Industrielle Instandhaltungsstrategien
Instandhaltung – aber wie?
Effiziente Instandhaltung ist ein wichtiger Aspekt einer ressourcenschonenden Industrie. Jede Sekunde, die eine Maschine arbeitet, anstatt gewartet oder instandgesetzt zu werden, vermeidet Verschwendung und generiert Mehrwert. Doch welche Vorgehensweise eignet sich für welche Art von Fehlerereignis?
Das Ziel einer geeigneten Instandhaltungsstrategie ist, ein Fehlerereignis vorhersagen zu können, um die Reparatur vor Eintritt des Ereignisses und damit vor einem Maschinenausfall durchzuführen. So ist es möglich, Stillstandzeiten einer Maschine zu planen, das notwendige Werkzeug und die Ersatzteile frühzeitig zu organisieren sowie das Personal rechtzeitig anzuweisen.
Warum aber setzt nicht jedes Unternehmen auf derartige Predictive Maintenance? Fehlerereignisse in hochkomplexen technischen Systemen sind leider nicht so vorhersagbar, wie wir es uns erhoffen; maximal eine von zehn potenziellen Fehlerursachen lässt sich gut bis sehr gut vorhersagen. Diese ist dann auch der perfekte Kandidat für Predictive Maintenance als Instandhaltungsstrategie. Alle anderen sind zu schwierig zu prognostizieren. Ein typisches Beispiel dafür ist der Leitungsfehler, eines der häufigsten Fehlerereignisse in hochvernetzten Systemen. Ursachen können unter anderem ein Kurzschluss, ein Bruch oder ein offener Stecker sein.
Diese Ursachen kündigen sich weder an noch sind sie anderweitig vorhersagbar. Sie sollen aber ebenfalls erkannt und behoben werden. Hierfür sind angepasste Instandhaltungsstrategien erforderlich.Welche Ereignisse in technischen Systemen sind gemeint?
Bei einem Ereignis wirkt eine definierte Fehlerursache und beeinflusst das technische System in seiner normalen Funktion. Um Fehlerursachen technischer Systeme besser zu verstehen, lassen sich die resultierenden Ereignisse grob in Kategorien mit gemeinsamen Eigenschaften einteilen (Bild 1).
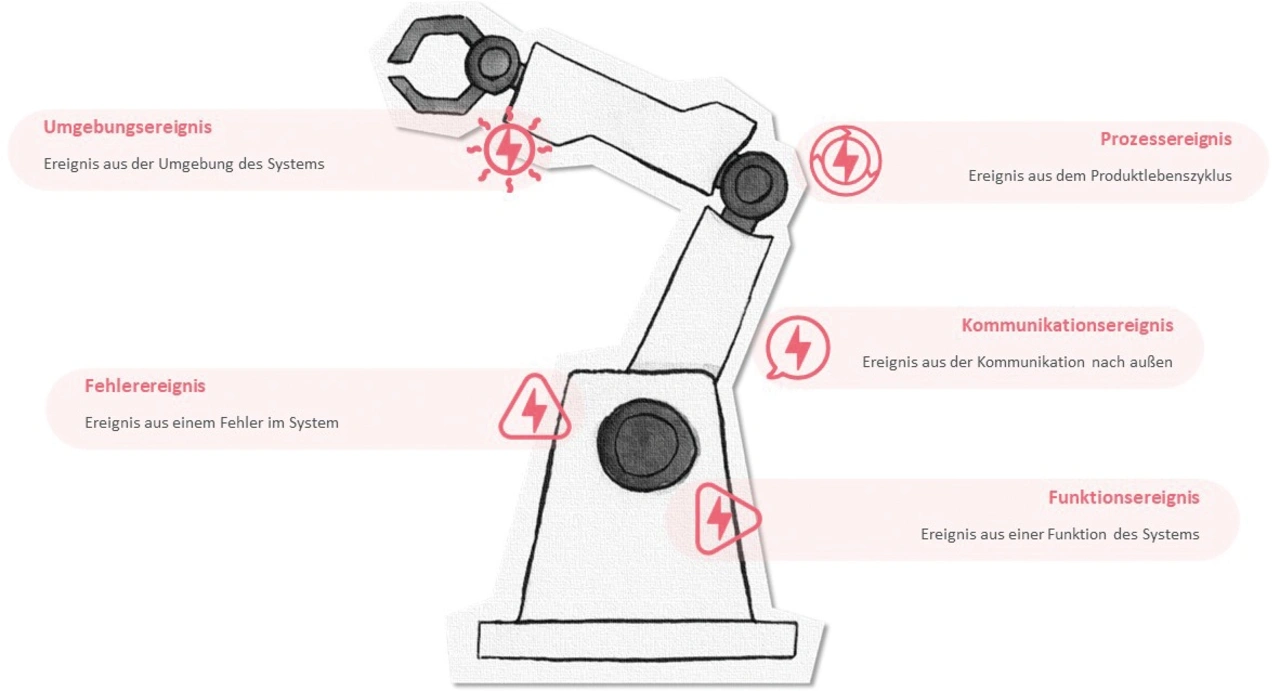
Umgebungsereignisse haben ihre Ursachen in der Umgebung um das technische System herum oder sogar in der Umwelt. Es sind meist Überschreitungen von Grenzwerten physikalischer Größen. Beispiele sind zu hohe Temperatur und Luftfeuchtigkeit, zu hoher Luftdruck oder zu viele Staubpartikel.
Prozessereignisse sind Fehler, deren Ursachen im Produktlebenszyklus oder in seiner konkreten Umsetzung liegen. Das können fehlende Einstellungen oder Programmierungen des technischen Systems sein, aber auch fehlende Arbeitsmittel oder falsche Reihenfolgen bei der Anwendung des Produktionsprozesses.
Fehlerereignisse werden durch Fehler im System verursacht. Darunter werden die klassischen Fehlerursachen verstanden. Defekte Steuergeräte, klemmende Aktoren oder Druckverlust sind Beispiele in dieser Kategorie.
Funktionsereignisse werden durch den Ablauf einer Funktion des technischen Systems verursacht und führen zu Funktionseinschränkungen. Aktivierung oder Deaktivierung spezieller Systemfunktionen, funktionale Sicherheitsmechanismen sowie Überschreitungen von Zählwerten, Regelgrenzen oder Ergebnissen von Systemberechnungen sind Beispiele für mögliche Ursachen von Funktionsereignissen.
Kommunikationsereignisse entstehen durch die Vernetzung mit anderen Systemen. Diese Ereignisse können auftreten durch Hinweise, Warnungen, Informationen oder Nachrichten von Geräten außerhalb des Systems. Aber auch externe Zugriffe und Interventionen durch Diagnosefunktionen werden hier zugeordnet. Beispiele sind falsche Freischaltcodes, Ereignismeldungen über das Internet oder die Durchführung eines Updates.
Jedes Ereignis in jeder der fünf Kategorien stört den normalen Funktionsablauf des technischen Systems. Wichtig für die Produktivität der betroffenen Maschine oder Anlage ist dann in jedem Fall eine schnelle und gezielte Beseitigung des Fehlers bzw. ein schnelles Reagieren auf das Ereignis.
Schon beim ersten Betrachten der einzelnen Kategorien fällt auf, dass es auf der einen Seite Fehlerursachen gibt, die mit etwas Erfahrung vorauszusagen sind – ein Beispiel dafür ist der klassische Verschleiß von Teilen. Auf der anderen Seite gibt es aber auch Fehlerursachen, die nicht vorauszusagen sind. Kommunikationsereignisse oder Prozessereignisse liegen meist außerhalb des betrachteten Systems und sind daher nicht voraussagbar.
Offensichtlich kann in den erläuterten Fällen also mit unterschiedlichen Instandhaltungsstrategien gearbeitet werden. Um herauszufinden, welche Instandhaltungsstrategie für welches Ereignis genutzt werden kann, muss man sich die einzelnen Ereignisse aber noch differenzierter ansehen.
Der Fingerabdruck technischer Ereignisse
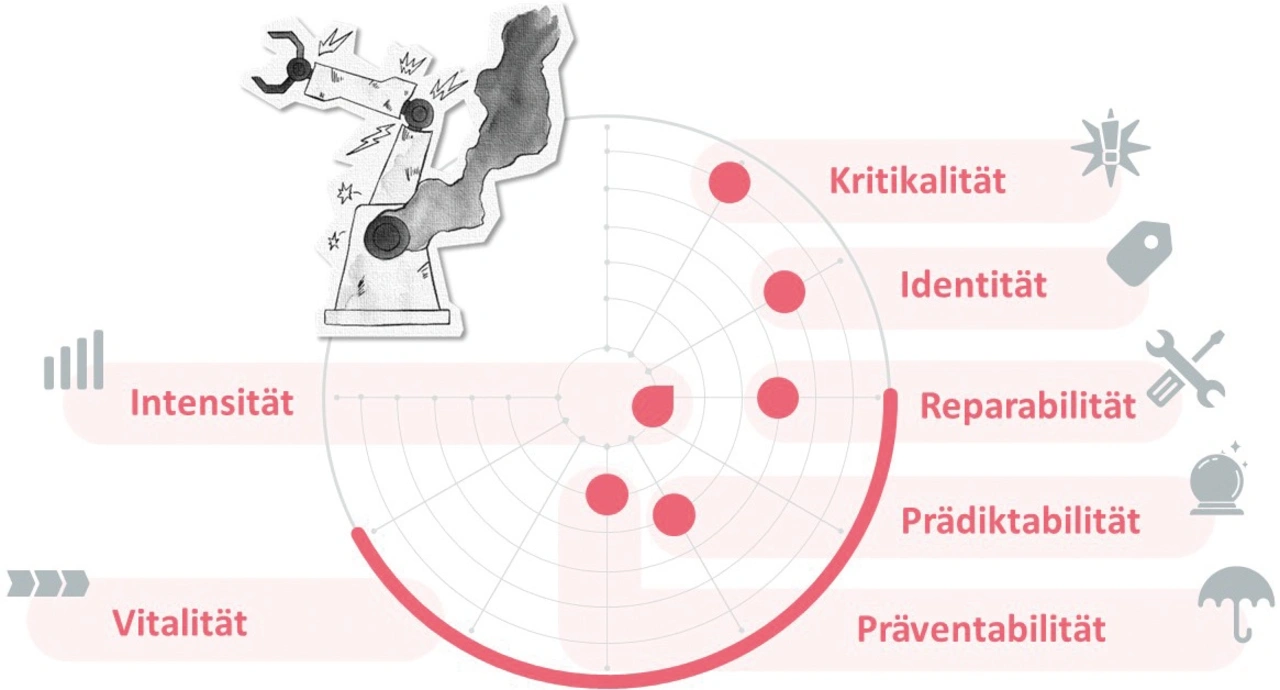
Analysiert man alle Ereignisse eines technischen Systems, so stellt man schnell fest, dass jedes Ereignis spezifische Merkmale und Eigenschaften hat. Diese lassen sich kategorisieren und messen; sie können als eine Art Fingerabdruck des Fehlerereignisses betrachtet werden. Im Folgenden werden beispielhaft Eigenschaften aufgeführt, wie sie seit Jahren in den Branchen Automotive und Maschinenbau verwendet werden. Diese Beispiele (Bild 2) haben keinen Anspruch auf Vollständigkeit; je nach Branche und System können mehr oder weniger Kriterien Berücksichtigung finden.
Die Kritikalität beschreibt die Schwere eines Ereignisses im Zusammenhang mit der Wahrscheinlichkeit oder Häufigkeit seines Auftretens. Je höher der Wert, desto wahrscheinlicher ist das Ereignis, desto schwerwiegender sind seine Auswirkungen und desto schneller wird die betroffene Funktion im System abgebrochen.
Die Identität beschreibt, wie gut Lokalisierung und eindeutige Identifizierung bei einem Ausfall oder Ereignis zu machen sind. Je höher der Wert, desto besser lässt sich das Ereignis entdecken und finden.
Die Reparabilität beschreibt die Wiederherstellbarkeit nach einem Ausfall oder Ereignis im Zusammenhang mit Aufwand, Kosten und Dauer für die Behebung. Je höher der Wert, desto leichter lässt sich ein Ereignis beheben.
Die Prädiktabilität beschreibt die Voraussagbarkeit eines Ereignisses im Zusammenhang mit seiner Ausfallmessbarkeit, dem Aufwand der Analyse und der Erkennbarkeit von Mustern. Je höher der Wert, desto besser lässt sich ein Ereignis voraussagen.

- Instandhaltung – aber wie?
- Verschiedene Strategien der Instandhaltung
- Die richtige Strategie am richtigen Ort