Sicherere Embedded-Systeme – Teil 2
Bessere Codequalität für sichere Systeme
Um sichere Embedded-Systeme zu entwickeln, sollten die Fähigkeiten und Einschränkungen der Programmiersprache beachtet werden. Mit einem definierten Prozess, Tools zur Codeanalyse und einer sinnvollen Codeoptimierung lassen sich durch Qualitätsmaßnahmen frühzeitig mögliche Probleme beseitigen.
Im ersten Teil des Beitrages [3] standen die Codekomplexität und Methoden zur Reduktion der Komplexität im Vordergrund, wie das PHASE-Konzept für sichere Embedded-Systeme [2]. Nun folgen die Betrachtung der Codeanalyse und ein Blick auf die Bedeutung der Programmiersprache bevor typische Programmiertechniken für sichere Embedded-Systeme vorgestellt werden.
Codierungsstandard als Richtlinie
Ist ein Checker für die Einhaltung eines Codierungsstandards ein Schritt auf dem Weg zu besserem Code, so gibt es noch weitere Checker-Tools: Diese können inline mit dem Compiler ausgeführt werden oder Teil der Infrastruktur sein, in der der Quellcode versioniert, getestet und analysiert wird. In der Regel handelt es sich dabei um statische Tools zur Codeanalyse, aber es gibt auch eine andere Kategorie von Analyse-Tools, die als dynamische Codeanalyse-Tools bezeichnet werden.
Statische Codeanalyse
Die statische Codeanalyse ist nützlich, um Probleme im Quellcode zu erkennen, die beim Kompilierungsschritt nicht erkannt werden. Sie kann nützlich sein, um allgemeine Probleme wie Ressourcenlecks oder Pufferüberläufe zu finden. Typische Tools für die statische Code-Analyse sind Coverity und Klocwork. Es gibt auch Open-Source-Versionen wie cppcheck.
Bei der statischen Codeanalyse wird der Code nicht ausgeführt, und es werden keine spezifischen Testfälle oder Eingabedaten benötigt. Daher ist es ein natürlicher und trivialer Schritt, der als eine Operation durchgeführt werden kann, die zu einem bestimmten Zeitpunkt über einen bestimmten Satz von Quelldateien läuft.

Je näher der Test am Zeitpunkt liegt, an dem der Code geschrieben wurde, desto besser ist die Rückmeldung, die der Programmierer auf mögliche Probleme des eigentlichen Codes erhält. Der Schritt der statischen Analyse als Teil des Compiler-Tools, wie die DoubleCheck-Funktion des Green Hills C/C++-Compilers, oder ein Versions-kontrollsystem als Backend, sind daher vorteilhaft für diejenigen, die nächtliche Prüfungen durchführen und anschließend einen Bericht erstellen. So meldet das DoubleCheck-Tool beim Kompilieren statische Codeanalysefehler (Bild 6).
Nicht alle Analyse-Tools arbeiten gleich, daher ist zu erwarten, dass einige Tools basierend auf demselben Typ von Eingaben unterschiedliche Ergebnisse liefern. Das Codeprojekt mit der besten Qualität sollte darauf abzielen, mindestens einen Typ von statischen Codeanalyse-Tools zu verwenden, obwohl es noch besser wäre, mehrere Analyse-Tools unterschiedlicher Typen zu integrieren, die verschiedene Sätze von Analysewissen abdecken.
Dynamische Codeanalyse
Die dynamische Codeanalyse ist eine oft übersehene Methode, um die Softwaresicherheit zu erhöhen. Sie funktioniert anders als die statische Analyse, da Code ausgeführt und über Testfälle mit Daten gefüttert wird. Daher müssen während der Ausführung spezielle Mittel zur Überwachung der Software eingeführt werden, um potenzielle Probleme mit dem Code zu erkennen. Hinsichtlich der Softwareanforderungen oder Sicherheitsstandards wird oft erwähnt, dass die Codeabdeckung mit dem Sicherheitsniveau zunimmt und selbst bei niedrigeren Niveaus bei 100 % liegen sollte. Obwohl die Codeabdeckung einer der wichtigen Punkte ist, ist dies bei Weitem nicht das Einzige, was es zu beachten gilt.
Ein trivialer Schritt der dynamischen Codeanalyse wäre das Ausführen eines leistungsstarken Debugging-Tools, um das Verhalten des Codes zu untersuchen. Dies erfordert erheblichen manuellen Aufwand – aber bei minimalen Komponenten ist es viel einfacher. Die nächste Stufe der dynamischen Code-Analyse wäre die Laufzeit-Fehlerprüfung, die u. a. Zuweisungs- oder Arraygrenzen, fehlende »case«-Anweisungen, Division durch Null und Dereferenzierung von Nullzeigern untersucht. Außerdem sind Stack-Overflow-, Memory-Leak- und Buffer-Overflow-Checks weitere typische Aktionen, die während dieses Analyseschritts durchgeführt werden können.
Nun mag der aufmerksame Leser denken, dass diese Dinge doch bereits mit den statischen Analyse-Tools überprüft wurden, aber tatsächlich gibt es viele verschiedene Formen dieser Fehler, und nicht alle können mit einer statischen Codeanalyse erfasst werden. Das Beseitigen des Buffer-Overflow-Risikos ist eine der wichtigsten Maßnahmen für sicheren Code, die Programmierer mit statischer als auch dynamischer Codeanalyse problemlos durchführen können.
Zum Glück verfügen viele Tools zur Softwareentwicklung heute bereits über integrierte Funktionen zur dynamischen Codeanalyse und können auf verschiedene Weise mit dem zu prüfenden Programm interagieren. So kann während der Kompilierung spezieller Code hinzugefügt werden, um den zu analysierenden Code zu instrumentieren, oder spezifischer Objektcode, der dasselbe tut, kann mit der ausführbaren Datei verknüpft werden.
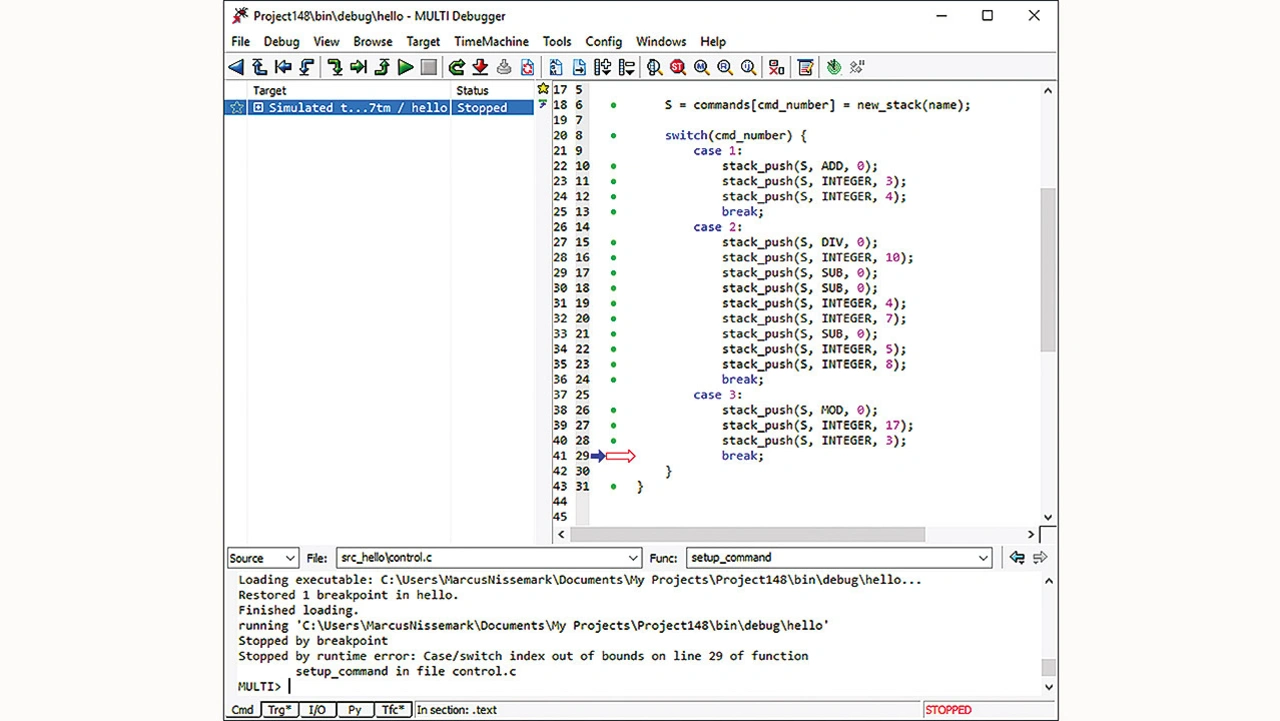
Es gibt auch die Möglichkeit, die Umgebung zu ändern, in der der Code ausgeführt wird, indem die Tests in einer Simulationsumgebung ausgeführt oder spezielle Systembibliotheken verwendet werden, die diese Laufzeitfehler erkennen können. Bild 7 zeigt das Fenster des Multi-Debuggers von Green Hills, der einen Laufzeitfehler einer Case-Anweisung in einer Simulation entdeckt, die Codezeile des Laufzeitfehlers deutlich markiert und eine Erklärung zum gefundenen Fehler ausgibt.
Eigenschaften von Programmiersprachen
Entwickler von Embedded-Software verwenden immer noch C als Hauptsprache, da sie gut geeignet und einfach zu verwenden ist, um Bits und Bytes beim Zugriff auf die Hardware zu manipulieren. C ist auch für Echtzeitsysteme geeignet, da modernere Funktionen wie die automatische Speicherbereinigung (Garbage Collection) fehlen. C++ wird wegen der objektorientierten Programmierung ebenfalls häufig verwendet, zumindest für die Programmierung von Embedded-Anwendungen.

Leider hat der C- und C++-Sprachstandard einige Vorbehalte, die Entwickler gerne vergessen. So gibt es das Konzept des undefinierten Verhaltens, d. h. dass sich einige Codekonstrukte anders verhalten können als erwartet. Ein Beispiel für undefiniertes Verhalten sind Speicherzugriffe außerhalb der Array-Grenzen (Bild 8).
Die erwartete Ausgabe des Programmbeispiels wäre ein Ausdruck der im Array indizierten Werte, aber der Wert von arr[10] könnten nicht initialisierte Daten, Null oder sogar Speicher sein, der dem ausführenden Programm nicht zur Verfügung steht. Somit würde nicht zugänglicher Speicher dereferenziert, was zu einem Fehler führt.
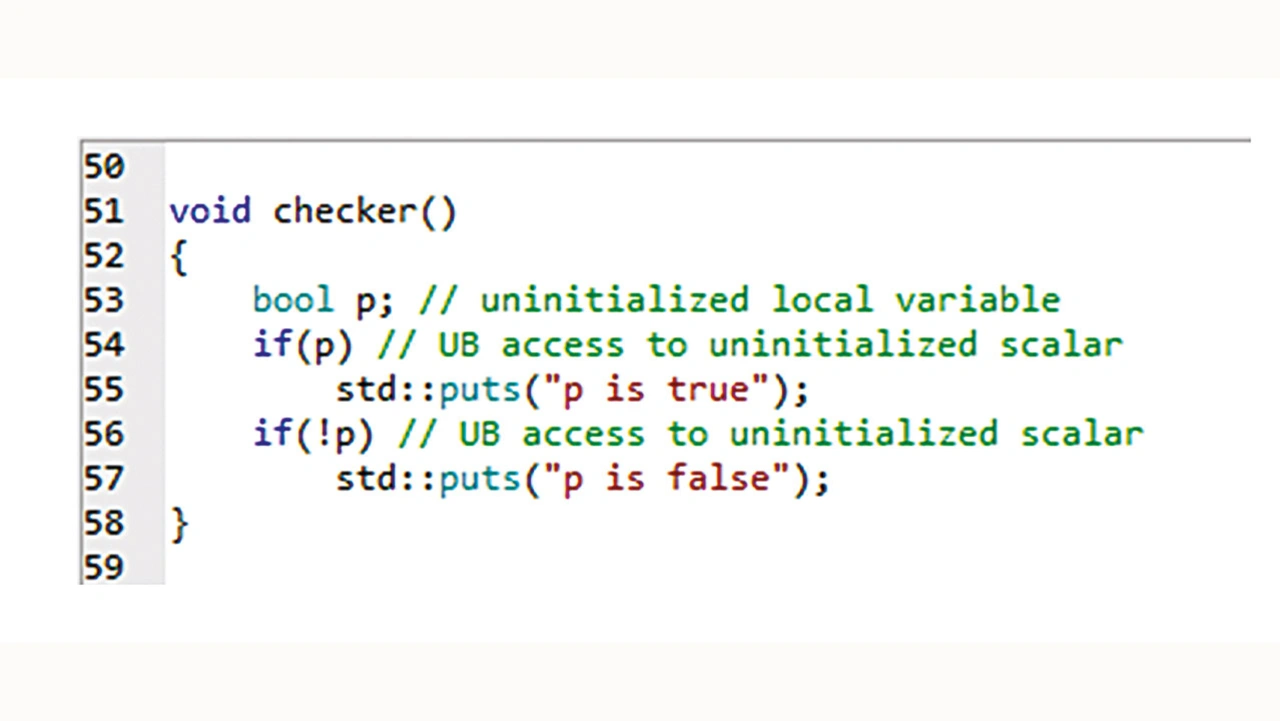
Ein weiteres Beispiel wäre die Verwendung nicht initialisierter Skalare (Bild 9). Die Ausgabe dieses Programms könnte eine der beiden Zeichenfolgen sein, da das Verhalten nicht definiert ist und von der Implementierung des Compilers abhängt.
Diese Programme aus den Bildern 8 und 9 sind einfache Beispiele für das undefinierte Verhalten von C- und C++-Code, aber sie zeigen, wie wichtig es ist, Programmierregeln zu befolgen und Codeanalysen durchzuführen, da solche leicht zu begehenden Fehler das beabsichtigte Verhalten eines Programms beeinflussen können.
Der Grund für das undefinierte Verhalten ist, dass es der Compiler-Implementierung überlassen bleibt, wie falsch geschriebener Code für diese undefinierten Abschnitte im Standard interpretiert werden soll. Daher kann sogar der Compiler selbst ein subtiles Verhalten einführen, das der Benutzer für eine Fehlfunktion hält, aber in Wirklichkeit ein einfacher Programmierfehler ist, der Softwareentwickler allerdings in die falsche Richtung führt. Der Compiler kann Annahmen treffen, und dies wird regelmäßig genutzt, um die Leistungsfähigkeit eines Compilers zu erhöhen – sowohl in Bezug auf die Kompilierzeit als auch auf den resultierenden Code, indem verschiedene Arten von Optimierungen vorgenommen werden.
Wird der Compiler aktualisiert oder geändert und der Code, der seit geraumer Zeit angewendet wird, neu erstellt, können plötzlich ein Compiler-Fehler, eine Warnung oder subtilere Änderungen im Laufzeitverhalten auftreten. Andere Sprachen bieten eventuell die Möglichkeit, solche Fehler besser zu erkennen, was typisch für modernere Sprachen wie Java ist. Dies ist auch einer der Gründe, warum ein Programmierer niemals Code vertrauen sollte, der neu erstellt wurde, ohne ihn zu testen.
Darüber hinaus haben sich die C- und C++-Standards weiterentwickelt: C11 verbesserte im Jahr 2011 die sehr häufig verwendete Version C99. In jüngerer Zeit wurde der C18-Standard angenommen, der einige der Mängel von C11 behebt, aber keine neuen Sprachfunktionen hinzufügt. C++ wurde in den letzten zehn Jahren ebenfalls einer größeren Überarbeitung unterzogen, beginnend mit C++11 im Jahr 2011, und einige Jahre später wurde mit C++14 ein korrigierendes Update hinzugefügt. Seitdem gab es immer wieder Updates mit dem Ziel, relevante Funktionen hinzuzufügen, aber auch einige der Mängel von undefiniertem Verhalten oder gefährliche Arten der Verwendung der Programmiersprachen zu beheben.

Ein weiterer Nachteil von C und C++ ist die fehlende Typsicherheit, d. h. es ist tatsächlich möglich, inkompatible Datentypen zu mischen, ohne dass der Compiler dies erkennt. In einigen Fällen ist dies sogar die beabsichtigte Funktion der Sprache. Dies hat sich in späteren Versionen der Sprachen verbessert, aber es gibt noch einiges zu beachten. So ist das Konzept der Integer-Promotion eine weniger bekannte Tatsache, die im Laufe der Zeit zu Problemen führen kann. Einige Datentypen wie »char« oder »short int« benötigen eine geringere Anzahl von Bytes als »int«. Diese Datentypen werden automatisch zu »int« oder »unsigned int« heraufgestuft, wenn eine Operation mit ihnen ausgeführt wird. Dies wird im Codebeispiel in Bild 10 veranschaulicht.
Auf den ersten Blick scheint die Berechnung (a × b)/c einen arithmetischen Überlauf zu verursachen, da vorzeichenbehaftete Variablen nur Werte von –128 bis 127 annehmen können und der Wert des Produkts (a × b) 1200 beträgt, was größer als 128 ist. Aber die Integer-Promotion findet hier in der Arithmetik statt, die mit char-Typen durchgeführt wird, und so erhält man das entsprechende Ergebnis ohne Überlauf. Dieses Beispiel wird keine Sicherheitsprobleme verursachen, aber es lohnt sich dennoch, es als Beispiel für die subtilen Merkmale von Programmiersprachen zu nennen, die Entwicklern möglicherweise weniger bekannt sind.
Jobangebote+ passend zum Thema
- Bessere Codequalität für sichere Systeme
- Sicherheit von Anfang an