiten, Programmierbarkeit, Zukunftssicherheit der Designs, Security- und Safety-Anforderungen, aber auch eine zu geringe Verarbeitungseffizienz, Bandbreitenprobleme, geringe Ressourcen-Ausnutzung sowie eine mangelnde beziehungsweise schlecht funktionierende Toolchain.
All diese Punkte seien bei der Entwicklung von NeuPro-M berücksichtigt worden. Herausgekommen sei eine Prozessorarchitektur, die sich für eine Vielzahl von Zielmärkten eignet, angefangen bei der Automotive-Industrie über die Industrieelektronik bis hin zu 5G-Netzen und -Handys sowie Überwachungskameras.
Heterogene Architektur
Um diese hohe Rechenleistung zu erreichen, hat Ceva diverse Koprozessoren und Hardware-Beschleuniger in seine sogenannte NPM-Engine integriert, plus lokalen Speicher und Controller. Konkret sind in jeder NPM-Engine folgende Recheneinheiten implementiert:
- Ein 4K-MAC-Array (MAC: Multiplay And Accumulate), das unterschiedliche Datentypen erlaubt und sich laut Abraham durch eine minimale Leistungsaufnahme auszeichnet. Abraham: »Bei Daten und Gewichten mit niedriger Bitrate sinkt die Bandbreite sowie die Leistungsaufnahme, und die Rechnungen werden beschleunigt. Dank unseres Designs können die verschiedenen Layer eines CNN unterschiedliche Daten/Gewichte-Typen nutzen, ohne dabei die Genauigkeit des Gesamtsystems zu beeinträchtigen.«
- Eine Winograd Transform Engine (nach Shmuel Winograd) für eine hardwaremäßige Beschleunigung des Winograd-Algorithmus. Die Winograd-Transformation bietet einen effizienteren Weg, Faltungen zu berechnen, und kann 4, 8, 12 oder 16 bit verarbeiten. Laut Abraham sind mit Winograd nur die Hälfte an MAC-Operationen notwendig, was sich positiv auf die Leistungsaufnahme auswirkt. »Dabei sinkt die Genauigkeit nur minimal. Bei 8 bit sind es weniger als 0,5 Prozent.« Die Winograd-Faltung braucht außerdem kein Training. Abraham fügt noch hinzu: »Im Vergleich zu traditionellen Faltungsmethoden steigt mit der Winograd-Transformation die Rechenleistung beim ResNet50-CNN beispielsweise um 28 Prozent, bei YoloV3 sind es sogar 80 Prozent.«
- Eine Unstructured Sparsity Engine. Dieser Hardware-Block macht es möglich, dass Operationen mit nullwertigen Gewichten oder Aktivierungen auf jedem einzelnen Layer im Inferenzierungsprozess ausgeschlossen werden. Abraham: »Mit diesem Funktionsblock lässt sich die Rechenleistung um einen Faktor von bis zu 4 steigern; gleichzeitig sinkt die Leistungsaufnahme und die benötigte Bandbreite, ohne dass die Genauigkeit leidet.«
Die programmierbare Vector Processor Unit (VPU) ist ein vollständig programmierbarer Vektorprozessor, der ebenfalls alle Datentypen, von 32-bit-Gleitkomma bis hinunter zu BNN (Binary Neural Network), unterstützt. Laut Abraham braucht die VPU nur dann Energie, wenn sie auch arbeitet, hat aber einen entscheidenden Vorteil: »Die VPU kann für die Verarbeitung eines speziellen Layers oder aber auch für jede zukünftige Erweiterung für nicht unterstützte Layer und neue NN-Architekturen mit allen Datentypen genutzt werden. Damit werden die Designs zukunftssicher.« Wobei er betont, dass NeuPro-M heute alle NN-Architekturen unterstützt, einschließlich neuere Varianten wie FC-Netze (Fully-Connected), 3D-Convolution-Netze oder RNNs (rekurrente neuronale Netze).
Jobangebote+ passend zum Thema
- Von 8 bis 1200 TOPS skalierbar
- NeuPro-M unterstützt Secure Boot und schützt Gewichte und Daten vor Diebstahl