Datenflussbasierte Accelerator-Konzepte
Embedded KI-Beschleuniger effizient debuggen
Ein völlig neuartiges Debug- und Visualisierungskonzept von PLS ermöglicht Nutzern von Cross-Debuggern für eingebettete Systeme erstmals eine systematische Analyse, Validierung und Optimierung von KI-Algorithmen auf datenfluss-orientierten Beschleunigern in komplexen SoCs.
Aktuelle Systems-on-Chip im Automotive-Bereich bestehen typischerweise aus mehreren Hauptkernen, leistungsfähiger Peripherie und verschiedenen sogenannten Beschleuniger-Einheiten (Accelerators). Letztere sind darauf spezialisiert, bestimmte Algorithmen sehr schnell und effizient auszuführen, um so die Hauptkerne zu entlasten und die Leistungsfähigkeit des Gesamtsystems zu erhöhen. Die meisten solcher Beschleuniger basieren wie die Hauptkerne auf einer klassischen Mikrocontroller-Architektur. Mit einer Single-Instruction-Multiple-Data- (SIMD-)Erweiterung unterstützen sie typischerweise Rechenoperationen mit Vektoren.
Einen anderen Ansatz verfolgen datenflussbasierte Konzepte wie die vom Unternehmen Robert Bosch entwickelte Data Flow Architecture (DFA). Diese erlaubt datenflussbasierte Berechnungen direkt auf der Hardware. Sie besteht dazu aus sogenannten Basisblöcken für mathematische und Speicheroperationen. Typische Anwendungen sind beispielsweise Load/Store vom lokalen oder SoC-SRAM, Addition/Subtraktion, Multiply/Accumulate, Exponential-Funktion oder Cordic-Funktion für trigonometrische, logarithmische und andere komplexe mathematische Funktionen. Durch die Konfiguration einer Verbindungsmatrix können die Basisblöcke mit einer hohen Flexibilität für die unterschiedlichsten Algorithmen miteinander verbunden werden (Bild 1).
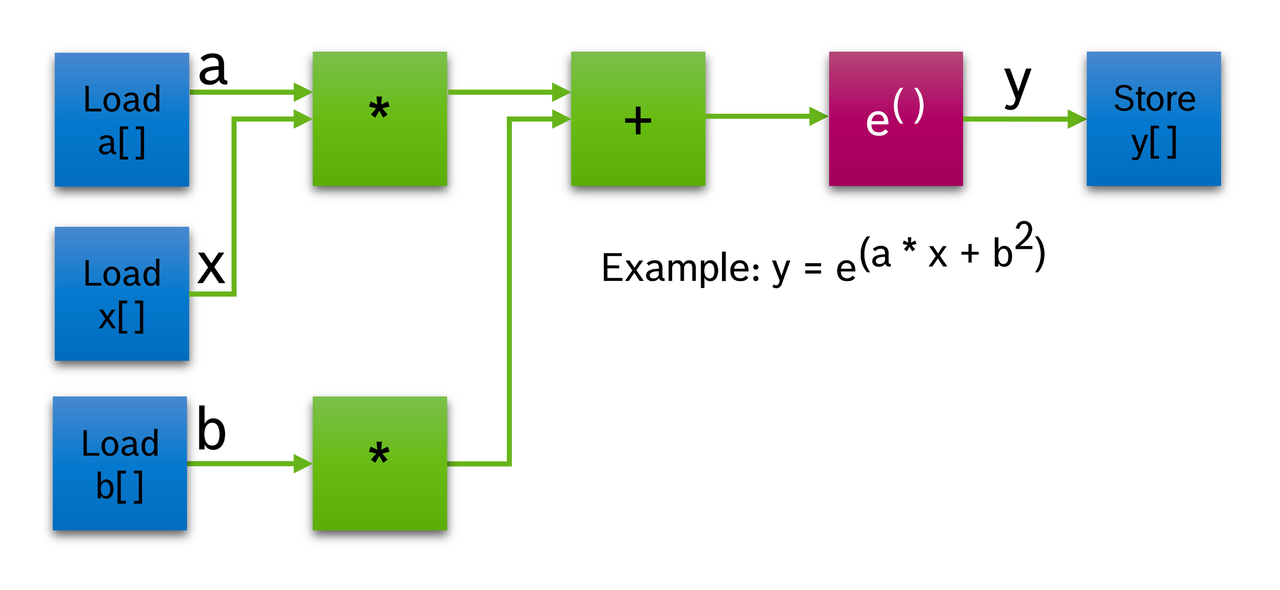
Bild 1. Realisierung einer mathematischen Formel durch eine Verbindung von Basisblöcken.
Aufgrund dieser hohen Flexibilität ist eine Nutzung der DFA für viele verschiedene Arten von Algorithmen denkbar. Neben Maschinellem Lernen und Künstlicher Intelligenz fallen auch Bereiche wie Signalverarbeitung, Regelungstheorie, mathematisch-physikalische Gleichungen und Kombinationen darunter.
Für das Debuggen der DFA stoßen jedoch die klassischen Konzepte an ihre Grenzen. Konventionelle Cross-Debugger basieren alle implizit auf einem sequentiellen Ausführungsmodell. Konzepte wie Befehlszähler, Haltepunkte und Aufrufstapel sind auf Controllerarchitekturen mit sequentieller Befehlsfolge zugeschnitten. Die DFA hingegen arbeitet als konfigurierbarer Datenflussprozessor. Algorithmen werden nicht als Instruktionsstrom, sondern als Graph aus Basisblöcken abgebildet, die datengetrieben und parallel arbeiten. Für den Anwender der DFA bedeutet dies, dass der Systemzustand nicht durch eine Programmadresse repräsentiert wird. Konfiguration, Zeit und Datenfluss müssen gemeinsam analysiert werden. Das Debugging verschiebt sich von der Anweisungs- zur Architektur- und Datenebene.
Eine in ein SoC integrierte DFA-Einheit ermöglicht der Zielsoftware ausschließlich schreibenden Zugriff auf ihre Basisblöcke. Für das Debugging gibt es aktuell einen dedizierten Zugang. Damit können alle Register der DFA transparent gelesen oder geschrieben werden, einschließlich solcher für spezielle Debugging-Funktionen. Die Register, die für den Anwender sichtbar sein müssen, stehen dabei sowohl in der Bedienoberfläche als auch für skriptgesteuerte Tests zur Verfügung.
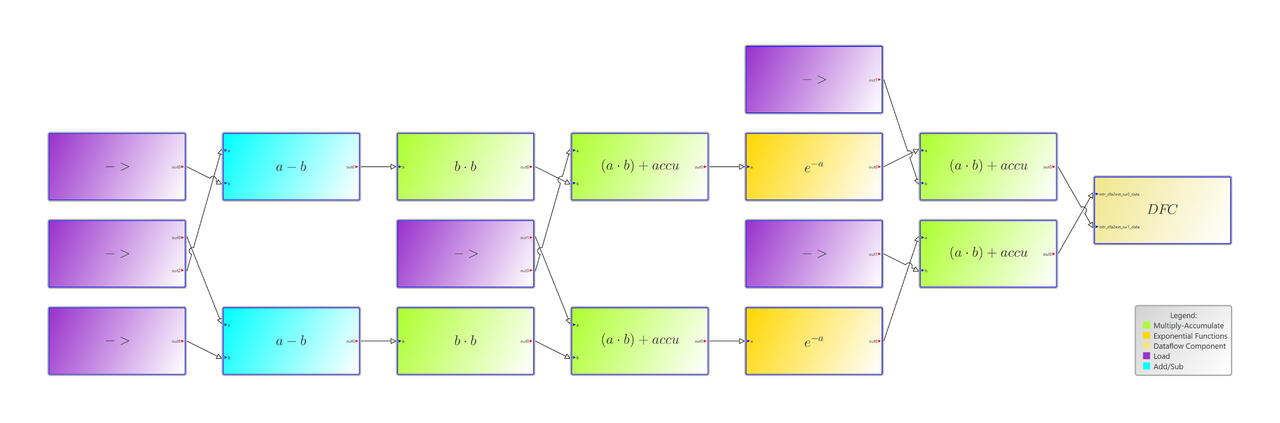
Bild 2. Grafische Darstellung eines konfigurierten DFA-Algorithmus
Für eine effektive Analyse von DFA-Konfigurationen ist eine Auflistung von mehreren hundert Registern als Name/Wert-Paar nur sehr bedingt geeignet. Für einen strukturierten Überblick bietet die UDE deshalb Entwicklern einige erweiterte Optionen. Diese basieren auf einer Hardwarebeschreibung des Herstellers, beispielsweise mit IP-XACT-Dateien. Damit lässt sich intern ein Modell der DFA generieren. Durch diese Re-Konfigurierbarkeit können auch zukünftige Generationen der DFA einfach unterstützt werden.
Darstellung in Übersichtstabelle
Mit Hilfe des generierten DFA-Modells kann die Konfiguration der DFA nun als erstes in einer Übersichtstabelle dargestellt werden. Dabei wird eine Sortierung nach Funktion der Basisblöcke vorgenommen. Die Übernahme der Namen und Typen von Blöcken, Registern und Feldern aus dem internen Modell garantiert dabei eine konsistente zweifelsfreie Benennung aller Elemente.
Die Erzeugung von GUI-Elementen erfolgt entsprechend den Spezifikationen des jeweiligen Feldes oder Registers automatisch. Um eine benutzerfreundliche Darstellung numerischer Werte zu ermöglichen, werden außerdem alle mit einem Feld verknüpfte Enumerationswerte angezeigt.
Hierarchische Baumansicht
Die DFA-Hardware verwendet ein internes Netzwerk, die Interconnect-Matrix, um den Ausgang eines Blocks mit dem Eingang eines anderen Blocks zu verbinden und so einen Datenflussgraphen zu erzeugen. Zur Konfiguration kommen dabei Register mit einer besonderen Funktion zum Einsatz, die Zieladress-Register »dest_addr_<n>« mit <n> als Ganzzahl. Diese Register definieren die verwendeten Verbindungen innerhalb der Interconnect-Matrix. In der Hardware realisiert ist dabei nur eine Teilmenge aller theoretisch möglichen Verbindungen. Dies bedeutet auch, dass die »dest_addr«-Register nur eine begrenzte Menge von Zieladressen enthalten dürfen.
Die UDE berechnet auf Basis der Interconnect-Matrix die gültigen Verbindungen und ermittelt für jedes »dest_addr«-Register die zulässigen Zielverbindungen als Enumerationswerte. So kann der Benutzer ein Ziel-Basismodul und Register direkt über eine Text-Darstellung anstelle eines numerischen Wertes als Ausgangsverbindung auswählen. Der resultierende Datenflussgraph kann in einer hierarchischen Baumansicht dargestellt werden, wobei die eingehende Verbindung eines Basisblocks den verbundenen Ausgangsblock als Unterelement anzeigt.
Die Wurzelknoten des Baums sind dabei die Blöcke, die keine weiteren ausgehenden Verbindungen besitzen. Der größte Vorteil dieser zweiten hierarchischen Konfigurations-Ansicht besteht in der Kombination der Blockverbindungen mit der Konfiguration der einzelnen Blöcke innerhalb einer Darstellung. Das bedeutet, dass sowohl strukturelle Informationen als auch Blockdetails gemeinsam angezeigt werden.
Die aktuelle Konfiguration der DFA kann in eine für den Menschen lesbare Konfigurationsdatei im XML-Format exportiert werden. Dabei wird eine Datei mit folgenden Inhalten erzeugt: ein Name für den Algorithmus, eine Identifikationszeichenfolge, welche die aktuell verwendete DFA-Architektur beschreibt, eine Sammlung aller Basisblöcke, die über die Interconnect-Matrix verbunden sind, sowie die Kennungen und Registerinhalte der ausgewählten Blöcke.
Nicht jedes Register wird in die Konfigurationsdatei geschrieben. Stattdessen nutzt die UDE die Interconnect-Informationen, um Basisblöcke zu ermitteln, die eine gültige Konfiguration aufweisen und Teil eines Netzwerks sind. Auf diese Weise wird nur die Konfiguration derjenigen Blöcke exportiert, die tatsächlich am aktuellen Algorithmus beteiligt sind. Die resultierende XML-Datei kann vom Benutzer eingesehen, bearbeitet und anschließend auch wieder eingelesen werden.
Grafische Darstellung des Datenflussgraphen
Die grafische Darstellung des Datenflussgraphen als dritte mögliche Ansicht ist diejenige mit dem höchsten Abstraktionsgrad (Bild 2). Der Graph besteht aus Knoten, welche die Basisblöcke der DFA darstellen, sowie aus Kanten zwischen den Blöcken, welche die Verbindungen vom Ausgang eines Blocks zum Eingang des nächsten Blocks repräsentieren. Alle Blöcke sind mit einer kompakten Darstellung ihrer Konfiguration beschriftet, die Verbindungspunkte der Kanten an den Blöcken mit den Namen der Ein- und Ausgänge versehen. Die Funktion eines Blocks wird entweder durch einen gebräuchlichen Namen wie beispielsweise »DFC« oder durch eine mathematisch/algorithmische Darstellung der Konfiguration beschrieben. Ein Layout-Algorithmus, der die Knoten und Kanten mit minimalen Überlappungen anordnet, sorgt für eine optimale Darstellung. Um das Layout individuell an die eigenen Anforderungen anzupassen, lassen sich die Blöcke vom Benutzer manuell verschieben.
Jedem Basisblocktyp ist eine eigene Farbe zugewiesen. Die Zuordnung der Farben zu den Blocktypen wird in einer Legende erläutert. Dies erleichtert es dem Benutzer, relevante Blöcke schneller zu erkennen. Die Konfiguration von Basisblöcken mit arithmetischen Operationen wie zum Beispiel MAC, AddSub, Cordic, Exp ist in der Regel über mehrere Register verteilt. Diese Konfiguration umfasst die Auswahl der Eingangsquellen (Ports und/oder Akkumulator), die mathematische Operation sowie eine Loop-Ebene. Der Debugger der UDE wertet den Registerinhalt aus und berechnet daraus einen mathematischen Ausdruck, der als Beschriftung des Blocks angezeigt wird (Bild 3).
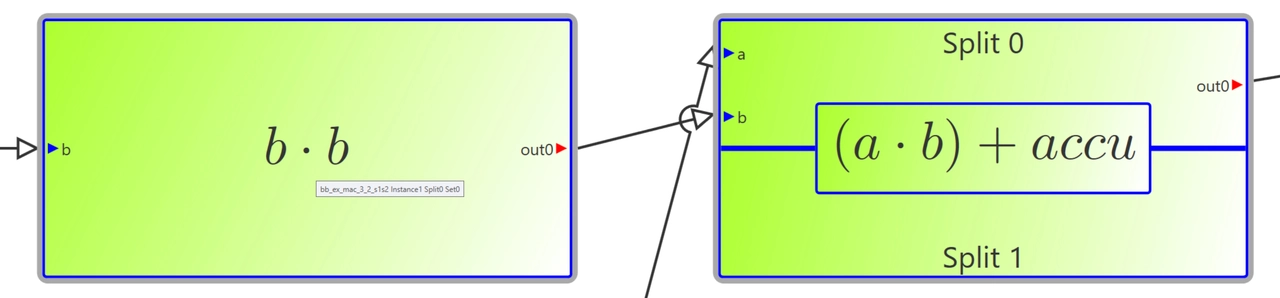
Bild 3. Detaildarstellung der Basisblöcke.
Die DFA unterstützt die Kombination von Blöcken mit unterschiedlichen »Splits« zu einem kombinierten Block, um Berechnungen mit 64-Bit-Datentypen durchzuführen – im Gegensatz zu den standardmäßigen 32-Bit-Datentypen im Normalbetrieb. Der Debugger unterstützt diese Funktion, indem er die verschiedenen Blöcke zu einem Block zusammenfasst und diesen in zwei Bereiche unterteilt darstellt, um die »Combined«-Eigenschaft zu visualisieren. Die einzelnen Teile sind mit dem jeweiligen Split-Namen beschriftet, um eine weitere visuelle Unterscheidung der beteiligten Blöcke zu ermöglichen (Bild 3).
Alle Blöcke verfügen über mehrere Eingangs- und Ausgangsports. Da die meisten davon ungenutzt sind, bringt der Algorithmus nur die tatsächlich verwendeten Ports zur Anzeige. Sämtliche erkannten Verbindungen werden überprüft und als verwendet registriert. Die Darstellung der Blöcke erfolgt mittels einer Liste an der linken Seite (Eingänge) und einer an der rechten Seite (Ausgänge). Die Verbindungen zwischen den Ports werden so geroutet, dass möglichst wenige Kreuzungen entstehen.

Bild 4. Toolbar zur Steuerung eines SoC mit Core00 und einer DFA.
Die DFA als gleichberechtigte Debug-Domäne
Zur Integration in die Universal Debug Engine (UDE) von PLS wurde die DFA als eigenständige gleichberechtigte Debug-Domäne neben den klassischen Mikrocontroller-Kernen behandelt. Die DFA-Konfiguration ersetzt dabei sozusagen den Binärcode. Da die DFA über keine zentrale Start-/Stopp-Möglichkeit verfügt, mussten andere Lösungen gefunden werden. Zwei Mechanismen ermöglichen eine Art Ausführungs-Steuerung. Die Load/Store-Basisblöcke benötigen ein Trigger-Signal, um aktiv zu werden. Dies erlaubt einen definierten Start eines vorkonfigurierten Algorithmus. Ein asynchrones Anhalten ist durch das Versetzen der DFA in den Debugging-Modus möglich. Darüber hinaus ermöglicht ein Schrittzählermechanismus die Ausführung von 1 bis n Taktzyklen. Für den Anwender entsteht damit ein funktionales Äquivalent zu »Run«, »Halt« und »Step« – angepasst an eine hochparallele Architektur (Bild 4).
Durch Einbindung der DFA in das Konzept der Run-Control-Gruppe der UDE ist beim Debuggen auch synchrones Starten und Stoppen der Haupt-Kerne und der DFA innerhalb eines SoC möglich.
Bei der inzwischen bereits von mehreren Halbleiterherstellern in reale SoCs integrierten Data-Flow-Architektur (DFA) handelt es sich um eine hochinnovative Beschleuniger-Hardware, die sich durch hohe Geschwindigkeit, geringe Chipfläche und niedrige Leistungsaufnahme auszeichnet. Aktuell steht für die Konfiguration eine Algorithmen-Bibliothek in der Programmiersprache C zur Verfügung, Werkzeuge für die Übersetzung von zum Beispiel Matlab-Code in eine DFA-Konfiguration sollen in naher Zukunft folgen.
Die UDE von PLS bietet darüber hinaus erstmals die Möglichkeit, unterschiedliche Domänen wie Mikrocontroller-Kerne mit sequentieller Befehlsabarbeitung zusammen mit der hochparallelen Beschleuniger-Hardware DFA in einer konsistenten Bedienoberfläche zu debuggen und zu testen.
Der Autor

Heiko Rießland, PLS.
Heiko Rießland
war nach dem erfolgreichen Abschluss seines Informationstechnik-Studiums an der Technischen Universität Dresden in verschiedenen Positionen für PLS Programmierbare Logik & Systeme tätig. Seit 2016 leitet er die Softwareentwicklung des Unternehmens .
